 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022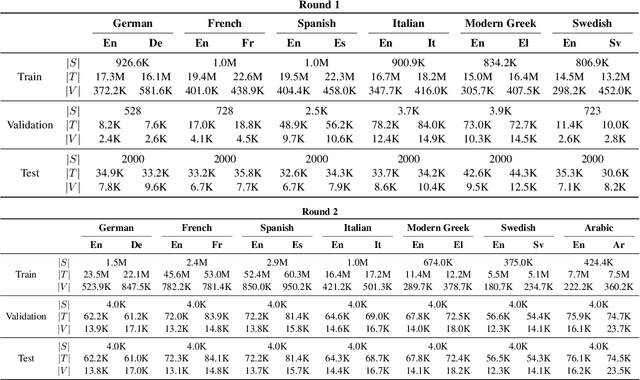
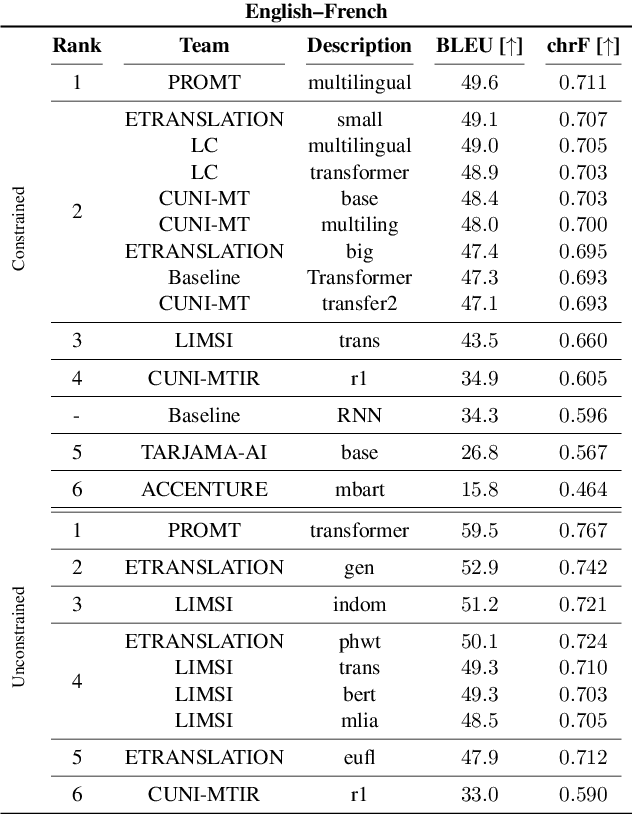
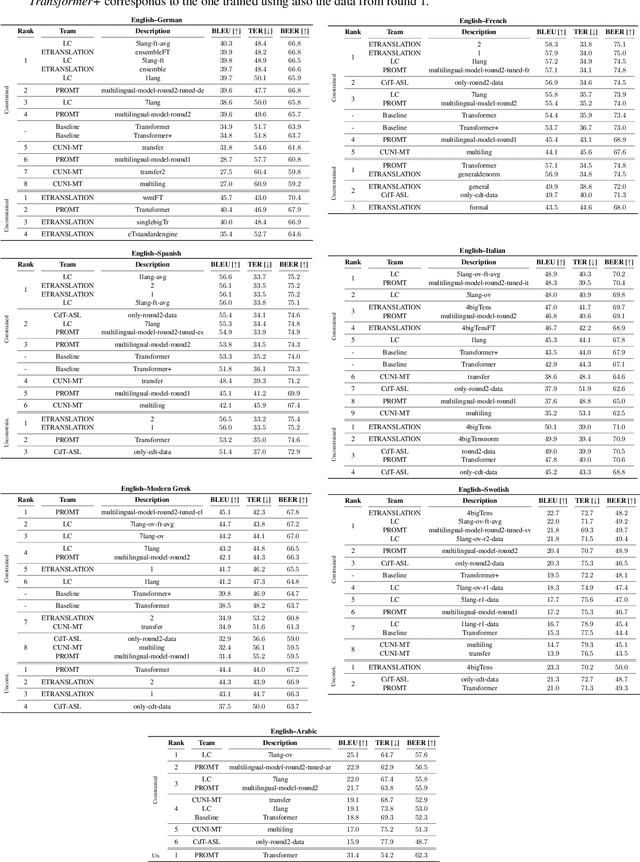
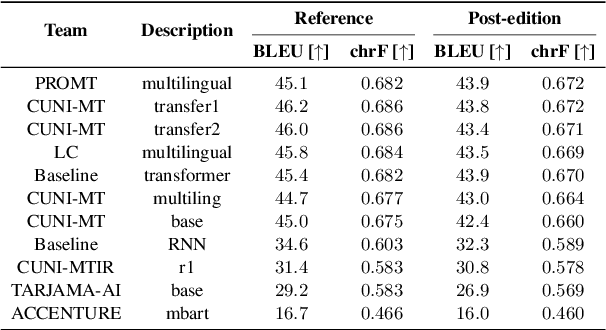
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.
