 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAL: Inducing Human-likeness in LLMs with Alignment
Jan 07, 2026Conversational human-likeness plays a central role in human-AI interaction, yet it has remained difficult to define, measure, and optimize. As a result, improvements in human-like behavior are largely driven by scale or broad supervised training, rather than targeted alignment. We introduce Human Aligning LLMs (HAL), a framework for aligning language models to conversational human-likeness using an interpretable, data-driven reward. HAL derives explicit conversational traits from contrastive dialogue data, combines them into a compact scalar score, and uses this score as a transparent reward signal for alignment with standard preference optimization methods. Using this approach, we align models of varying sizes without affecting their overall performance. In large-scale human evaluations, models aligned with HAL are more frequently perceived as human-like in conversation. Because HAL operates over explicit, interpretable traits, it enables inspection of alignment behavior and diagnosis of unintended effects. More broadly, HAL demonstrates how soft, qualitative properties of language--previously outside the scope for alignment--can be made measurable and aligned in an interpretable and explainable way.
AI Standardized Patient Improves Human Conversations in Advanced Cancer Care
May 05, 2025Serious illness communication (SIC) in end-of-life care faces challenges such as emotional stress, cultural barriers, and balancing hope with honesty. Despite its importance, one of the few available ways for clinicians to practice SIC is with standardized patients, which is expensive, time-consuming, and inflexible. In this paper, we present SOPHIE, an AI-powered standardized patient simulation and automated feedback system. SOPHIE combines large language models (LLMs), a lifelike virtual avatar, and automated, personalized feedback based on clinical literature to provide remote, on-demand SIC training. In a randomized control study with healthcare students and professionals, SOPHIE users demonstrated significant improvement across three critical SIC domains: Empathize, Be Explicit, and Empower. These results suggest that AI-driven tools can enhance complex interpersonal communication skills, offering scalable, accessible solutions to address a critical gap in clinician education.
ChakmaNMT: A Low-resource Machine Translation On Chakma Language
Oct 14, 2024



The geopolitical division between the indigenous Chakma population and mainstream Bangladesh creates a significant cultural and linguistic gap, as the Chakma community, mostly residing in the hill tracts of Bangladesh, maintains distinct cultural traditions and language. Developing a Machine Translation (MT) model or Chakma to Bangla could play a crucial role in alleviating this cultural-linguistic divide. Thus, we have worked on MT between CCP-BN(Chakma-Bangla) by introducing a novel dataset of 15,021 parallel samples and 42,783 monolingual samples of the Chakma Language. Moreover, we introduce a small set for Benchmarking containing 600 parallel samples between Chakma, Bangla, and English. We ran traditional and state-of-the-art models in NLP on the training set, where fine-tuning BanglaT5 with back-translation using transliteration of Chakma achieved the highest BLEU score of 17.8 and 4.41 in CCP-BN and BN-CCP respectively on the Benchmark Dataset. As far as we know, this is the first-ever work on MT for the Chakma Language. Hopefully, this research will help to bridge the gap in linguistic resources and contribute to preserving endangered languages. Our dataset link and codes will be published soon.
Hi5: 2D Hand Pose Estimation with Zero Human Annotation
Jun 05, 2024



We propose a new large synthetic hand pose estimation dataset, Hi5, and a novel inexpensive method for collecting high-quality synthetic data that requires no human annotation or validation. Leveraging recent advancements in computer graphics, high-fidelity 3D hand models with diverse genders and skin colors, and dynamic environments and camera movements, our data synthesis pipeline allows precise control over data diversity and representation, ensuring robust and fair model training. We generate a dataset with 583,000 images with accurate pose annotation using a single consumer PC that closely represents real-world variability. Pose estimation models trained with Hi5 perform competitively on real-hand benchmarks while surpassing models trained with real data when tested on occlusions and perturbations. Our experiments show promising results for synthetic data as a viable solution for data representation problems in real datasets. Overall, this paper provides a promising new approach to synthetic data creation and annotation that can reduce costs and increase the diversity and quality of data for hand pose estimation.
LowResource at BLP-2023 Task 2: Leveraging BanglaBert for Low Resource Sentiment Analysis of Bangla Language
Nov 21, 2023
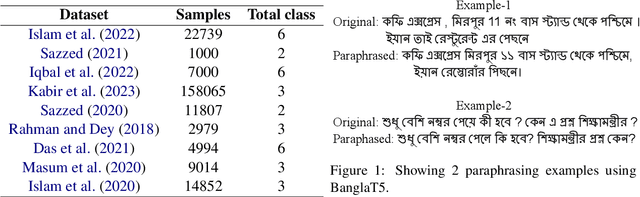

