 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Noise Reduction Methods in Sentiment Analysis on Noisy Bangla Texts
Jan 29, 2024



While Bangla is considered a language with limited resources, sentiment analysis has been a subject of extensive research in the literature. Nevertheless, there is a scarcity of exploration into sentiment analysis specifically in the realm of noisy Bangla texts. In this paper, we introduce a dataset (NC-SentNoB) that we annotated manually to identify ten different types of noise found in a pre-existing sentiment analysis dataset comprising of around 15K noisy Bangla texts. At first, given an input noisy text, we identify the noise type, addressing this as a multi-label classification task. Then, we introduce baseline noise reduction methods to alleviate noise prior to conducting sentiment analysis. Finally, we assess the performance of fine-tuned sentiment analysis models with both noisy and noise-reduced texts to make comparisons. The experimental findings indicate that the noise reduction methods utilized are not satisfactory, highlighting the need for more suitable noise reduction methods in future research endeavors. We have made the implementation and dataset presented in this paper publicly available at https://github.com/ktoufiquee/A-Comparative-Analysis-of-Noise-Reduction-Methods-in-Sentiment-Analysis-on-Noisy-Bangla-Texts
Towards Automated Recipe Genre Classification using Semi-Supervised Learning
Oct 24, 2023
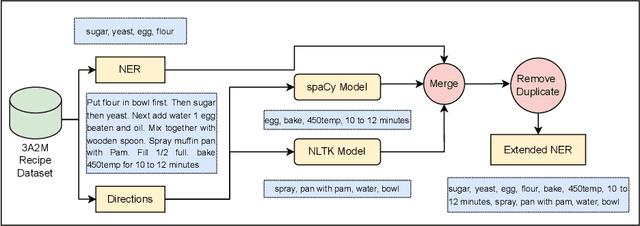

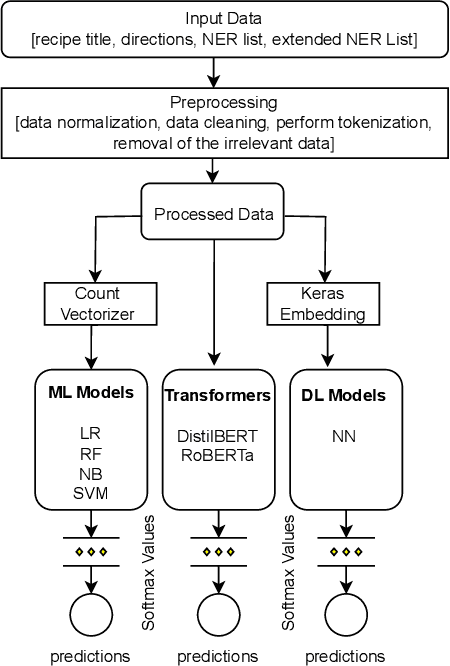
Sharing cooking recipes is a great way to exchange culinary ideas and provide instructions for food preparation. However, categorizing raw recipes found online into appropriate food genres can be challenging due to a lack of adequate labeled data. In this study, we present a dataset named the ``Assorted, Archetypal, and Annotated Two Million Extended (3A2M+) Cooking Recipe Dataset" that contains two million culinary recipes labeled in respective categories with extended named entities extracted from recipe descriptions. This collection of data includes various features such as title, NER, directions, and extended NER, as well as nine different labels representing genres including bakery, drinks, non-veg, vegetables, fast food, cereals, meals, sides, and fusions. The proposed pipeline named 3A2M+ extends the size of the Named Entity Recognition (NER) list to address missing named entities like heat, time or process from the recipe directions using two NER extraction tools. 3A2M+ dataset provides a comprehensive solution to the various challenging recipe-related tasks, including classification, named entity recognition, and recipe generation. Furthermore, we have demonstrated traditional machine learning, deep learning and pre-trained language models to classify the recipes into their corresponding genre and achieved an overall accuracy of 98.6\%. Our investigation indicates that the title feature played a more significant role in classifying the genre.
