 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-length entropies and correlations of natural language written texts
Jan 24, 2014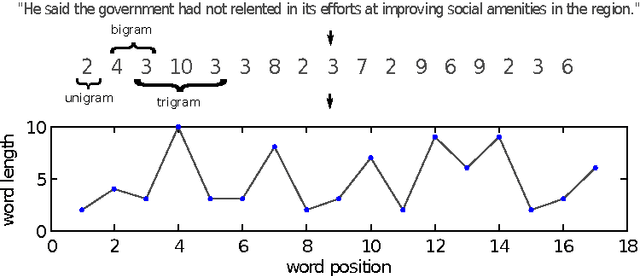

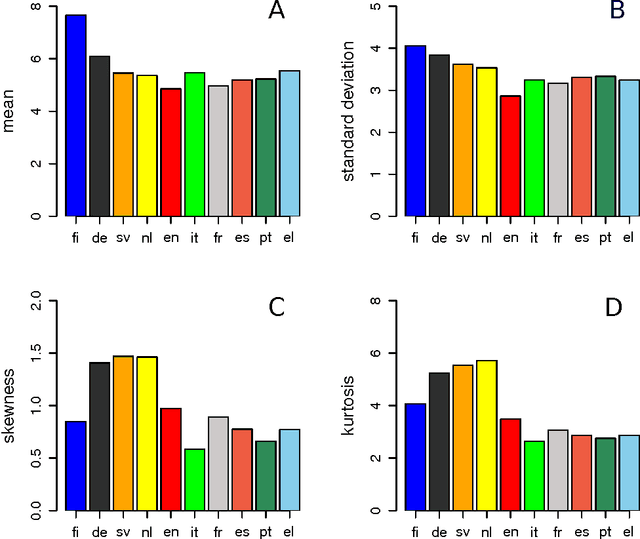

We study the frequency distributions and correlations of the word lengths of ten European languages. Our findings indicate that a) the word-length distribution of short words quantified by the mean value and the entropy distinguishes the Uralic (Finnish) corpus from the others, b) the tails at long words, manifested in the high-order moments of the distributions, differentiate the Germanic languages (except for English) from the Romanic languages and Greek and c) the correlations between nearby word lengths measured by the comparison of the real entropies with those of the shuffled texts are found to be smaller in the case of Germanic and Finnish languages.
A Matching Technique in Example-Based Machine Translation
Aug 10, 1995
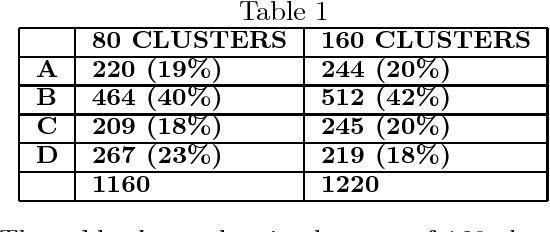
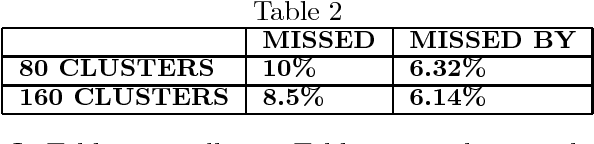
This paper addresses an important problem in Example-Based Machine Translation (EBMT), namely how to measure similarity between a sentence fragment and a set of stored examples. A new method is proposed that measures similarity according to both surface structure and content. A second contribution is the use of clustering to make retrieval of the best matching example from the database more efficient. Results on a large number of test cases from the CELEX database are presented.