 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInceptive Transformers: Enhancing Contextual Representations through Multi-Scale Feature Learning Across Domains and Languages
May 26, 2025Conventional transformer models typically compress the information from all tokens in a sequence into a single \texttt{[CLS]} token to represent global context-- an approach that can lead to information loss in tasks requiring localized or hierarchical cues. In this work, we introduce \textit{Inceptive Transformer}, a modular and lightweight architecture that enriches transformer-based token representations by integrating a multi-scale feature extraction module inspired by inception networks. Our model is designed to balance local and global dependencies by dynamically weighting tokens based on their relevance to a particular task. Evaluation across a diverse range of tasks including emotion recognition (both English and Bangla), irony detection, disease identification, and anti-COVID vaccine tweets classification shows that our models consistently outperform the baselines by 1\% to 14\% while maintaining efficiency. These findings highlight the versatility and cross-lingual applicability of our method for enriching transformer-based representations across diverse domains.
Multi-ToM: Evaluating Multilingual Theory of Mind Capabilities in Large Language Models
Nov 24, 2024Theory of Mind (ToM) refers to the cognitive ability to infer and attribute mental states to oneself and others. As large language models (LLMs) are increasingly evaluated for social and cognitive capabilities, it remains unclear to what extent these models demonstrate ToM across diverse languages and cultural contexts. In this paper, we introduce a comprehensive study of multilingual ToM capabilities aimed at addressing this gap. Our approach includes two key components: (1) We translate existing ToM datasets into multiple languages, effectively creating a multilingual ToM dataset and (2) We enrich these translations with culturally specific elements to reflect the social and cognitive scenarios relevant to diverse populations. We conduct extensive evaluations of six state-of-the-art LLMs to measure their ToM performance across both the translated and culturally adapted datasets. The results highlight the influence of linguistic and cultural diversity on the models' ability to exhibit ToM, and questions their social reasoning capabilities. This work lays the groundwork for future research into enhancing LLMs' cross-cultural social cognition and contributes to the development of more culturally aware and socially intelligent AI systems. All our data and code are publicly available.
ChakmaNMT: A Low-resource Machine Translation On Chakma Language
Oct 14, 2024



The geopolitical division between the indigenous Chakma population and mainstream Bangladesh creates a significant cultural and linguistic gap, as the Chakma community, mostly residing in the hill tracts of Bangladesh, maintains distinct cultural traditions and language. Developing a Machine Translation (MT) model or Chakma to Bangla could play a crucial role in alleviating this cultural-linguistic divide. Thus, we have worked on MT between CCP-BN(Chakma-Bangla) by introducing a novel dataset of 15,021 parallel samples and 42,783 monolingual samples of the Chakma Language. Moreover, we introduce a small set for Benchmarking containing 600 parallel samples between Chakma, Bangla, and English. We ran traditional and state-of-the-art models in NLP on the training set, where fine-tuning BanglaT5 with back-translation using transliteration of Chakma achieved the highest BLEU score of 17.8 and 4.41 in CCP-BN and BN-CCP respectively on the Benchmark Dataset. As far as we know, this is the first-ever work on MT for the Chakma Language. Hopefully, this research will help to bridge the gap in linguistic resources and contribute to preserving endangered languages. Our dataset link and codes will be published soon.