This paper describes the system of the LowResource Team for Task 2 of BLP-2023, which involves conducting sentiment analysis on a dataset composed of public posts and comments from diverse social media platforms. Our primary aim is to utilize BanglaBert, a BERT model pre-trained on a large Bangla corpus, using various strategies including fine-tuning, dropping random tokens, and using several external datasets. Our final model is an ensemble of the three best BanglaBert variations. Our system has achieved overall 3rd in the Test Set among 30 participating teams with a score of 0.718. Additionally, we discuss the promising systems that didn't perform well namely task-adaptive pertaining and paraphrasing using BanglaT5. Training codes and external datasets which are used for our system are publicly available at https://github.com/Aunabil4602/bnlp-workshop-task2-2023
SAPIEN: Affective Virtual Agents Powered by Large Language Models
Aug 06, 2023In this demo paper, we introduce SAPIEN, a platform for high-fidelity virtual agents driven by large language models that can hold open domain conversations with users in 13 different languages, and display emotions through facial expressions and voice. The platform allows users to customize their virtual agent's personality, background, and conversation premise, thus providing a rich, immersive interaction experience. Furthermore, after the virtual meeting, the user can choose to get the conversation analyzed and receive actionable feedback on their communication skills. This paper illustrates an overview of the platform and discusses the various application domains of this technology, ranging from entertainment to mental health, communication training, language learning, education, healthcare, and beyond. Additionally, we consider the ethical implications of such realistic virtual agent representations and the potential challenges in ensuring responsible use.
Automated Program Repair Based on Code Review: How do Pre-trained Transformer Models Perform?
Apr 16, 2023



Sequence-to-sequence models have been used to transform erroneous programs into correct ones when trained with a large enough dataset. Some recent studies also demonstrated strong empirical evidence that code review (natural language instruction about suggestive changes in code) can improve the program repair further. Large language models, trained with Natural Language (NL) and computer program corpora, have the capacity to contain inherent knowledge of both. In this study, we investigate if this inherent knowledge of code and NL can be utilized to improve automated program repair. We applied PLBART and CodeT5, two state-of-the-art language models that are pre-trained with both Programming Language (PL) and Natural Language (NL), on two such natural language-based program repair datasets and found that the pre-trained language models fine-tuned with datasets containing both code review and subsequent code changes notably outperform each of the previous models. We observed that the pre-trained models improve the previously best-reported results by 9.91% on the Review4Repair dataset and by 24.72% on the dataset by Tufano et al. This suggests that a pre-trained sequential model has a better understanding of natural language and can utilize it much better. We performed an ablation study to assess the contribution of the pre-training mechanism and the model architecture. We found that pre-training was significantly more important in the performance gain than the model architecture. The practical application of using pre-trained transformer models in the context of automated program repair is still a long way off. However, our study demonstrates the substantial value of employing pre-trained models, paving the path for future studies to use more of these.
Auto-Gait: Automatic Ataxia Risk Assessment with Computer Vision on Gait Task Videos
Mar 15, 2022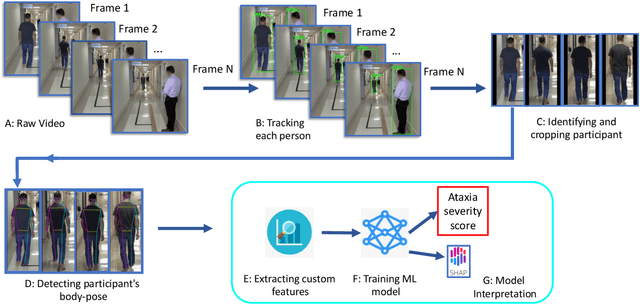


