 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining CNN Classifiers for Semantic Segmentation using Partially Annotated Images: with Application on Human Thigh and Calf MRI
Aug 16, 2020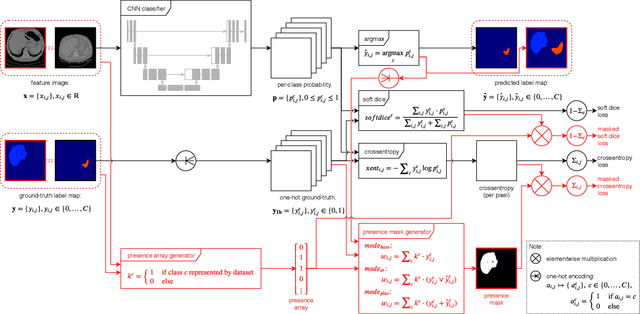
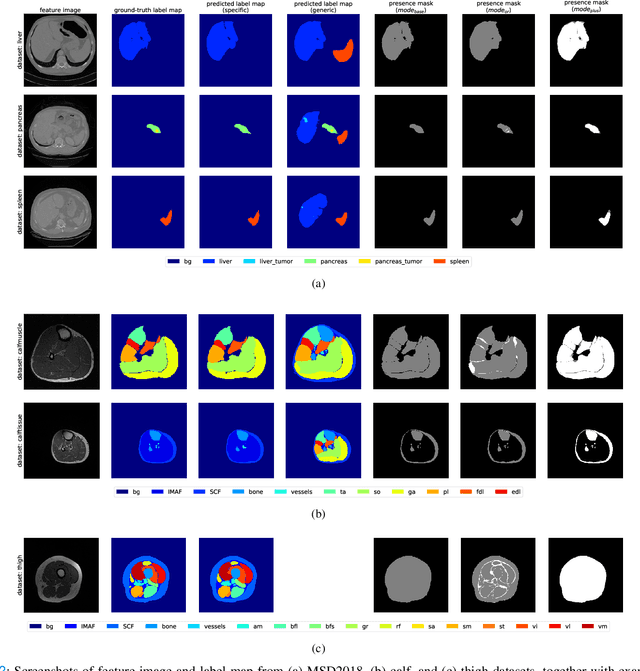
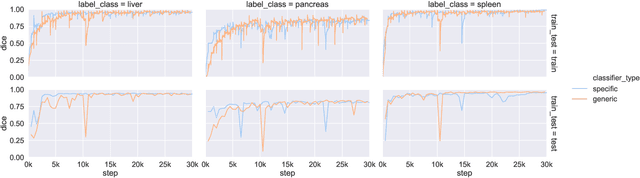
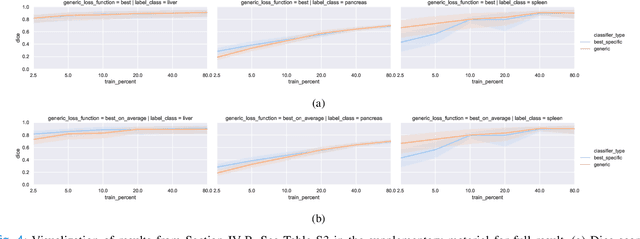
Objective: Medical image datasets with pixel-level labels tend to have a limited number of organ or tissue label classes annotated, even when the images have wide anatomical coverage. With supervised learning, multiple classifiers are usually needed given these partially annotated datasets. In this work, we propose a set of strategies to train one single classifier in segmenting all label classes that are heterogeneously annotated across multiple datasets without moving into semi-supervised learning. Methods: Masks were first created from each label image through a process we termed presence masking. Three presence masking modes were evaluated, differing mainly in weightage assigned to the annotated and unannotated classes. These masks were then applied to the loss function during training to remove the influence of unannotated classes. Results: Evaluation against publicly available CT datasets shows that presence masking is a viable method for training class-generic classifiers. Our class-generic classifier can perform as well as multiple class-specific classifiers combined, while the training duration is similar to that required for one class-specific classifier. Furthermore, the class-generic classifier can outperform the class-specific classifiers when trained on smaller datasets. Finally, consistent results are observed from evaluations against human thigh and calf MRI datasets collected in-house. Conclusion: The evaluation outcomes show that presence masking is capable of significantly improving both training and inference efficiency across imaging modalities and anatomical regions. Improved performance may even be observed on small datasets. Significance: Presence masking strategies can reduce the computational resources and costs involved in manual medical image annotations. All codes are publicly available at https://github.com/wong-ck/DeepSegment.
