 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-SVeRL: Self-Verified Reinforcement Learning with Soft Rewards
May 27, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has improved language models in domains such as mathematics and code, where correctness can be checked automatically. However, many important tasks are only partially verifiable: prompts contain multiple requirements, responses may satisfy some but not all of them, or no single reference answer might exist. We introduce Soft-RLVR, a framework for reinforcement learning from decomposed, learned verification signals. Soft-RLVR converts each prompt into a checklist of atomic requirements, scores candidate responses item by item with an LLM verifier, and trains on the resulting soft reward. Checklist-based rewards turn sparse pass/fail supervision into a denser partial-credit signal, but they also introduce a tradeoff: averaging item-level judgments can reduce verifier noise, while partial credit can reward incomplete responses. We formalize this tradeoff and identify conditions under which checklist-based verification gives a more reliable RL training signal than holistic verification. We further introduce Soft-SVeRL, a self-verifying variant of Soft-RLVR in which the policy also acts as the verifier. We show that self-verification is prone to reward inflation from overly permissive self-judgments, and that explicit stabilization is needed to prevent this collapse. In a controlled instruction-following setting with rule-based ground-truth evaluation, checklist-based Soft-RLVR improves IFEval by up to 11.1 points using only learned verifier rewards. Our experiments further show that verifier quality and checklist quality both affect downstream RL outcomes, and that explicit stabilization is essential for effective self-verification.
`Keep it Together': Enforcing Cohesion in Extractive Summaries by Simulating Human Memory
Feb 16, 2024



Extractive summaries are usually presented as lists of sentences with no expected cohesion between them. In this paper, we aim to enforce cohesion whilst controlling for informativeness and redundancy in summaries, in cases where the input exhibits high redundancy. The pipeline controls for redundancy in long inputs as it is consumed, and balances informativeness and cohesion during sentence selection. Our sentence selector simulates human memory to keep track of topics --modeled as lexical chains--, enforcing cohesive ties between noun phrases. Across a variety of domains, our experiments revealed that it is possible to extract highly cohesive summaries that nevertheless read as informative to humans as summaries extracted by only accounting for informativeness or redundancy. The extracted summaries exhibit smooth topic transitions between sentences as signaled by lexical chains, with chains spanning adjacent or near-adjacent sentences.
On the Trade-off between Redundancy and Local Coherence in Summarization
May 20, 2022
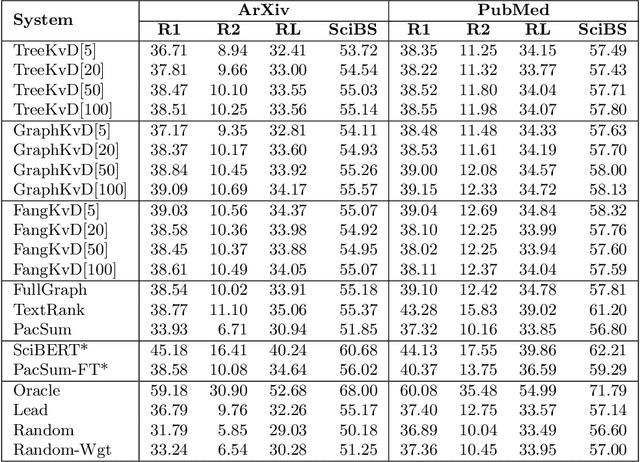

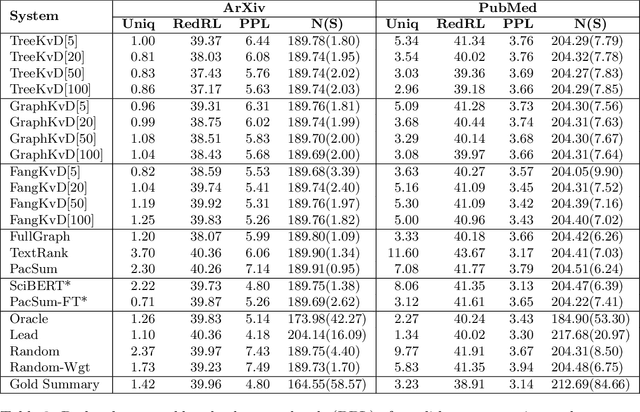
Extractive summarization systems are known to produce poorly coherent and, if not accounted for, highly redundant text. In this work, we tackle the problem of summary redundancy in unsupervised extractive summarization of long, highly-redundant documents. For this, we leverage a psycholinguistic theory of human reading comprehension which directly models local coherence and redundancy. Implementing this theory, our system operates at the proposition level and exploits properties of human memory representations to rank similarly content units that are coherent and non-redundant, hence encouraging the extraction of less redundant final summaries. Because of the impact of the summary length on automatic measures, we control for it by formulating content selection as an optimization problem with soft constraints in the budget of information retrieved. Using summarization of scientific articles as a case study, extensive experiments demonstrate that the proposed systems extract consistently less redundant summaries across increasing levels of document redundancy, whilst maintaining comparable performance (in terms of relevancy and local coherence) against strong unsupervised baselines according to automated evaluations.
