 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting and Fine-tuning Large Language Models for Automated Code Review Comment Generation
Nov 15, 2024



Generating accurate code review comments remains a significant challenge due to the inherently diverse and non-unique nature of the task output. Large language models pretrained on both programming and natural language data tend to perform well in code-oriented tasks. However, large-scale pretraining is not always feasible due to its environmental impact and project-specific generalizability issues. In this work, first we fine-tune open-source Large language models (LLM) in parameter-efficient, quantized low-rank (QLoRA) fashion on consumer-grade hardware to improve review comment generation. Recent studies demonstrate the efficacy of augmenting semantic metadata information into prompts to boost performance in other code-related tasks. To explore this in code review activities, we also prompt proprietary, closed-source LLMs augmenting the input code patch with function call graphs and code summaries. Both of our strategies improve the review comment generation performance, with function call graph augmented few-shot prompting on the GPT-3.5 model surpassing the pretrained baseline by around 90% BLEU-4 score on the CodeReviewer dataset. Moreover, few-shot prompted Gemini-1.0 Pro, QLoRA fine-tuned Code Llama and Llama 3.1 models achieve competitive results (ranging from 25% to 83% performance improvement) on this task. An additional human evaluation study further validates our experimental findings, reflecting real-world developers' perceptions of LLM-generated code review comments based on relevant qualitative metrics.
LogShield: A Transformer-based APT Detection System Leveraging Self-Attention
Nov 09, 2023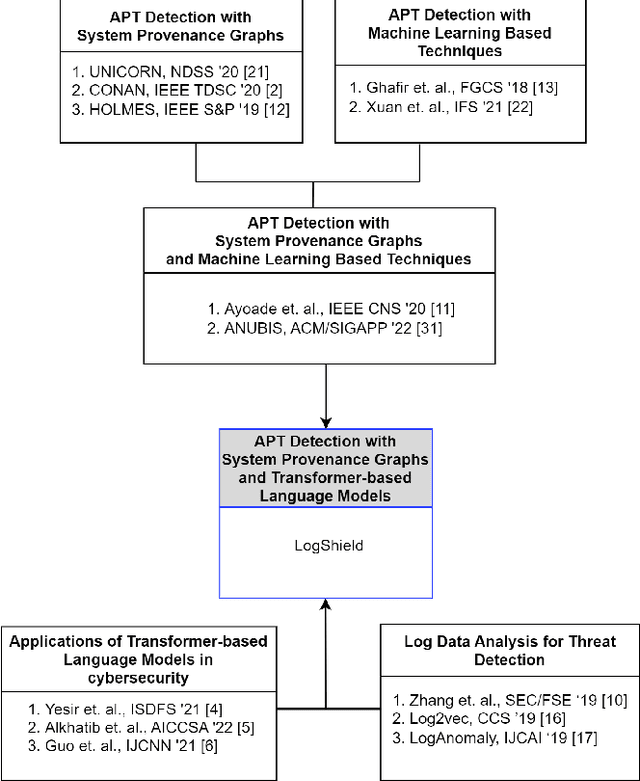
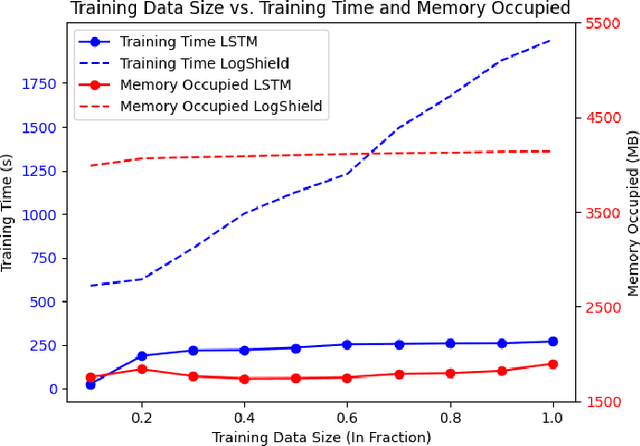
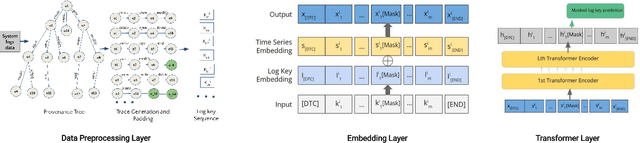
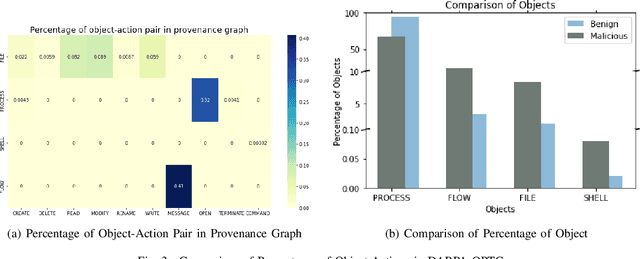
Cyber attacks are often identified using system and network logs. There have been significant prior works that utilize provenance graphs and ML techniques to detect attacks, specifically advanced persistent threats, which are very difficult to detect. Lately, there have been studies where transformer-based language models are being used to detect various types of attacks from system logs. However, no such attempts have been made in the case of APTs. In addition, existing state-of-the-art techniques that use system provenance graphs, lack a data processing framework generalized