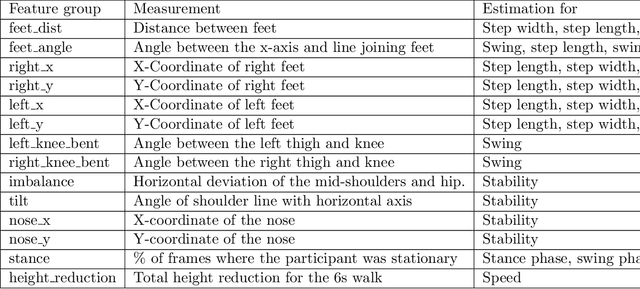
In this paper, we investigated whether we can 1) detect participants with ataxia-specific gait characteristics (risk-prediction), and 2) assess severity of ataxia from gait (severity-assessment). We collected 155 videos from 89 participants, 24 controls and 65 diagnosed with (or are pre-manifest) spinocerebellar ataxias (SCAs), performing the gait task of the Scale for the Assessment and Rating of Ataxia (SARA) from 11 medical sites located in 8 different states in the United States. We developed a method to separate the participants from their surroundings and constructed several features to capture gait characteristics like step width, step length, swing, stability, speed, etc. Our risk-prediction model achieves 83.06% accuracy and an 80.23% F1 score. Similarly, our severity-assessment model achieves a mean absolute error (MAE) score of 0.6225 and a Pearson's correlation coefficient score of 0.7268. Our models still performed competitively when evaluated on data from sites not used during training. Furthermore, through feature importance analysis, we found that our models associate wider steps, decreased walking speed, and increased instability with greater ataxia severity, which is consistent with previously established clinical knowledge. Our models create possibilities for remote ataxia assessment in non-clinical settings in the future, which could significantly improve accessibility of ataxia care. Furthermore, our underlying dataset was assembled from a geographically diverse cohort, highlighting its potential to further increase equity. The code used in this study is open to the public, and the anonymized body pose landmark dataset could be released upon approval from our Institutional Review Board (IRB).
CoDesc: A Large Code-Description Parallel Dataset
May 29, 2021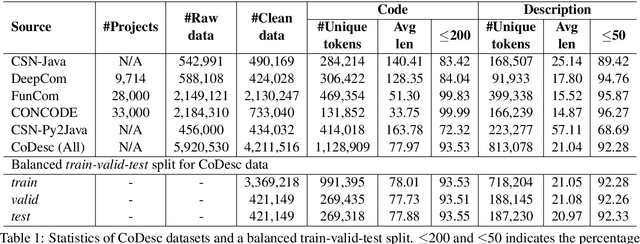
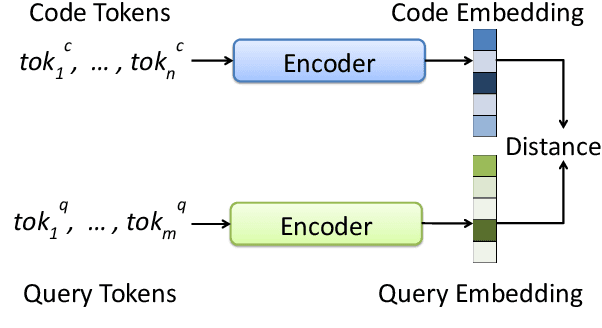
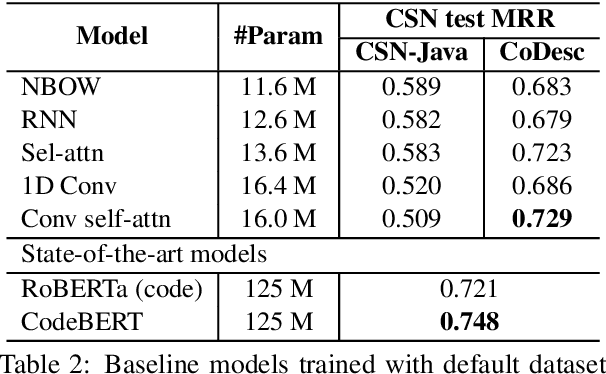