Word-length entropies and correlations of natural language written texts
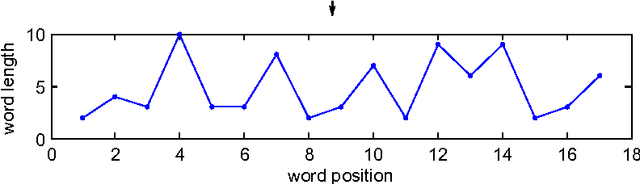
Jan 24, 2014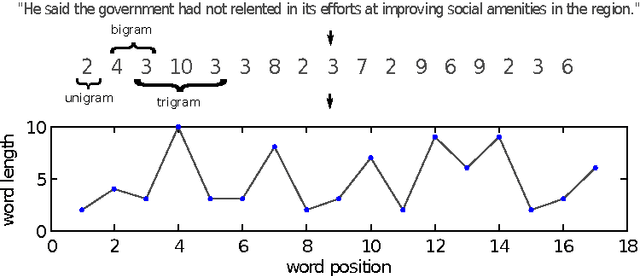

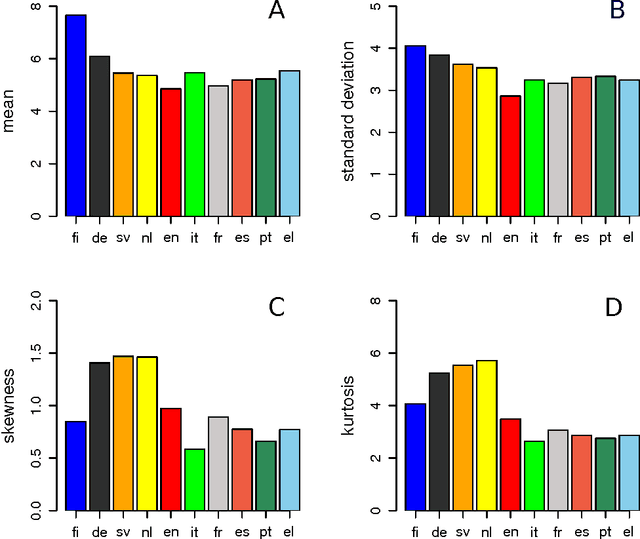

We study the frequency distributions and correlations of the word lengths of ten European languages. Our findings indicate that a) the word-length distribution of short words quantified by the mean value and the entropy distinguishes the Uralic (Finnish) corpus from the others, b) the tails at long words, manifested in the high-order moments of the distributions, differentiate the Germanic languages (except for English) from the Romanic languages and Greek and c) the correlations between nearby word lengths measured by the comparison of the real entropies with those of the shuffled texts are found to be smaller in the case of Germanic and Finnish languages.
Entropy analysis of word-length series of natural language texts: Effects of text language and genre
Jan 17, 2014
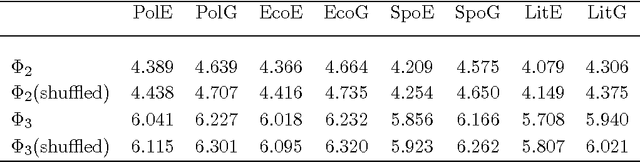
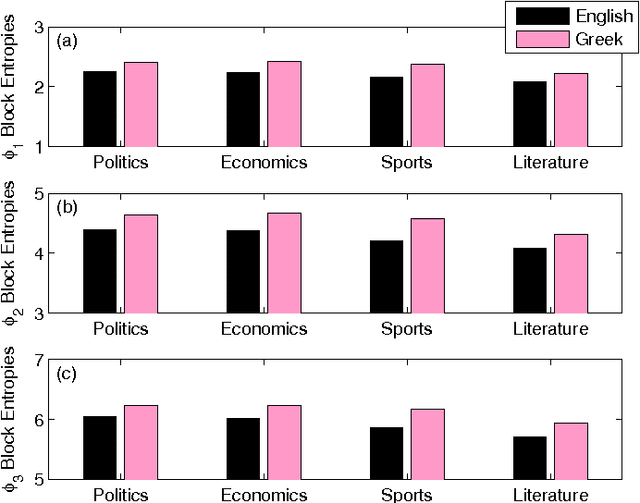
We estimate the $n$-gram entropies of natural language texts in word-length representation and find that these are sensitive to text language and genre. We attribute this sensitivity to changes in the probability distribution of the lengths of single words and emphasize the crucial role of the uniformity of probabilities of having words with length between five and ten. Furthermore, comparison with the entropies of shuffled data reveals the impact of word length correlations on the estimated $n$-gram entropies.
* 9 pages, 7 figures