 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicEval: A Systematic Framework for Evaluating Automated Repair Techniques for Logical Vulnerabilities in Real-World Software
Apr 14, 2026Logical vulnerabilities in software stem from flaws in program logic rather than memory safety, which can lead to critical security failures. Although existing automated program repair techniques primarily focus on repairing memory corruption vulnerabilities, they struggle with logical vulnerabilities because of their limited semantic understanding of the vulnerable code and its expected behavior. On the other hand, recent successes of large language models (LLMs) in understanding and repairing code are promising. However, no framework currently exists to analyze the capabilities and limitations of such techniques for logical vulnerabilities. This paper aims to systematically evaluate both traditional and LLM-based repair approaches for addressing real-world logical vulnerabilities. To facilitate our assessment, we created the first ever dataset, LogicDS, of 86 logical vulnerabilities with assigned CVEs reflecting tangible security impact. We also developed a systematic framework, LogicEval, to evaluate patches for logical vulnerabilities. Evaluations suggest that compilation and testing failures are primarily driven by prompt sensitivity, loss of code context, and difficulty in patch localization.
Second-Order Information Matters: Revisiting Machine Unlearning for Large Language Models
Mar 13, 2024



With the rapid development of Large Language Models (LLMs), we have witnessed intense competition among the major LLM products like ChatGPT, LLaMa, and Gemini. However, various issues (e.g. privacy leakage and copyright violation) of the training corpus still remain underexplored. For example, the Times sued OpenAI and Microsoft for infringing on its copyrights by using millions of its articles for training. From the perspective of LLM practitioners, handling such unintended privacy violations can be challenging. Previous work addressed the ``unlearning" problem of LLMs using gradient information, while they mostly introduced significant overheads like data preprocessing or lacked robustness. In this paper, contrasting with the methods based on first-order information, we revisit the unlearning problem via the perspective of second-order information (Hessian). Our unlearning algorithms, which are inspired by classic Newton update, are not only data-agnostic/model-agnostic but also proven to be robust in terms of utility preservation or privacy guarantee. Through a comprehensive evaluation with four NLP datasets as well as a case study on real-world datasets, our methods consistently show superiority over the first-order methods.
FLTrojan: Privacy Leakage Attacks against Federated Language Models Through Selective Weight Tampering
Oct 24, 2023


Federated learning (FL) is becoming a key component in many technology-based applications including language modeling -- where individual FL participants often have privacy-sensitive text data in their local datasets. However, realizing the extent of privacy leakage in federated language models is not straightforward and the existing attacks only intend to extract data regardless of how sensitive or naive it is. To fill this gap, in this paper, we introduce two novel findings with regard to leaking privacy-sensitive user data from federated language models. Firstly, we make a key observation that model snapshots from the intermediate rounds in FL can cause greater privacy leakage than the final trained model. Secondly, we identify that privacy leakage can be aggravated by tampering with a model's selective weights that are specifically responsible for memorizing the sensitive training data. We show how a malicious client can leak the privacy-sensitive data of some other user in FL even without any cooperation from the server. Our best-performing method improves the membership inference recall by 29% and achieves up to 70% private data reconstruction, evidently outperforming existing attacks with stronger assumptions of adversary capabilities.
BanglaParaphrase: A High-Quality Bangla Paraphrase Dataset
Oct 11, 2022
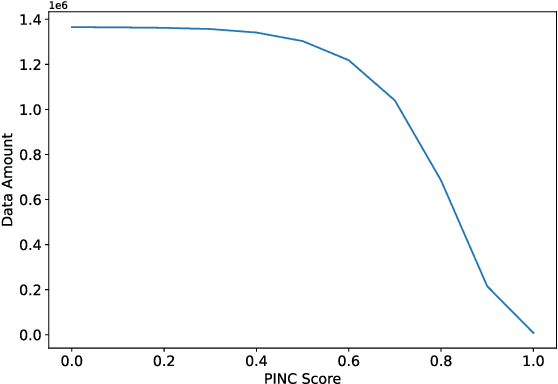

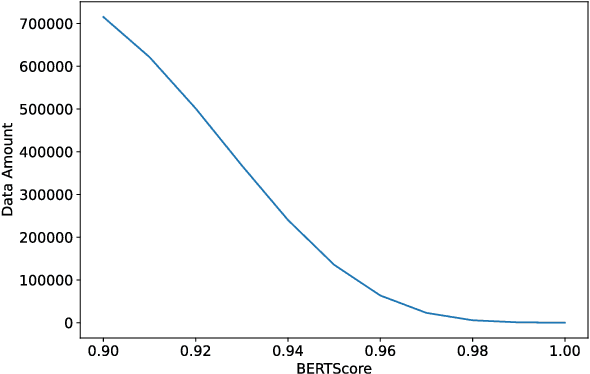
In this work, we present BanglaParaphrase, a high-quality synthetic Bangla Paraphrase dataset curated by a novel filtering pipeline. We aim to take a step towards alleviating the low resource status of the Bangla language in the NLP domain through the introduction of BanglaParaphrase, which ensures quality by preserving both semantics and diversity, making it particularly useful to enhance other Bangla datasets. We show a detailed comparative analysis between our dataset and models trained on it with other existing works to establish the viability of our synthetic paraphrase data generation pipeline. We are making the dataset and models publicly available at https://github.com/csebuetnlp/banglaparaphrase to further the state of Bangla NLP.