 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-ToM: Evaluating Multilingual Theory of Mind Capabilities in Large Language Models
Nov 24, 2024Theory of Mind (ToM) refers to the cognitive ability to infer and attribute mental states to oneself and others. As large language models (LLMs) are increasingly evaluated for social and cognitive capabilities, it remains unclear to what extent these models demonstrate ToM across diverse languages and cultural contexts. In this paper, we introduce a comprehensive study of multilingual ToM capabilities aimed at addressing this gap. Our approach includes two key components: (1) We translate existing ToM datasets into multiple languages, effectively creating a multilingual ToM dataset and (2) We enrich these translations with culturally specific elements to reflect the social and cognitive scenarios relevant to diverse populations. We conduct extensive evaluations of six state-of-the-art LLMs to measure their ToM performance across both the translated and culturally adapted datasets. The results highlight the influence of linguistic and cultural diversity on the models' ability to exhibit ToM, and questions their social reasoning capabilities. This work lays the groundwork for future research into enhancing LLMs' cross-cultural social cognition and contributes to the development of more culturally aware and socially intelligent AI systems. All our data and code are publicly available.
An Empirical Study on the Characteristics of Bias upon Context Length Variation for Bangla
Jun 25, 2024Pretrained language models inherently exhibit various social biases, prompting a crucial examination of their social impact across various linguistic contexts due to their widespread usage. Previous studies have provided numerous methods for intrinsic bias measurements, predominantly focused on high-resource languages. In this work, we aim to extend these investigations to Bangla, a low-resource language. Specifically, in this study, we (1) create a dataset for intrinsic gender bias measurement in Bangla, (2) discuss necessary adaptations to apply existing bias measurement methods for Bangla, and (3) examine the impact of context length variation on bias measurement, a factor that has been overlooked in previous studies. Through our experiments, we demonstrate a clear dependency of bias metrics on context length, highlighting the need for nuanced considerations in Bangla bias analysis. We consider our work as a stepping stone for bias measurement in the Bangla Language and make all of our resources publicly available to support future research.
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Mar 30, 2024The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
BanglaParaphrase: A High-Quality Bangla Paraphrase Dataset
Oct 11, 2022
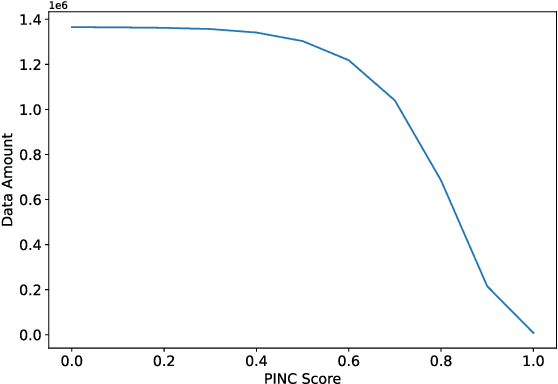

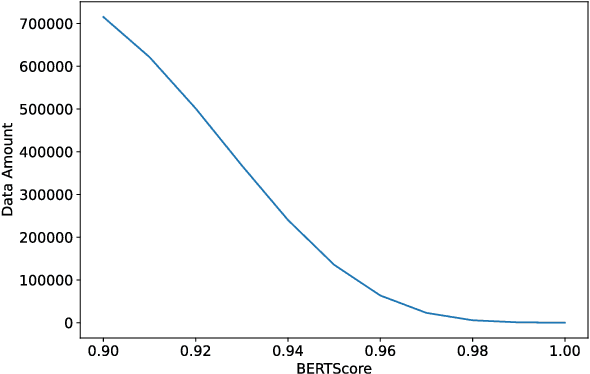
In this work, we present BanglaParaphrase, a high-quality synthetic Bangla Paraphrase dataset curated by a novel filtering pipeline. We aim to take a step towards alleviating the low resource status of the Bangla language in the NLP domain through the introduction of BanglaParaphrase, which ensures quality by preserving both semantics and diversity, making it particularly useful to enhance other Bangla datasets. We show a detailed comparative analysis between our dataset and models trained on it with other existing works to establish the viability of our synthetic paraphrase data generation pipeline. We are making the dataset and models publicly available at https://github.com/csebuetnlp/banglaparaphrase to further the state of Bangla NLP.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
BanglaNLG: Benchmarks and Resources for Evaluating Low-Resource Natural Language Generation in Bangla
May 24, 2022

This work presents BanglaNLG, a comprehensive benchmark for evaluating natural language generation (NLG) models in Bangla, a widely spoken yet low-resource language in the web domain. We aggregate three challenging conditional text generation tasks under the BanglaNLG benchmark. Then, using a clean corpus of 27.5 GB of Bangla data, we pretrain BanglaT5, a sequence-to-sequence Transformer model for Bangla. BanglaT5 achieves state-of-the-art performance in all of these tasks, outperforming mT5 (base) by up to 5.4%. We are making the BanglaT5 language model and a leaderboard publicly available in the hope of advancing future research and evaluation on Bangla NLG. The resources can be found at https://github.com/csebuetnlp/BanglaNLG.
CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs
Dec 16, 2021We present CrossSum, a large-scale dataset comprising 1.65 million cross-lingual article-summary samples in 1500+ language-pairs constituting 45 languages. We use the multilingual XL-Sum dataset and align identical articles written in different languages via cross-lingual retrieval using a language-agnostic representation model. We propose a multi-stage data sampling algorithm and fine-tune mT5, a multilingual pretrained model, with explicit cross-lingual supervision with CrossSum and introduce a new metric for evaluating cross-lingual summarization. Results on established and our proposed metrics indicate that models fine-tuned on CrossSum outperforms summarization+translation baselines, even when the source and target language pairs are linguistically distant. To the best of our knowledge, CrossSum is the largest cross-lingual summarization dataset and also the first-ever that does not rely on English as the pivot language. We are releasing the dataset, alignment and training scripts, and the models to spur future research on cross-lingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/CrossSum}.
XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
Jun 25, 2021
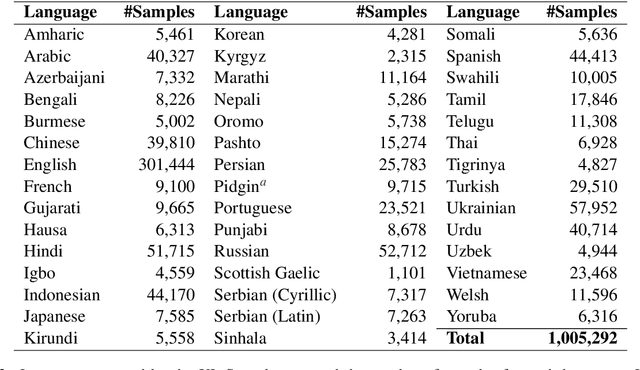
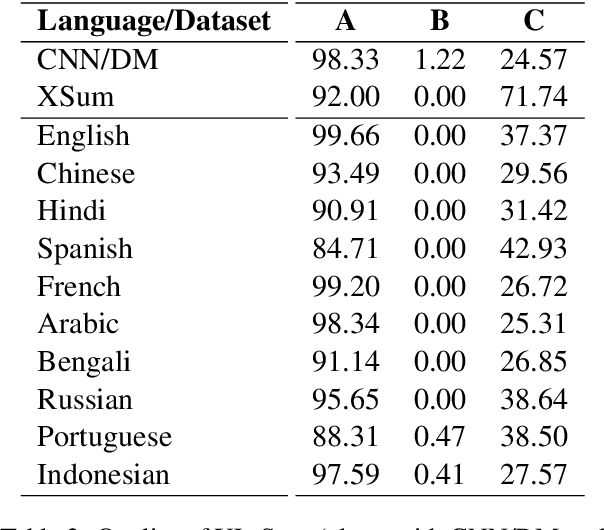
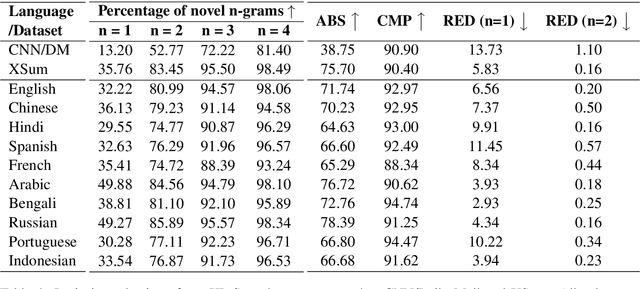
Contemporary works on abstractive text summarization have focused primarily on high-resource languages like English, mostly due to the limited availability of datasets for low/mid-resource ones. In this work, we present XL-Sum, a comprehensive and diverse dataset comprising 1 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 44 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation. We fine-tune mT5, a state-of-the-art pretrained multilingual model, with XL-Sum and experiment on multilingual and low-resource summarization tasks. XL-Sum induces competitive results compared to the ones obtained using similar monolingual datasets: we show higher than 11 ROUGE-2 scores on 10 languages we benchmark on, with some of them exceeding 15, as obtained by multilingual training. Additionally, training on low-resource languages individually also provides competitive performance. To the best of our knowledge, XL-Sum is the largest abstractive summarization dataset in terms of the number of samples collected from a single source and the number of languages covered. We are releasing our dataset and models to encourage future research on multilingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/xl-sum}.
