 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConVerSum: A Contrastive Learning based Approach for Data-Scarce Solution of Cross-Lingual Summarization Beyond Direct Equivalents
Aug 17, 2024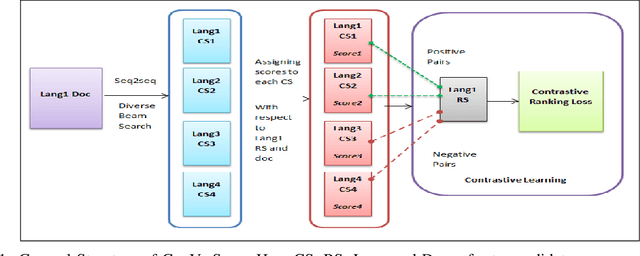
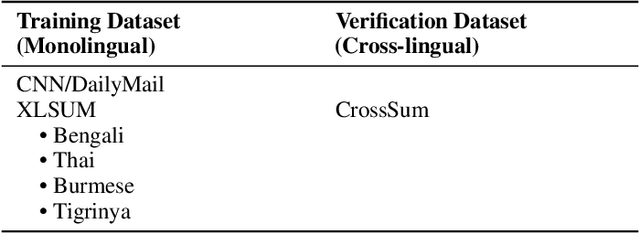
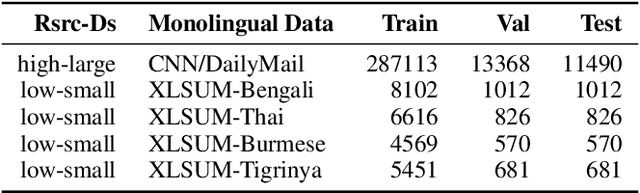
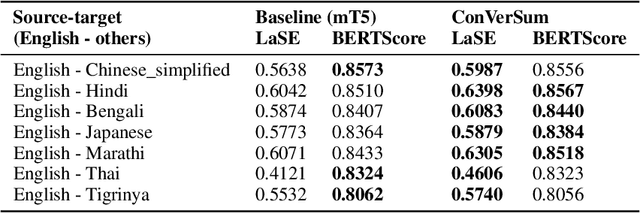
Cross-Lingual summarization (CLS) is a sophisticated branch in Natural Language Processing that demands models to accurately translate and summarize articles from different source languages. Despite the improvement of the subsequent studies, This area still needs data-efficient solutions along with effective training methodologies. To the best of our knowledge, there is no feasible solution for CLS when there is no available high-quality CLS data. In this paper, we propose a novel data-efficient approach, ConVerSum, for CLS leveraging the power of contrastive learning, generating versatile candidate summaries in different languages based on the given source document and contrasting these summaries with reference summaries concerning the given documents. After that, we train the model with a contrastive ranking loss. Then, we rigorously evaluate the proposed approach against current methodologies and compare it to powerful Large Language Models (LLMs)- Gemini, GPT 3.5, and GPT 4 proving our model performs better for low-resource languages' CLS. These findings represent a substantial improvement in the area, opening the door to more efficient and accurate cross-lingual summarizing techniques.