Unsupervised Extractive Summarization by Human Memory Simulation
Apr 16, 2021
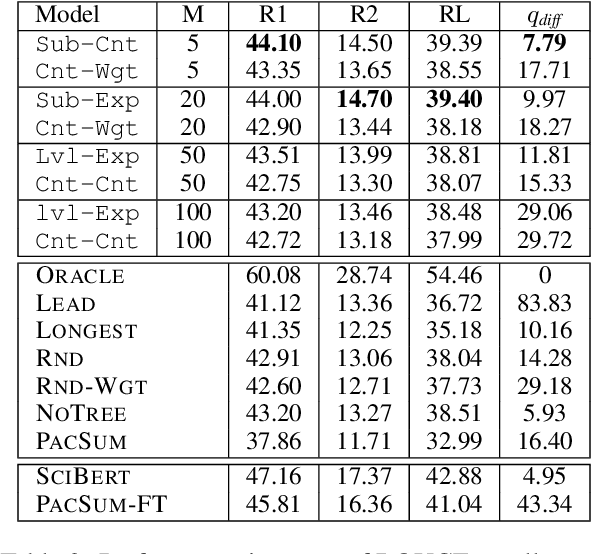

Summarization systems face the core challenge of identifying and selecting important information. In this paper, we tackle the problem of content selection in unsupervised extractive summarization of long, structured documents. We introduce a wide range of heuristics that leverage cognitive representations of content units and how these are retained or forgotten in human memory. We find that properties of these representations of human memory can be exploited to capture relevance of content units in scientific articles. Experiments show that our proposed heuristics are effective at leveraging cognitive structures and the organization of the document (i.e.\ sections of an article), and automatic and human evaluations provide strong evidence that these heuristics extract more summary-worthy content units.
Discriminating between similar languages in Twitter using label propagation
Jul 19, 2016

Identifying the language of social media messages is an important first step in linguistic processing. Existing models for Twitter focus on content analysis, which is successful for dissimilar language pairs. We propose a label propagation approach that takes the social graph of tweet authors into account as well as content to better tease apart similar languages. This results in state-of-the-art shared task performance of $76.63\%$, $1.4\%$ higher than the top system.