BanglaBERT: Combating Embedding Barrier for Low-Resource Language Understanding
Jan 01, 2021Pre-training language models on large volume of data with self-supervised objectives has become a standard practice in natural language processing. However, most such state-of-the-art models are available in only English and other resource-rich languages. Even in multilingual models, which are trained on hundreds of languages, low-resource ones still remain underrepresented. Bangla, the seventh most widely spoken language in the world, is still low in terms of resources. Few downstream task datasets for language understanding in Bangla are publicly available, and there is a clear shortage of good quality data for pre-training. In this work, we build a Bangla natural language understanding model pre-trained on 18.6 GB data we crawled from top Bangla sites on the internet. We introduce a new downstream task dataset and benchmark on four tasks on sentence classification, document classification, natural language understanding, and sequence tagging. Our model outperforms multilingual baselines and previous state-of-the-art results by 1-6%. In the process, we identify a major shortcoming of multilingual models that hurt performance for low-resource languages that don't share writing scripts with any high resource one, which we name the `Embedding Barrier'. We perform extensive experiments to study this barrier. We release all our datasets and pre-trained models to aid future NLP research on Bangla and other low-resource languages. Our code and data are available at https://github.com/csebuetnlp/banglabert.
Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for Bengali-English Machine Translation
Oct 07, 2020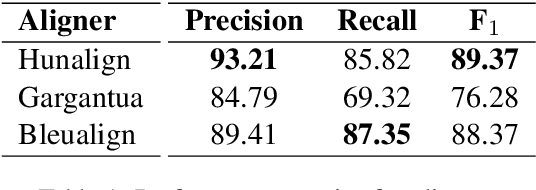
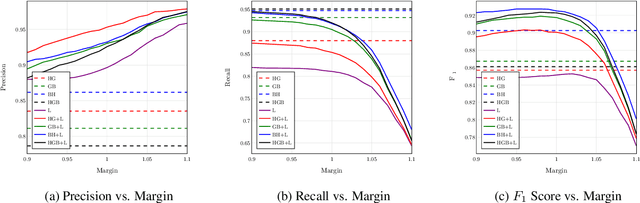
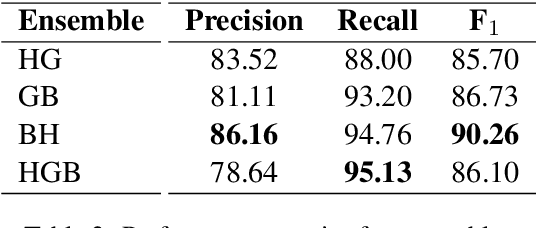
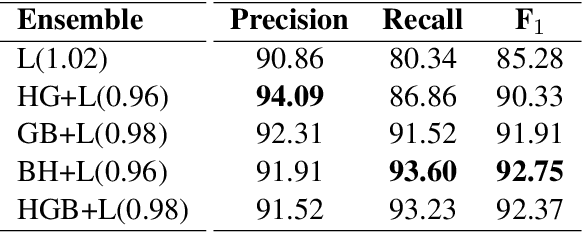
Despite being the seventh most widely spoken language in the world, Bengali has received much less attention in machine translation literature due to being low in resources. Most publicly available parallel corpora for Bengali are not large enough; and have rather poor quality, mostly because of incorrect sentence alignments resulting from erroneous sentence segmentation, and also because of a high volume of noise present in them. In this work, we build a customized sentence segmenter for Bengali and propose two novel methods for parallel corpus creation on low-resource setups: aligner ensembling and batch filtering. With the segmenter and the two methods combined, we compile a high-quality Bengali-English parallel corpus comprising of 2.75 million sentence pairs, more than 2 million of which were not available before. Training on neural models, we achieve an improvement of more than 9 BLEU score over previous approaches to Bengali-English machine translation. We also evaluate on a new test set of 1000 pairs made with extensive quality control. We release the segmenter, parallel corpus, and the evaluation set, thus elevating Bengali from its low-resource status. To the best of our knowledge, this is the first ever large scale study on Bengali-English machine translation. We believe our study will pave the way for future research on Bengali-English machine translation as well as other low-resource languages. Our data and code are available at https://github.com/csebuetnlp/banglanmt.