Joint Event Detection and Entity Resolution: a Virtuous Cycle
Jul 18, 2016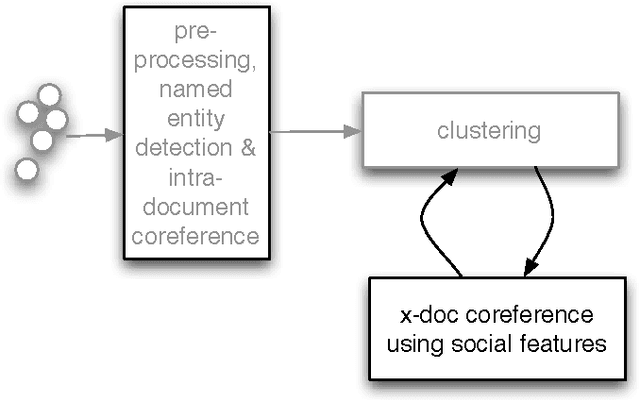
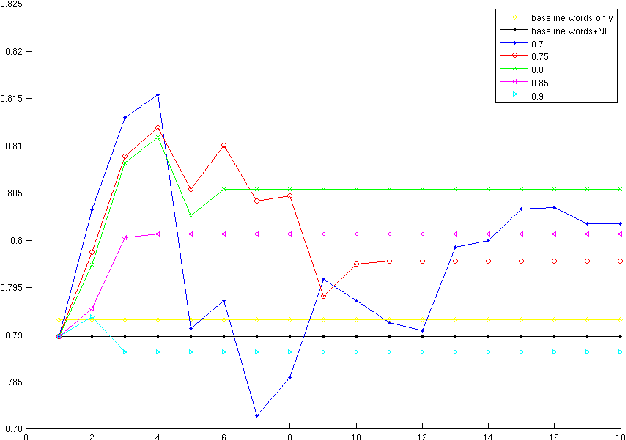
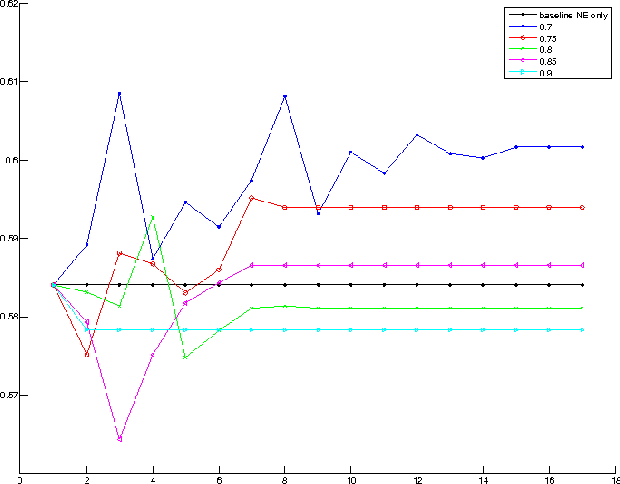
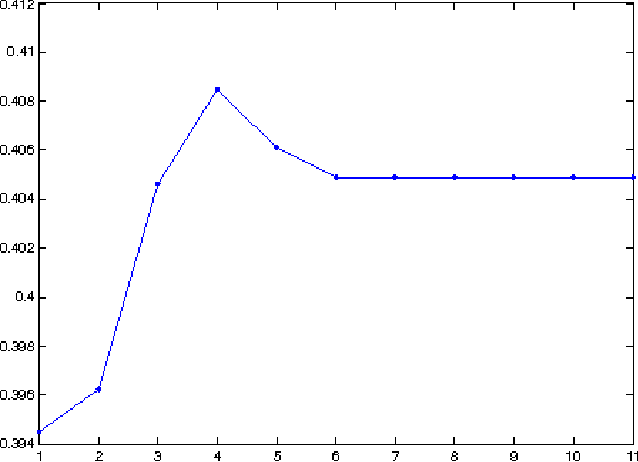
Clustering web documents has numerous applications, such as aggregating news articles into meaningful events, detecting trends and hot topics on the Web, preserving diversity in search results, etc. At the same time, the importance of named entities and, in particular, the ability to recognize them and to solve the associated co-reference resolution problem are widely recognized as key enabling factors when mining, aggregating and comparing content on the Web. Instead of considering these two problems separately, we propose in this paper a method that tackles jointly the problem of clustering news articles into events and cross-document co-reference resolution of named entities. The co-occurrence of named entities in the same clusters is used as an additional signal to decide whether two referents should be merged into one entity. These refined entities can in turn be used as enhanced features to re-cluster the documents and then be refined again, entering into a virtuous cycle that improves simultaneously the performances of both tasks. We implemented a prototype system and report results using the TDT5 collection of news articles, demonstrating the potential of our approach.