Joint Event Detection and Entity Resolution: a Virtuous Cycle
Jul 18, 2016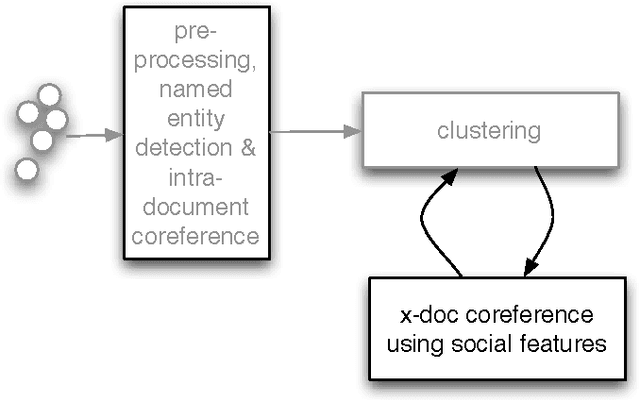
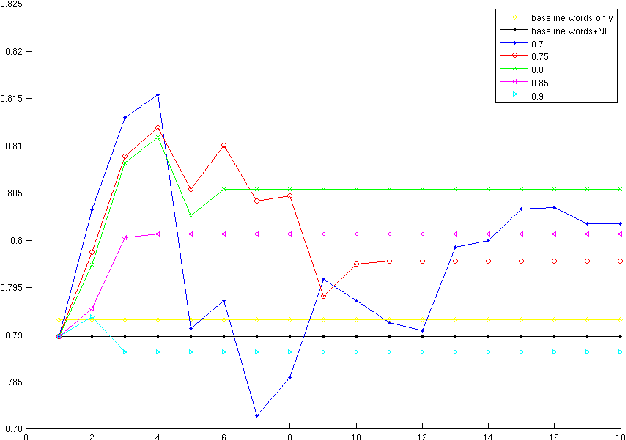
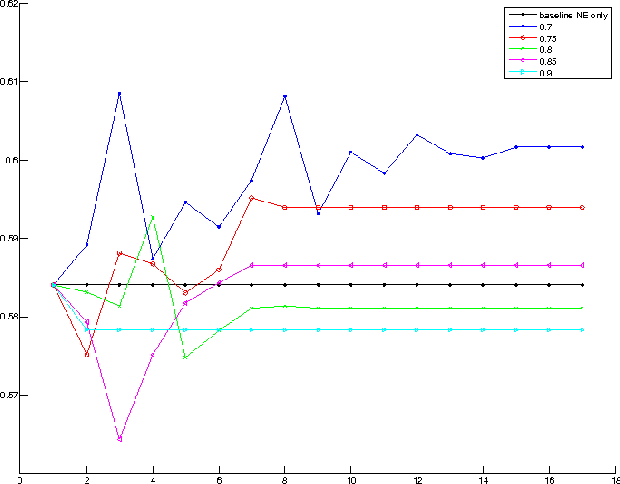
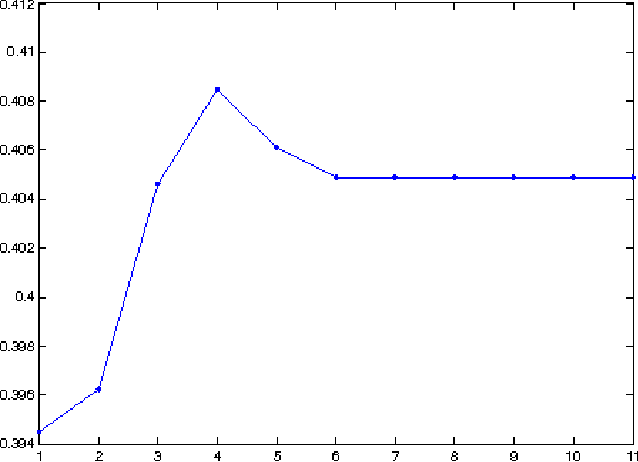
Clustering web documents has numerous applications, such as aggregating news articles into meaningful events, detecting trends and hot topics on the Web, preserving diversity in search results, etc. At the same time, the importance of named entities and, in particular, the ability to recognize them and to solve the associated co-reference resolution problem are widely recognized as key enabling factors when mining, aggregating and comparing content on the Web. Instead of considering these two problems separately, we propose in this paper a method that tackles jointly the problem of clustering news articles into events and cross-document co-reference resolution of named entities. The co-occurrence of named entities in the same clusters is used as an additional signal to decide whether two referents should be merged into one entity. These refined entities can in turn be used as enhanced features to re-cluster the documents and then be refined again, entering into a virtuous cycle that improves simultaneously the performances of both tasks. We implemented a prototype system and report results using the TDT5 collection of news articles, demonstrating the potential of our approach.