across datasets for optimal performance. For mitigating this limitation as well as exploring the effectiveness of transformer-based language models, this paper proposes LogShield, a framework designed to detect APT attack patterns leveraging the power of self-attention in transformers. We incorporate customized embedding layers to effectively capture the context of event sequences derived from provenance graphs. While acknowledging the computational overhead associated with training transformer networks, our framework surpasses existing LSTM and Language models regarding APT detection. We integrated the model parameters and training procedure from the RoBERTa model and conducted extensive experiments on well-known APT datasets (DARPA OpTC and DARPA TC E3). Our framework achieved superior F1 scores of 98% and 95% on the two datasets respectively, surpassing the F1 scores of 96% and 94% obtained by LSTM models. Our findings suggest that LogShield's performance benefits from larger datasets and demonstrates its potential for generalization across diverse domains. These findings contribute to the advancement of APT attack detection methods and underscore the significance of transformer-based architectures in addressing security challenges in computer systems.
Contrastive Learning for API Aspect Analysis
Aug 14, 2023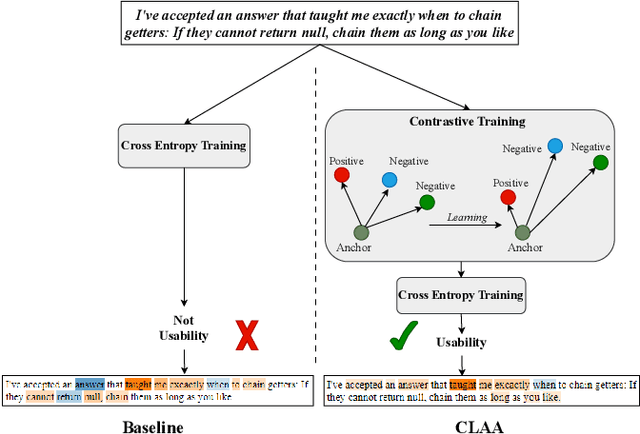



We present a novel approach - CLAA - for API aspect detection in API reviews that utilizes transformer models trained with a supervised contrastive loss objective function. We evaluate CLAA using performance and impact analysis. For performance analysis, we utilized a benchmark dataset on developer discussions collected from Stack Overflow and compare the results to those obtained using state-of-the-art transformer models. Our experiments show that contrastive learning can significantly improve the performance of transformer models in detecting aspects such as Performance, Security, Usability, and Documentation. For impact analysis, we performed empirical and developer study. On a randomly selected and manually labeled 200 online reviews, CLAA achieved 92% accuracy while the SOTA baseline achieved 81.5%. According to our developer study involving 10 participants, the use of 'Stack Overflow + CLAA' resulted in increased accuracy and confidence during API selection. Replication package: https://github.com/disa-lab/Contrastive-Learning-API-Aspect-ASE2023
Automated Program Repair Based on Code Review: How do Pre-trained Transformer Models Perform?