Observing Trends in Automated Multilingual Media Analysis
Mar 08, 2016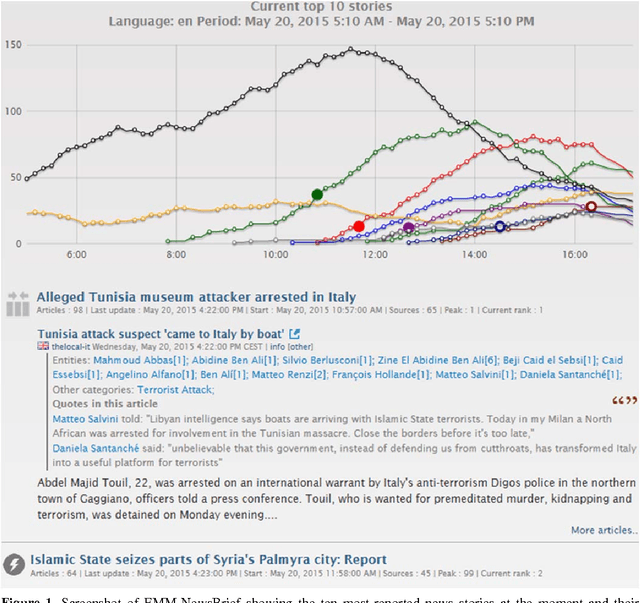
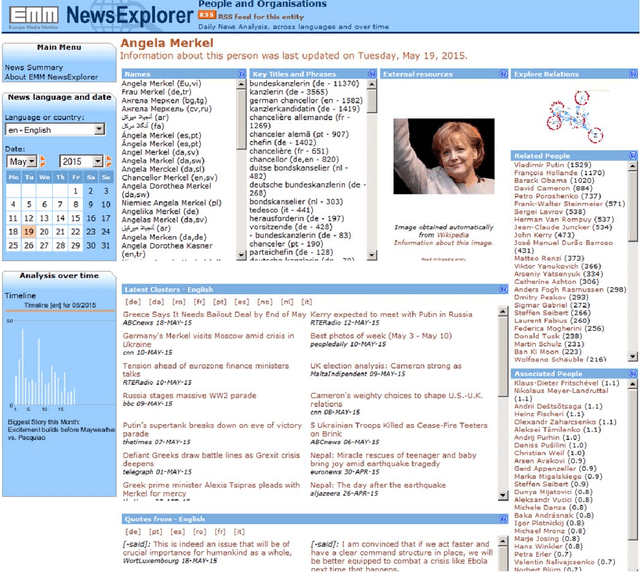
Any large organisation, be it public or private, monitors the media for information to keep abreast of developments in their field of interest, and usually also to become aware of positive or negative opinions expressed towards them. At least for the written media, computer programs have become very efficient at helping the human analysts significantly in their monitoring task by gathering media reports, analysing them, detecting trends and - in some cases - even to issue early warnings or to make predictions of likely future developments. We present here trend recognition-related functionality of the Europe Media Monitor (EMM) system, which was developed by the European Commission's Joint Research Centre (JRC) for public administrations in the European Union (EU) and beyond. EMM performs large-scale media analysis in up to seventy languages and recognises various types of trends, some of them combining information from news articles written in different languages and from social media posts. EMM also lets users explore the huge amount of multilingual media data through interactive maps and graphs, allowing them to examine the data from various view points and according to multiple criteria. A lot of EMM's functionality is accessibly freely over the internet or via apps for hand-held devices.