Evaluating the Reliability of CNN Models on Classifying Traffic and Road Signs using LIME
Sep 11, 2023


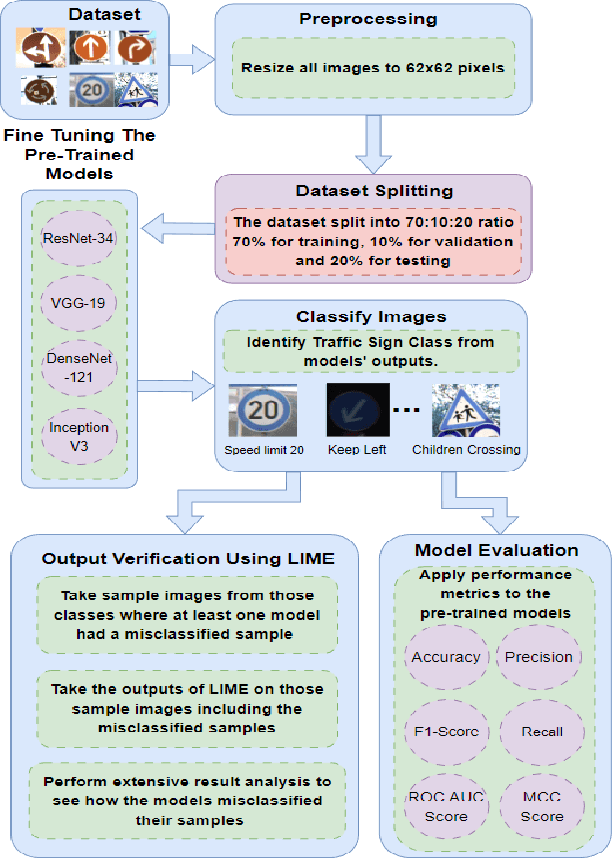
The objective of this investigation is to evaluate and contrast the effectiveness of four state-of-the-art pre-trained models, ResNet-34, VGG-19, DenseNet-121, and Inception V3, in classifying traffic and road signs with the utilization of the GTSRB public dataset. The study focuses on evaluating the accuracy of these models' predictions as well as their ability to employ appropriate features for image categorization. To gain insights into the strengths and limitations of the model's predictions, the study employs the local interpretable model-agnostic explanations (LIME) framework. The findings of this experiment indicate that LIME is a crucial tool for improving the interpretability and dependability of machine learning models for image identification, regardless of the models achieving an f1 score of 0.99 on classifying traffic and road signs. The conclusion of this study has important ramifications for how these models are used in practice, as it is crucial to ensure that model predictions are founded on the pertinent image features.
Contrastive Learning for API Aspect Analysis
Aug 14, 2023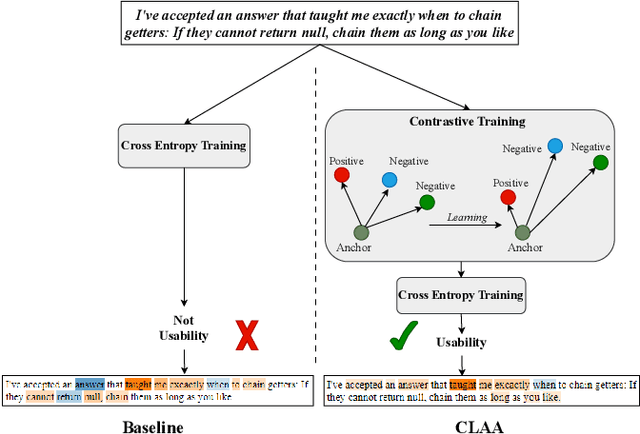



We present a novel approach - CLAA - for API aspect detection in API reviews that utilizes transformer models trained with a supervised contrastive loss objective function. We evaluate CLAA using performance and impact analysis. For performance analysis, we utilized a benchmark dataset on developer discussions collected from Stack Overflow and compare the results to those obtained using state-of-the-art transformer models. Our experiments show that contrastive learning can significantly improve the performance of transformer models in detecting aspects such as Performance, Security, Usability, and Documentation. For impact analysis, we performed empirical and developer study. On a randomly selected and manually labeled 200 online reviews, CLAA achieved 92% accuracy while the SOTA baseline achieved 81.5%. According to our developer study involving 10 participants, the use of 'Stack Overflow + CLAA' resulted in increased accuracy and confidence during API selection. Replication package: https://github.com/disa-lab/Contrastive-Learning-API-Aspect-ASE2023