Apr 16, 2023



Sequence-to-sequence models have been used to transform erroneous programs into correct ones when trained with a large enough dataset. Some recent studies also demonstrated strong empirical evidence that code review (natural language instruction about suggestive changes in code) can improve the program repair further. Large language models, trained with Natural Language (NL) and computer program corpora, have the capacity to contain inherent knowledge of both. In this study, we investigate if this inherent knowledge of code and NL can be utilized to improve automated program repair. We applied PLBART and CodeT5, two state-of-the-art language models that are pre-trained with both Programming Language (PL) and Natural Language (NL), on two such natural language-based program repair datasets and found that the pre-trained language models fine-tuned with datasets containing both code review and subsequent code changes notably outperform each of the previous models. We observed that the pre-trained models improve the previously best-reported results by 9.91% on the Review4Repair dataset and by 24.72% on the dataset by Tufano et al. This suggests that a pre-trained sequential model has a better understanding of natural language and can utilize it much better. We performed an ablation study to assess the contribution of the pre-training mechanism and the model architecture. We found that pre-training was significantly more important in the performance gain than the model architecture. The practical application of using pre-trained transformer models in the context of automated program repair is still a long way off. However, our study demonstrates the substantial value of employing pre-trained models, paving the path for future studies to use more of these.
Are You Misinformed? A Study of Covid-Related Fake News in Bengali on Facebook
Mar 22, 2022


Our opinions and views of life can be shaped by how we perceive the opinions of others on social media like Facebook. This dependence has increased during COVID-19 periods when we have fewer means to connect with others. However, fake news related to COVID-19 has become a significant problem on Facebook. Bengali is the seventh most spoken language worldwide, yet we are aware of no previous research that studied the prevalence of COVID-19 related fake news in Bengali on Facebook. In this paper, we develop machine learning models to detect fake news in Bengali automatically. The best performing model is BERT, with an F1-score of 0.97. We apply BERT on all Facebook Bengali posts related to COVID-19. We find 10 topics in the COVID-19 Bengali fake news grouped into three categories: System (e.g., medical system), belief (e.g., religious rituals), and social (e.g., scientific awareness).
CoDesc: A Large Code-Description Parallel Dataset
May 29, 2021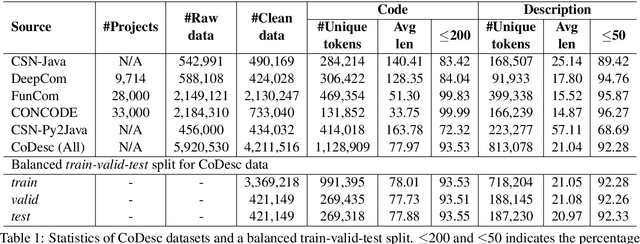
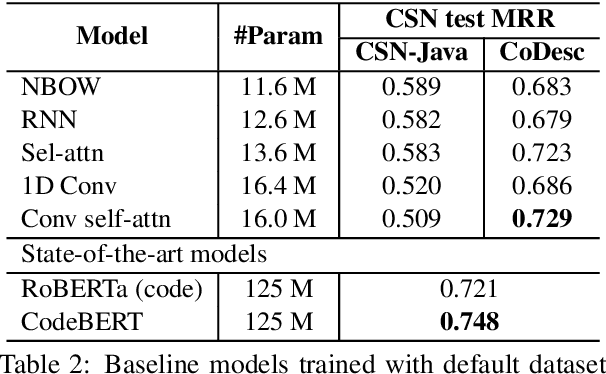

Translation between natural language and source code can help software development by enabling developers to comprehend, ideate, search, and write computer programs in natural language. Despite growing interest from the industry and the research community, this task is often difficult due to the lack of large standard datasets suitable for training deep neural models, standard noise removal methods, and evaluation benchmarks. This leaves researchers to collect new small-scale datasets, resulting in inconsistencies across published works. In this study, we present CoDesc -- a large parallel dataset composed of 4.2 million Java methods and natural language descriptions. With extensive analysis, we identify and remove prevailing noise patterns from the dataset. We demonstrate the proficiency of CoDesc in two complementary tasks for code-description pairs: code summarization and code search. We show that the dataset helps improve code search by up to 22\% and achieves the new state-of-the-art in code summarization. Furthermore, we show CoDesc's effectiveness in pre-training--fine-tuning setup, opening possibilities in building pretrained language models for Java. To facilitate future research, we release the dataset, a data processing tool, and a benchmark at \url{https://github.com/csebuetnlp/CoDesc}.
