Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaParaphrase: A High-Quality Bangla Paraphrase Dataset
Paper and Code

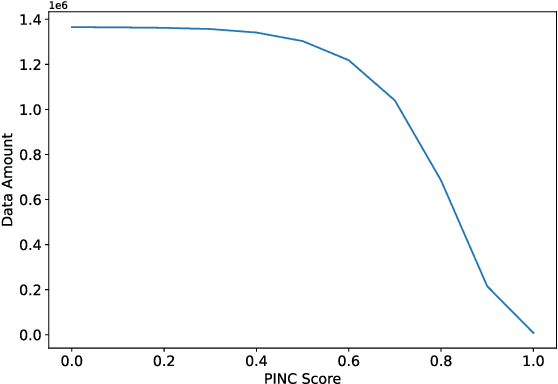

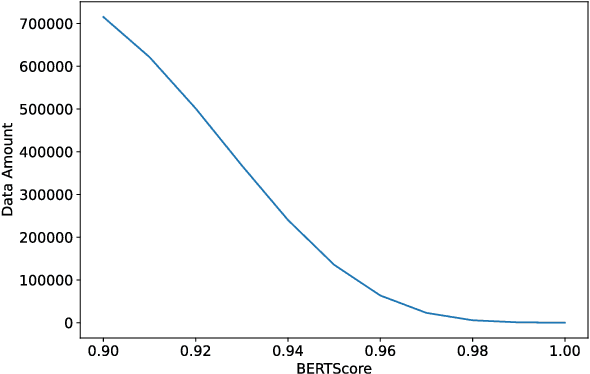
In this work, we present BanglaParaphrase, a high-quality synthetic Bangla Paraphrase dataset curated by a novel filtering pipeline. We aim to take a step towards alleviating the low resource status of the Bangla language in the NLP domain through the introduction of BanglaParaphrase, which ensures quality by preserving both semantics and diversity, making it particularly useful to enhance other Bangla datasets. We show a detailed comparative analysis between our dataset and models trained on it with other existing works to establish the viability of our synthetic paraphrase data generation pipeline. We are making the dataset and models publicly available at https://github.com/csebuetnlp/banglaparaphrase to further the state of Bangla NLP.
* AACL 2022 (camera-ready)
View paper on