 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Deep Information Synthesis
Feb 24, 2026Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.
SparsePO: Controlling Preference Alignment of LLMs via Sparse Token Masks
Oct 07, 2024



Preference Optimization (PO) has proven an effective step for aligning language models to human-desired behaviors. Current variants, following the offline Direct Preference Optimization objective, have focused on a strict setting where all tokens are contributing signals of KL divergence and rewards to the loss function. However, human preference is not affected by each word in a sequence equally but is often dependent on specific words or phrases, e.g. existence of toxic terms leads to non-preferred responses. Based on this observation, we argue that not all tokens should be weighted equally during PO and propose a flexible objective termed SparsePO, that aims to automatically learn to weight the KL divergence and reward corresponding to each token during PO training. We propose two different variants of weight-masks that can either be derived from the reference model itself or learned on the fly. Notably, our method induces sparsity in the learned masks, allowing the model to learn how to best weight reward and KL divergence contributions at the token level, learning an optimal level of mask sparsity. Extensive experiments on multiple domains, including sentiment control, dialogue, text summarization and text-to-code generation, illustrate that our approach assigns meaningful weights to tokens according to the target task, generates more responses with the desired preference and improves reasoning tasks by up to 2 percentage points compared to other token- and response-level PO methods.
`Keep it Together': Enforcing Cohesion in Extractive Summaries by Simulating Human Memory
Feb 16, 2024



Extractive summaries are usually presented as lists of sentences with no expected cohesion between them. In this paper, we aim to enforce cohesion whilst controlling for informativeness and redundancy in summaries, in cases where the input exhibits high redundancy. The pipeline controls for redundancy in long inputs as it is consumed, and balances informativeness and cohesion during sentence selection. Our sentence selector simulates human memory to keep track of topics --modeled as lexical chains--, enforcing cohesive ties between noun phrases. Across a variety of domains, our experiments revealed that it is possible to extract highly cohesive summaries that nevertheless read as informative to humans as summaries extracted by only accounting for informativeness or redundancy. The extracted summaries exhibit smooth topic transitions between sentences as signaled by lexical chains, with chains spanning adjacent or near-adjacent sentences.
'Don't Get Too Technical with Me': A Discourse Structure-Based Framework for Science Journalism
Oct 23, 2023


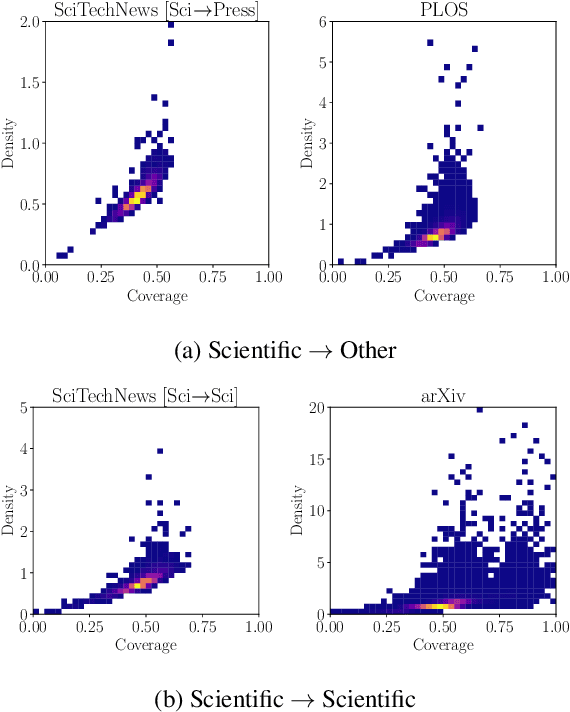
Science journalism refers to the task of reporting technical findings of a scientific paper as a less technical news article to the general public audience. We aim to design an automated system to support this real-world task (i.e., automatic science journalism) by 1) introducing a newly-constructed and real-world dataset (SciTechNews), with tuples of a publicly-available scientific paper, its corresponding news article, and an expert-written short summary snippet; 2) proposing a novel technical framework that integrates a paper's discourse structure with its metadata to guide generation; and, 3) demonstrating with extensive automatic and human experiments that our framework outperforms other baseline methods (e.g. Alpaca and ChatGPT) in elaborating a content plan meaningful for the target audience, simplifying the information selected, and producing a coherent final report in a layman's style.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
On the Trade-off between Redundancy and Local Coherence in Summarization
May 20, 2022
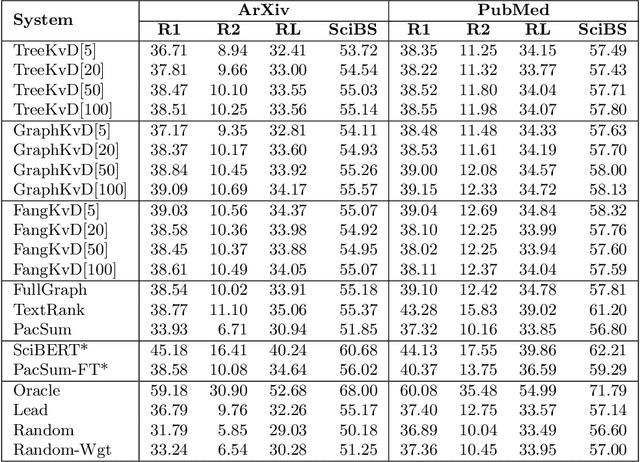