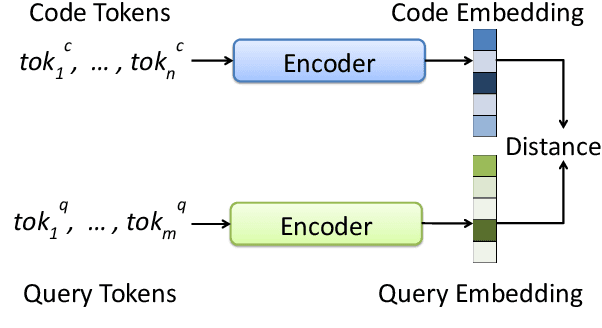
BERT2Code: Can Pretrained Language Models be Leveraged for Code Search?
Apr 16, 2021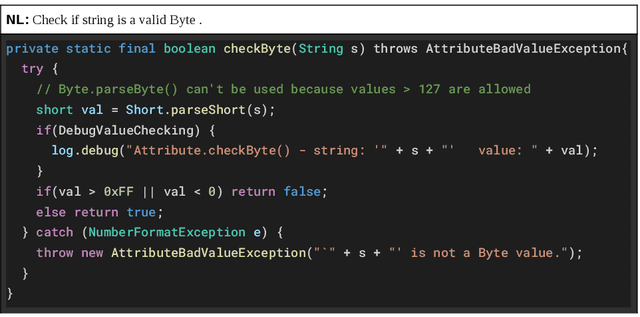
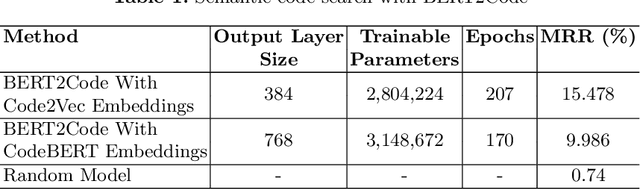
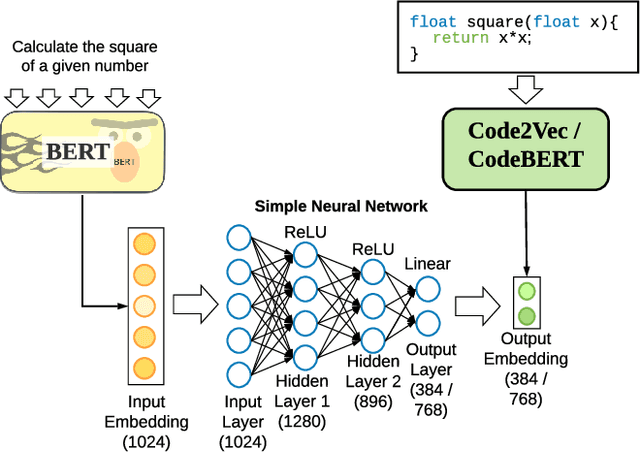

Millions of repetitive code snippets are submitted to code repositories every day. To search from these large codebases using simple natural language queries would allow programmers to ideate, prototype, and develop easier and faster. Although the existing methods have shown good performance in searching codes when the natural language description contains keywords from the code, they are still far behind in searching codes based on the semantic meaning of the natural language query and semantic structure of the code. In recent years, both natural language and programming language research communities have created techniques to embed them in vector spaces. In this work, we leverage the efficacy of these embedding models using a simple, lightweight 2-layer neural network in the task of semantic code search. We show that our model learns the inherent relationship between the embedding spaces and further probes into the scope of improvement by empirically analyzing the embedding methods. In this analysis, we show that the quality of the code embedding model is the bottleneck for our model's performance, and discuss future directions of study in this area.