Bengali Fake Reviews: A Benchmark Dataset and Detection System
Aug 03, 2023
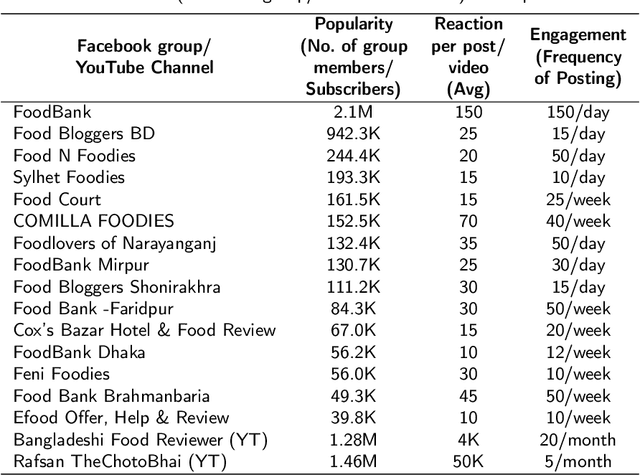
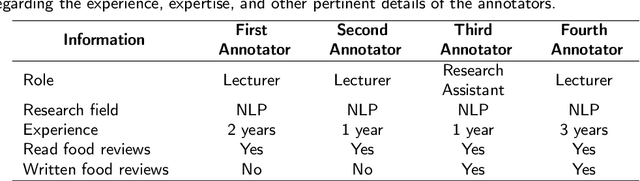
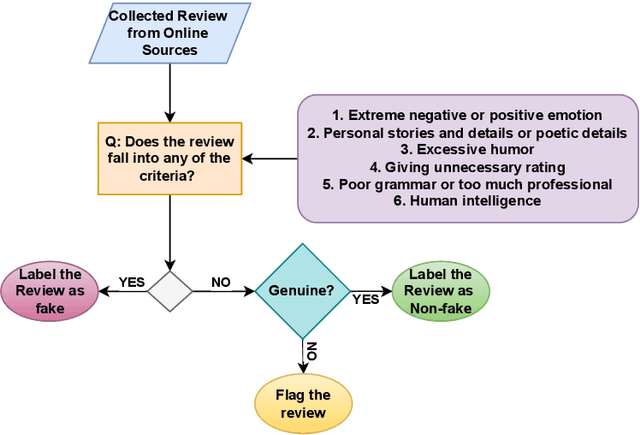
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Rank Your Summaries: Enhancing Bengali Text Summarization via Ranking-based Approach
Jul 14, 2023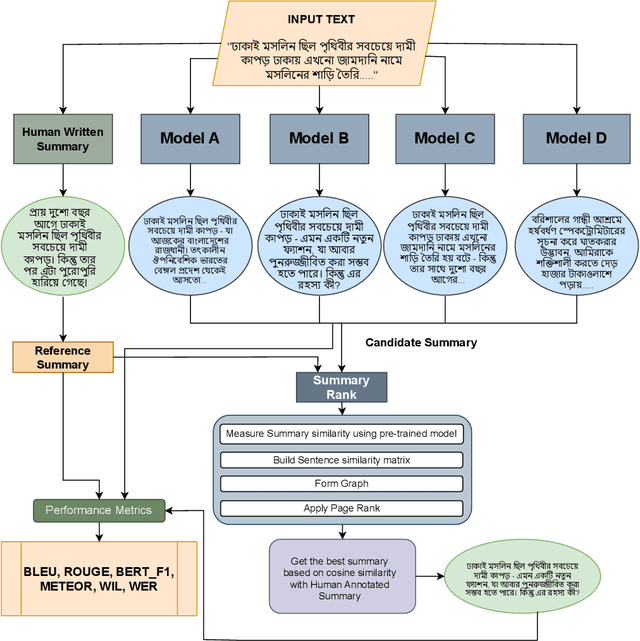



With the increasing need for text summarization techniques that are both efficient and accurate, it becomes crucial to explore avenues that enhance the quality and precision of pre-trained models specifically tailored for summarizing Bengali texts. When it comes to text summarization tasks, there are numerous pre-trained transformer models at one's disposal. Consequently, it becomes quite a challenge to discern the most informative and relevant summary for a given text among the various options generated by these pre-trained summarization models. This paper aims to identify the most accurate and informative summary for a given text by utilizing a simple but effective ranking-based approach that compares the output of four different pre-trained Bengali text summarization models. The process begins by carrying out preprocessing of the input text that involves eliminating unnecessary elements such as special characters and punctuation marks. Next, we utilize four pre-trained summarization models to generate summaries, followed by applying a text ranking algorithm to identify the most suitable summary. Ultimately, the summary with the highest ranking score is chosen as the final one. To evaluate the effectiveness of this approach, the generated summaries are compared against human-annotated summaries using standard NLG metrics such as BLEU, ROUGE, BERTScore, WIL, WER, and METEOR. Experimental results suggest that by leveraging the strengths of each pre-trained transformer model and combining them using a ranking-based approach, our methodology significantly improves the accuracy and effectiveness of the Bengali text summarization.