Translation between natural language and source code can help software development by enabling developers to comprehend, ideate, search, and write computer programs in natural language. Despite growing interest from the industry and the research community, this task is often difficult due to the lack of large standard datasets suitable for training deep neural models, standard noise removal methods, and evaluation benchmarks. This leaves researchers to collect new small-scale datasets, resulting in inconsistencies across published works. In this study, we present CoDesc -- a large parallel dataset composed of 4.2 million Java methods and natural language descriptions. With extensive analysis, we identify and remove prevailing noise patterns from the dataset. We demonstrate the proficiency of CoDesc in two complementary tasks for code-description pairs: code summarization and code search. We show that the dataset helps improve code search by up to 22\% and achieves the new state-of-the-art in code summarization. Furthermore, we show CoDesc's effectiveness in pre-training--fine-tuning setup, opening possibilities in building pretrained language models for Java. To facilitate future research, we release the dataset, a data processing tool, and a benchmark at \url{https://github.com/csebuetnlp/CoDesc}.
Text2App: A Framework for Creating Android Apps from Text Descriptions
Apr 16, 2021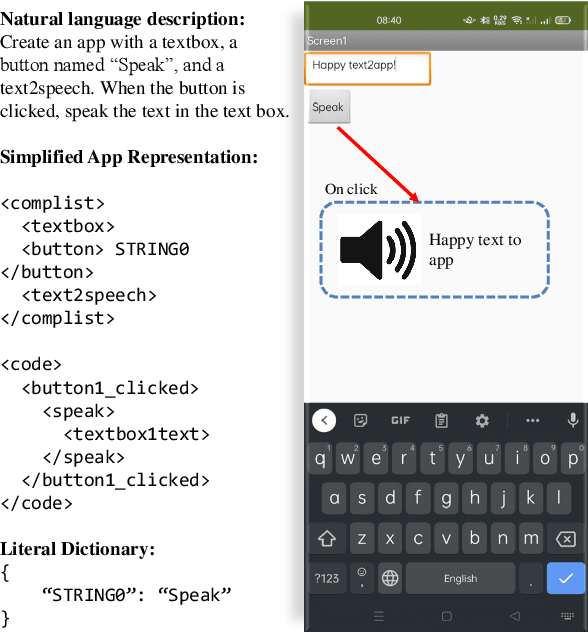

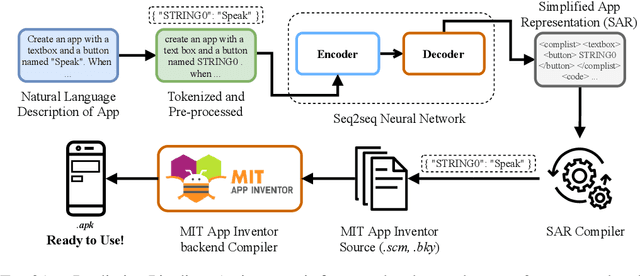
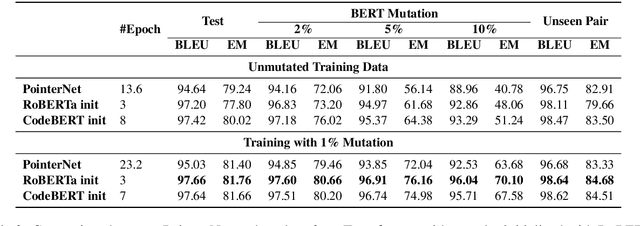
We present Text2App -- a framework that allows users to create functional Android applications from natural language specifications. The conventional method of source code generation tries to generate source code directly, which is impractical for creating complex software. We overcome this limitation by transforming natural language into an abstract intermediate formal language representing an application with a substantially smaller number of tokens. The intermediate formal representation is then compiled into target source codes. This abstraction of programming details allows seq2seq networks to learn complex application structures with less overhead. In order to train sequence models, we introduce a data synthesis method grounded in a human survey. We demonstrate that Text2App generalizes well to unseen combination of app components and it is capable of handling noisy natural language instructions. We explore the possibility of creating applications from highly abstract instructions by coupling our system with GPT-3 -- a large pretrained language model. The source code, a ready-to-run demo notebook, and a demo video are publicly available at \url{http://text2app.github.io}.