BanglaBERT: Combating Embedding Barrier for Low-Resource Language Understanding
Jan 01, 2021Pre-training language models on large volume of data with self-supervised objectives has become a standard practice in natural language processing. However, most such state-of-the-art models are available in only English and other resource-rich languages. Even in multilingual models, which are trained on hundreds of languages, low-resource ones still remain underrepresented. Bangla, the seventh most widely spoken language in the world, is still low in terms of resources. Few downstream task datasets for language understanding in Bangla are publicly available, and there is a clear shortage of good quality data for pre-training. In this work, we build a Bangla natural language understanding model pre-trained on 18.6 GB data we crawled from top Bangla sites on the internet. We introduce a new downstream task dataset and benchmark on four tasks on sentence classification, document classification, natural language understanding, and sequence tagging. Our model outperforms multilingual baselines and previous state-of-the-art results by 1-6%. In the process, we identify a major shortcoming of multilingual models that hurt performance for low-resource languages that don't share writing scripts with any high resource one, which we name the `Embedding Barrier'. We perform extensive experiments to study this barrier. We release all our datasets and pre-trained models to aid future NLP research on Bangla and other low-resource languages. Our code and data are available at https://github.com/csebuetnlp/banglabert.
Holistic static and animated 3D scene generation from diverse text descriptions
Oct 04, 2020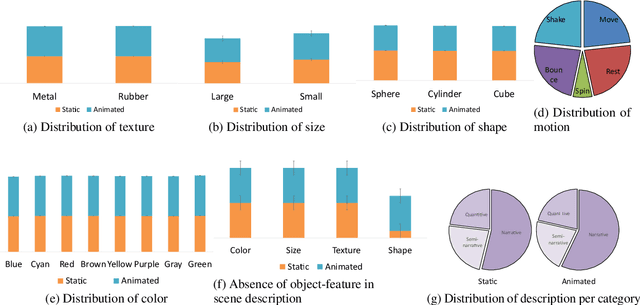


We propose a framework for holistic static and animated 3D scene generation from diverse text descriptions. Prior works of scene generation rely on static rule-based entity extraction from natural language description. However, this limits the usability of a practical solution. To overcome this limitation, we use one of state-of-the-art architecture - TransformerXL. Instead of rule-based extraction, our framework leverages the rich contextual encoding which allows us to process a larger range (diverse) of possible natural language descriptions. We empirically show how our proposed mechanism generalizes even on novel combinations of object-features during inference. We also show how our framework can jointly generate static and animated 3D scene efficiently. We modify CLEVR to generate a large, scalable dataset - Integrated static and animated 3D scene (Iscene). Data preparation code and pre-trained model available at - https://github.com/oaishi/3DScene_from_text.