Gastrointestinal Disease Classification through Explainable and Cost-Sensitive Deep Neural Networks with Supervised Contrastive Learning
Jul 14, 2023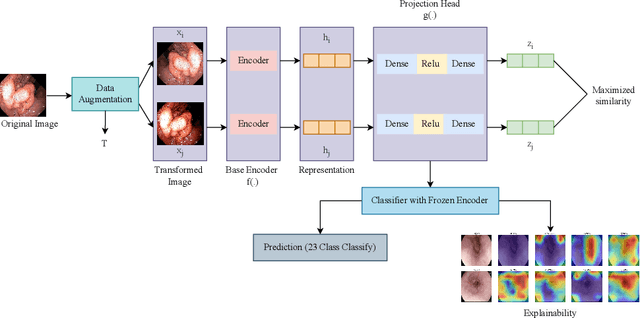
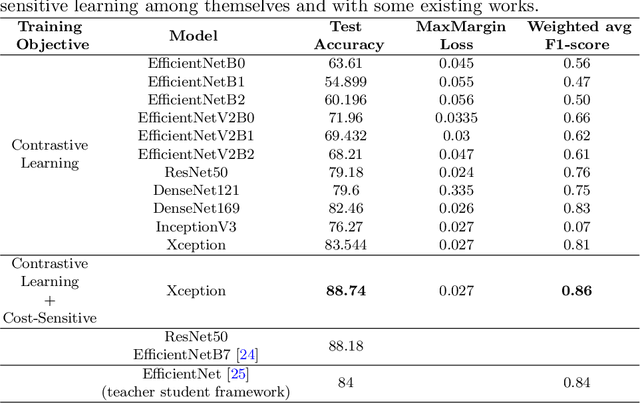
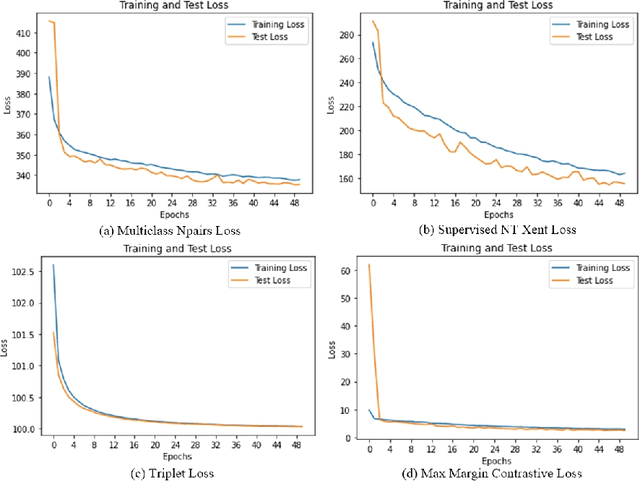
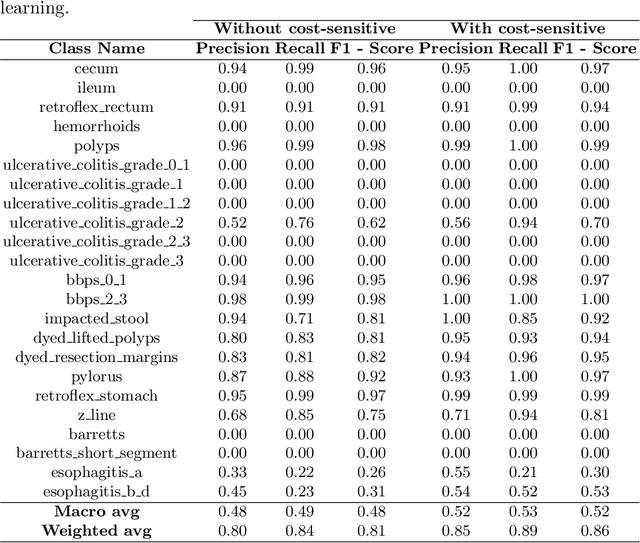
Gastrointestinal diseases pose significant healthcare chall-enges as they manifest in diverse ways and can lead to potential complications. Ensuring precise and timely classification of these diseases is pivotal in guiding treatment choices and enhancing patient outcomes. This paper introduces a novel approach on classifying gastrointestinal diseases by leveraging cost-sensitive pre-trained deep convolutional neural network (CNN) architectures with supervised contrastive learning. Our approach enables the network to learn representations that capture vital disease-related features, while also considering the relationships of similarity between samples. To tackle the challenges posed by imbalanced datasets and the cost-sensitive nature of misclassification errors in healthcare, we incorporate cost-sensitive learning. By assigning distinct costs to misclassifications based on the disease class, we prioritize accurate classification of critical conditions. Furthermore, we enhance the interpretability of our model by integrating gradient-based techniques from explainable artificial intelligence (AI). This inclusion provides valuable insights into the decision-making process of the network, aiding in understanding the features that contribute to disease classification. To assess the effectiveness of our proposed approach, we perform extensive experiments on a comprehensive gastrointestinal disease dataset, such as the Hyper-Kvasir dataset. Through thorough comparisons with existing works, we demonstrate the strong classification accuracy, robustness and interpretability of our model. We have made the implementation of our proposed approach publicly available at https://github.com/dibya404/Gastrointestinal-Disease-Classification-through-Explainable-and-Cost-Sensitive-DNN-with-SCL
Tackling Fake News in Bengali: Unraveling the Impact of Summarization vs. Augmentation on Pre-trained Language Models
Jul 13, 2023



With the rise of social media and online news sources, fake news has become a significant issue globally. However, the detection of fake news in low resource languages like Bengali has received limited attention in research. In this paper, we propose a methodology consisting of four distinct approaches to classify fake news articles in Bengali using summarization and augmentation techniques with five pre-trained language models. Our approach includes translating English news articles and using augmentation techniques to curb the deficit of fake news articles. Our research also focused on summarizing the news to tackle the token length limitation of BERT based models. Through extensive experimentation and rigorous evaluation, we show the effectiveness of summarization and augmentation in the case of Bengali fake news detection. We evaluated our models using three separate test datasets. The BanglaBERT Base model, when combined with augmentation techniques, achieved an impressive accuracy of 96% on the first test dataset. On the second test dataset, the BanglaBERT model, trained with summarized augmented news articles achieved 97% accuracy. Lastly, the mBERT Base model achieved an accuracy of 86% on the third test dataset which was reserved for generalization performance evaluation. The datasets and implementations are available at https://github.com/arman-sakif/Bengali-Fake-News-Detection