ConVerSum: A Contrastive Learning based Approach for Data-Scarce Solution of Cross-Lingual Summarization Beyond Direct Equivalents
Aug 17, 2024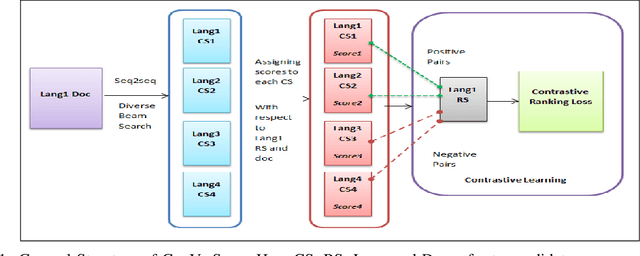
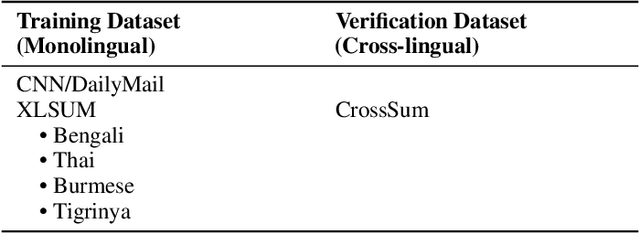
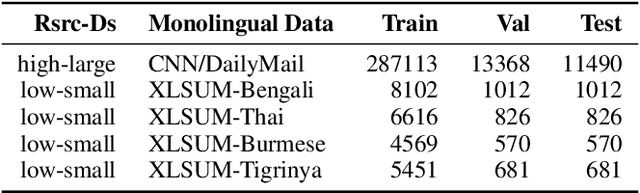
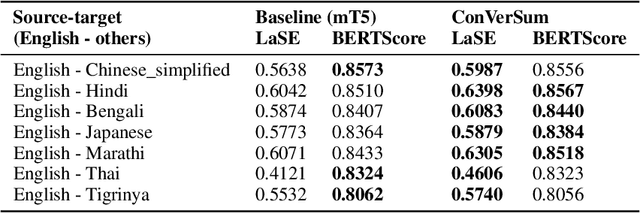
Cross-Lingual summarization (CLS) is a sophisticated branch in Natural Language Processing that demands models to accurately translate and summarize articles from different source languages. Despite the improvement of the subsequent studies, This area still needs data-efficient solutions along with effective training methodologies. To the best of our knowledge, there is no feasible solution for CLS when there is no available high-quality CLS data. In this paper, we propose a novel data-efficient approach, ConVerSum, for CLS leveraging the power of contrastive learning, generating versatile candidate summaries in different languages based on the given source document and contrasting these summaries with reference summaries concerning the given documents. After that, we train the model with a contrastive ranking loss. Then, we rigorously evaluate the proposed approach against current methodologies and compare it to powerful Large Language Models (LLMs)- Gemini, GPT 3.5, and GPT 4 proving our model performs better for low-resource languages' CLS. These findings represent a substantial improvement in the area, opening the door to more efficient and accurate cross-lingual summarizing techniques.
An Empirical Study of Gendered Stereotypes in Emotional Attributes for Bangla in Multilingual Large Language Models
Jul 08, 2024The influence of Large Language Models (LLMs) is rapidly growing, automating more jobs over time. Assessing the fairness of LLMs is crucial due to their expanding impact. Studies reveal the reflection of societal norms and biases in LLMs, which creates a risk of propagating societal stereotypes in downstream tasks. Many studies on bias in LLMs focus on gender bias in various NLP applications. However, there's a gap in research on bias in emotional attributes, despite the close societal link between emotion and gender. This gap is even larger for low-resource languages like Bangla. Historically, women are associated with emotions like empathy, fear, and guilt, while men are linked to anger, bravado, and authority. This pattern reflects societal norms in Bangla-speaking regions. We offer the first thorough investigation of gendered emotion attribution in Bangla for both closed and open source LLMs in this work. Our aim is to elucidate the intricate societal relationship between gender and emotion specifically within the context of Bangla. We have been successful in showing the existence of gender bias in the context of emotions in Bangla through analytical methods and also show how emotion attribution changes on the basis of gendered role selection in LLMs. All of our resources including code and data are made publicly available to support future research on Bangla NLP. Warning: This paper contains explicit stereotypical statements that many may find offensive.