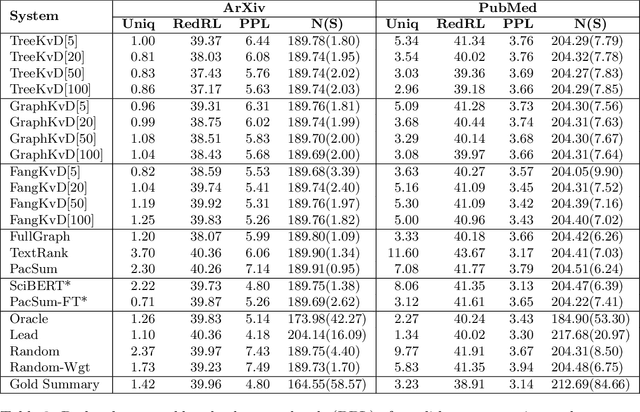
Extractive summarization systems are known to produce poorly coherent and, if not accounted for, highly redundant text. In this work, we tackle the problem of summary redundancy in unsupervised extractive summarization of long, highly-redundant documents. For this, we leverage a psycholinguistic theory of human reading comprehension which directly models local coherence and redundancy. Implementing this theory, our system operates at the proposition level and exploits properties of human memory representations to rank similarly content units that are coherent and non-redundant, hence encouraging the extraction of less redundant final summaries. Because of the impact of the summary length on automatic measures, we control for it by formulating content selection as an optimization problem with soft constraints in the budget of information retrieved. Using summarization of scientific articles as a case study, extensive experiments demonstrate that the proposed systems extract consistently less redundant summaries across increasing levels of document redundancy, whilst maintaining comparable performance (in terms of relevancy and local coherence) against strong unsupervised baselines according to automated evaluations.
Unsupervised Extractive Summarization by Human Memory Simulation
Apr 16, 2021
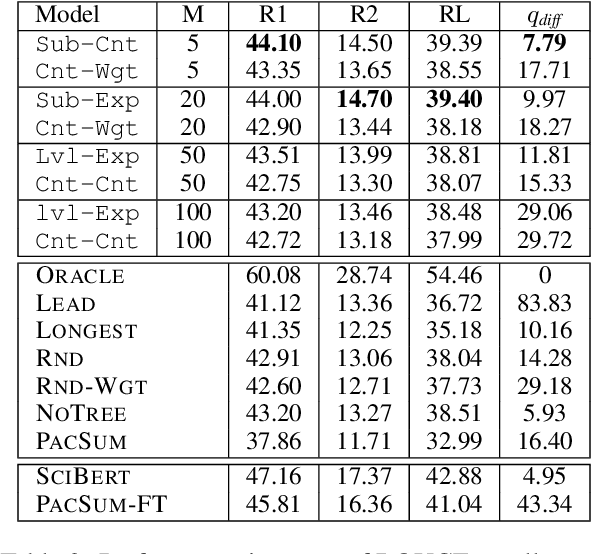