Interpretable Multi Labeled Bengali Toxic Comments Classification using Deep Learning
Apr 08, 2023



This paper presents a deep learning-based pipeline for categorizing Bengali toxic comments, in which at first a binary classification model is used to determine whether a comment is toxic or not, and then a multi-label classifier is employed to determine which toxicity type the comment belongs to. For this purpose, we have prepared a manually labeled dataset consisting of 16,073 instances among which 8,488 are Toxic and any toxic comment may correspond to one or more of the six toxic categories - vulgar, hate, religious, threat, troll, and insult simultaneously. Long Short Term Memory (LSTM) with BERT Embedding achieved 89.42% accuracy for the binary classification task while as a multi-label classifier, a combination of Convolutional Neural Network and Bi-directional Long Short Term Memory (CNN-BiLSTM) with attention mechanism achieved 78.92% accuracy and 0.86 as weighted F1-score. To explain the predictions and interpret the word feature importance during classification by the proposed models, we utilized Local Interpretable Model-Agnostic Explanations (LIME) framework. We have made our dataset public and can be accessed at - https://github.com/deepu099cse/Multi-Labeled-Bengali-Toxic-Comments-Classification
Bengali Fake Review Detection using Semi-supervised Generative Adversarial Networks
Apr 05, 2023



This paper investigates the potential of semi-supervised Generative Adversarial Networks (GANs) to fine-tune pretrained language models in order to classify Bengali fake reviews from real reviews with a few annotated data. With the rise of social media and e-commerce, the ability to detect fake or deceptive reviews is becoming increasingly important in order to protect consumers from being misled by false information. Any machine learning model will have trouble identifying a fake review, especially for a low resource language like Bengali. We have demonstrated that the proposed semi-supervised GAN-LM architecture (generative adversarial network on top of a pretrained language model) is a viable solution in classifying Bengali fake reviews as the experimental results suggest that even with only 1024 annotated samples, BanglaBERT with semi-supervised GAN (SSGAN) achieved an accuracy of 83.59% and a f1-score of 84.89% outperforming other pretrained language models - BanglaBERT generator, Bangla BERT Base and Bangla-Electra by almost 3%, 4% and 10% respectively in terms of accuracy. The experiments were conducted on a manually labeled food review dataset consisting of total 6014 real and fake reviews collected from various social media groups. Researchers that are experiencing difficulty recognizing not just fake reviews but other classification issues owing to a lack of labeled data may find a solution in our proposed methodology.