Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Matching Technique in Example-Based Machine Translation
Paper and Code
Aug 10, 1995
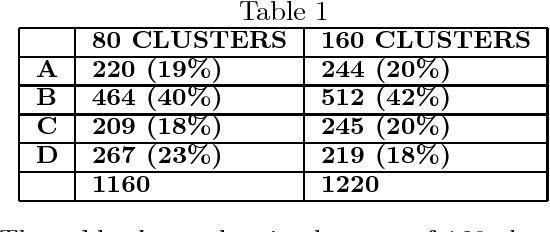
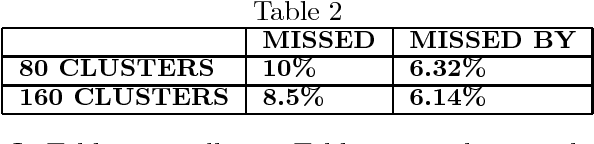
This paper addresses an important problem in Example-Based Machine Translation (EBMT), namely how to measure similarity between a sentence fragment and a set of stored examples. A new method is proposed that measures similarity according to both surface structure and content. A second contribution is the use of clustering to make retrieval of the best matching example from the database more efficient. Results on a large number of test cases from the CELEX database are presented.
* 5 pages,LaTeX uses aclap.sty
View paper on