A Benchmark Study on Machine Learning Methods for Fake News Detection
May 12, 2019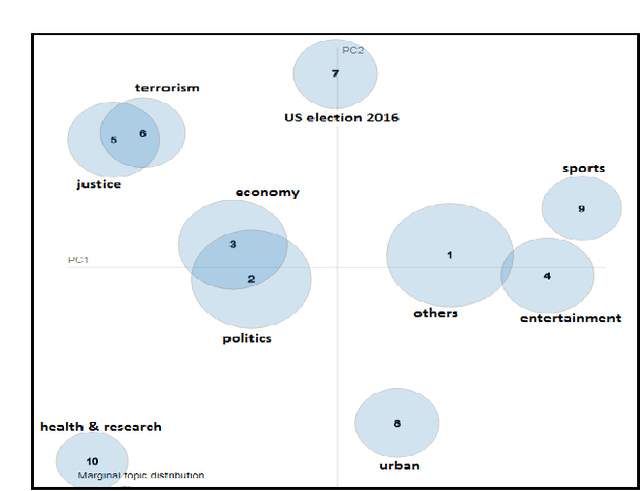
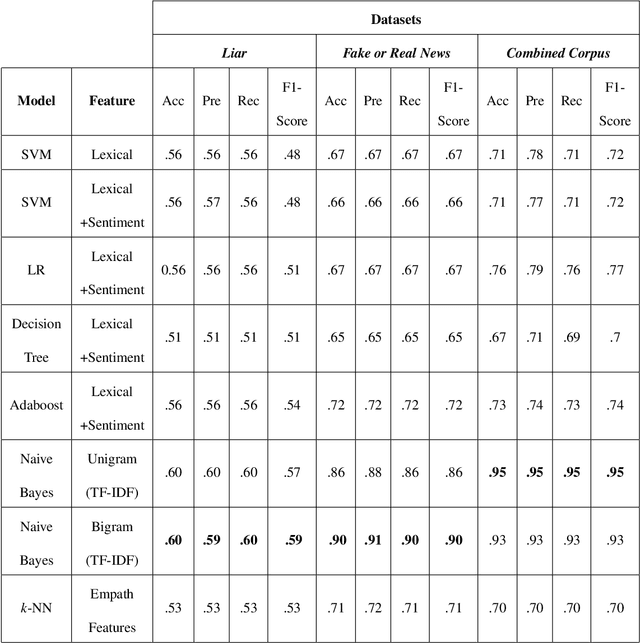
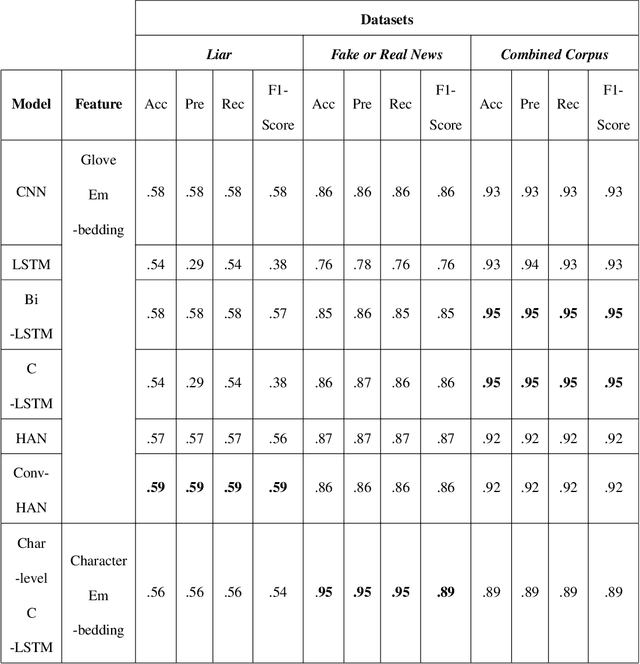
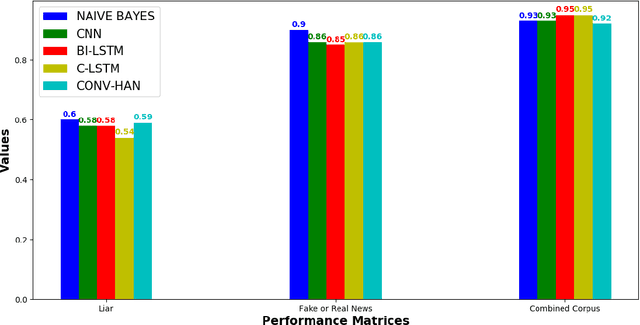
The proliferation of fake news and its propagation on social media have become a major concern due to its ability to create devastating impacts. Different machine learning approaches have been attempted to detect it. However, most of those focused on a special type of news (such as political) and did not apply many advanced techniques. In this research, we conduct a benchmark study to assess the performance of different applicable approaches on three different datasets where the largest and most diversified one was developed by us. We also implemented some advanced deep learning models that have shown promising results.