Social Bias in Large Language Models For Bangla: An Empirical Study on Gender and Religious Bias
Jul 03, 2024The rapid growth of Large Language Models (LLMs) has put forward the study of biases as a crucial field. It is important to assess the influence of different types of biases embedded in LLMs to ensure fair use in sensitive fields. Although there have been extensive works on bias assessment in English, such efforts are rare and scarce for a major language like Bangla. In this work, we examine two types of social biases in LLM generated outputs for Bangla language. Our main contributions in this work are: (1) bias studies on two different social biases for Bangla (2) a curated dataset for bias measurement benchmarking (3) two different probing techniques for bias detection in the context of Bangla. This is the first work of such kind involving bias assessment of LLMs for Bangla to the best of our knowledge. All our code and resources are publicly available for the progress of bias related research in Bangla NLP.
An Empirical Study on the Characteristics of Bias upon Context Length Variation for Bangla
Jun 25, 2024Pretrained language models inherently exhibit various social biases, prompting a crucial examination of their social impact across various linguistic contexts due to their widespread usage. Previous studies have provided numerous methods for intrinsic bias measurements, predominantly focused on high-resource languages. In this work, we aim to extend these investigations to Bangla, a low-resource language. Specifically, in this study, we (1) create a dataset for intrinsic gender bias measurement in Bangla, (2) discuss necessary adaptations to apply existing bias measurement methods for Bangla, and (3) examine the impact of context length variation on bias measurement, a factor that has been overlooked in previous studies. Through our experiments, we demonstrate a clear dependency of bias metrics on context length, highlighting the need for nuanced considerations in Bangla bias analysis. We consider our work as a stepping stone for bias measurement in the Bangla Language and make all of our resources publicly available to support future research.
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Mar 30, 2024The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
BanglaParaphrase: A High-Quality Bangla Paraphrase Dataset
Oct 11, 2022
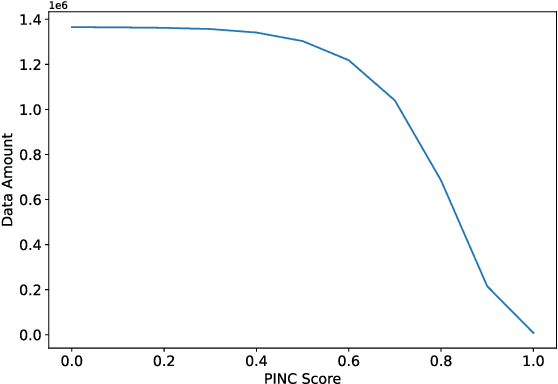

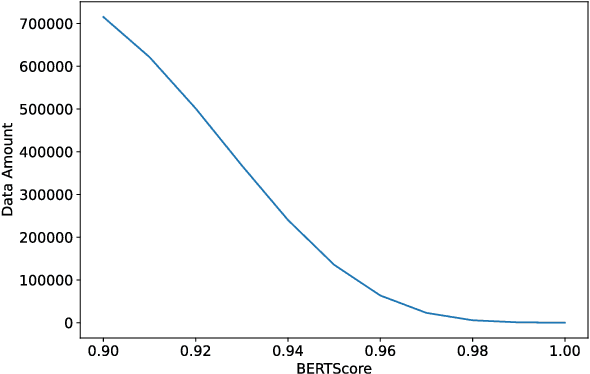
In this work, we present BanglaParaphrase, a high-quality synthetic Bangla Paraphrase dataset curated by a novel filtering pipeline. We aim to take a step towards alleviating the low resource status of the Bangla language in the NLP domain through the introduction of BanglaParaphrase, which ensures quality by preserving both semantics and diversity, making it particularly useful to enhance other Bangla datasets. We show a detailed comparative analysis between our dataset and models trained on it with other existing works to establish the viability of our synthetic paraphrase data generation pipeline. We are making the dataset and models publicly available at https://github.com/csebuetnlp/banglaparaphrase to further the state of Bangla NLP.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.