Summarization systems face the core challenge of identifying and selecting important information. In this paper, we tackle the problem of content selection in unsupervised extractive summarization of long, structured documents. We introduce a wide range of heuristics that leverage cognitive representations of content units and how these are retained or forgotten in human memory. We find that properties of these representations of human memory can be exploited to capture relevance of content units in scientific articles. Experiments show that our proposed heuristics are effective at leveraging cognitive structures and the organization of the document (i.e.\ sections of an article), and automatic and human evaluations provide strong evidence that these heuristics extract more summary-worthy content units.
A Grounded Unsupervised Universal Part-of-Speech Tagger for Low-Resource Languages
Apr 10, 2019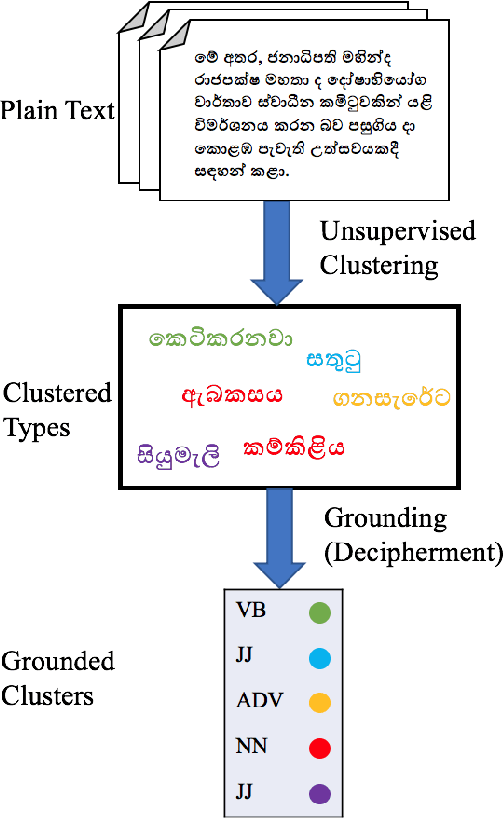
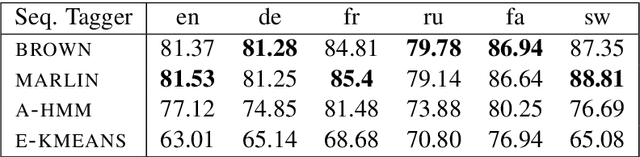
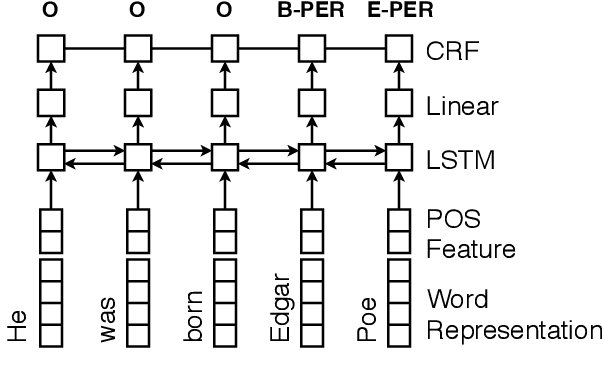

Unsupervised part of speech (POS) tagging is often framed as a clustering problem, but practical taggers need to \textit{ground} their clusters as well. Grounding generally requires reference labeled data, a luxury a low-resource language might not have. In this work, we describe an approach for low-resource unsupervised POS tagging that yields fully grounded output and requires no labeled training data. We find the classic method of Brown et al. (1992) clusters well in our use case and employ a decipherment-based approach to grounding. This approach presumes a sequence of cluster IDs is a `ciphertext' and seeks a POS tag-to-cluster ID mapping that will reveal the POS sequence. We show intrinsically that, despite the difficulty of the task, we obtain reasonable performance across a variety of languages. We also show extrinsically that incorporating our POS tagger into a name tagger leads to state-of-the-art tagging performance in Sinhalese and Kinyarwanda, two languages with nearly no labeled POS data available. We further demonstrate our tagger's utility by incorporating it into a true `zero-resource' variant of the Malopa (Ammar et al., 2016) dependency parser model that removes the current reliance on multilingual resources and gold POS tags for new languages. Experiments show that including our tagger makes up much of the accuracy lost when gold POS tags are unavailable.