 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank Your Summaries: Enhancing Bengali Text Summarization via Ranking-based Approach
Paper and Code
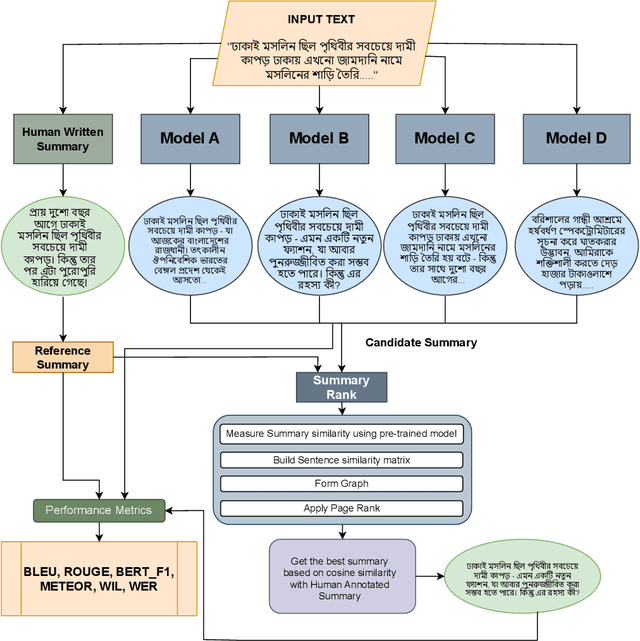



With the increasing need for text summarization techniques that are both efficient and accurate, it becomes crucial to explore avenues that enhance the quality and precision of pre-trained models specifically tailored for summarizing Bengali texts. When it comes to text summarization tasks, there are numerous pre-trained transformer models at one's disposal. Consequently, it becomes quite a challenge to discern the most informative and relevant summary for a given text among the various options generated by these pre-trained summarization models. This paper aims to identify the most accurate and informative summary for a given text by utilizing a simple but effective ranking-based approach that compares the output of four different pre-trained Bengali text summarization models. The process begins by carrying out preprocessing of the input text that involves eliminating unnecessary elements such as special characters and punctuation marks. Next, we utilize four pre-trained summarization models to generate summaries, followed by applying a text ranking algorithm to identify the most suitable summary. Ultimately, the summary with the highest ranking score is chosen as the final one. To evaluate the effectiveness of this approach, the generated summaries are compared against human-annotated summaries using standard NLG metrics such as BLEU, ROUGE, BERTScore, WIL, WER, and METEOR. Experimental results suggest that by leveraging the strengths of each pre-trained transformer model and combining them using a ranking-based approach, our methodology significantly improves the accuracy and effectiveness of the Bengali text summarization.