 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Noise Reduction Methods in Sentiment Analysis on Noisy Bangla Texts
Jan 29, 2024



While Bangla is considered a language with limited resources, sentiment analysis has been a subject of extensive research in the literature. Nevertheless, there is a scarcity of exploration into sentiment analysis specifically in the realm of noisy Bangla texts. In this paper, we introduce a dataset (NC-SentNoB) that we annotated manually to identify ten different types of noise found in a pre-existing sentiment analysis dataset comprising of around 15K noisy Bangla texts. At first, given an input noisy text, we identify the noise type, addressing this as a multi-label classification task. Then, we introduce baseline noise reduction methods to alleviate noise prior to conducting sentiment analysis. Finally, we assess the performance of fine-tuned sentiment analysis models with both noisy and noise-reduced texts to make comparisons. The experimental findings indicate that the noise reduction methods utilized are not satisfactory, highlighting the need for more suitable noise reduction methods in future research endeavors. We have made the implementation and dataset presented in this paper publicly available at https://github.com/ktoufiquee/A-Comparative-Analysis-of-Noise-Reduction-Methods-in-Sentiment-Analysis-on-Noisy-Bangla-Texts
Bengali Intent Classification with Generative Adversarial BERT
Dec 17, 2023



Intent classification is a fundamental task in natural language understanding, aiming to categorize user queries or sentences into predefined classes to understand user intent. The most challenging aspect of this particular task lies in effectively incorporating all possible classes of intent into a dataset while ensuring adequate linguistic variation. Plenty of research has been conducted in the related domains in rich-resource languages like English. In this study, we introduce BNIntent30, a comprehensive Bengali intent classification dataset containing 30 intent classes. The dataset is excerpted and translated from the CLINIC150 dataset containing a diverse range of user intents categorized over 150 classes. Furthermore, we propose a novel approach for Bengali intent classification using Generative Adversarial BERT to evaluate the proposed dataset, which we call GAN-BnBERT. Our approach leverages the power of BERT-based contextual embeddings to capture salient linguistic features and contextual information from the text data, while the generative adversarial network (GAN) component complements the model's ability to learn diverse representations of existing intent classes through generative modeling. Our experimental results demonstrate that the GAN-BnBERT model achieves superior performance on the newly introduced BNIntent30 dataset, surpassing the existing Bi-LSTM and the stand-alone BERT-based classification model.
Bengali License Plate Recognition: Unveiling Clarity with CNN and GFP-GAN
Dec 17, 2023



Automated License Plate Recognition(ALPR) is a system that automatically reads and extracts data from vehicle license plates using image processing and computer vision techniques. The Goal of LPR is to identify and read the license plate number accurately and quickly, even under challenging, conditions such as poor lighting, angled or obscured plates, and different plate fonts and layouts. The proposed method consists of processing the Bengali low-resolution blurred license plates and identifying the plate's characters. The processes include image restoration using GFPGAN, Maximizing contrast, Morphological image processing like dilation, feature extraction and Using Convolutional Neural Networks (CNN), character segmentation and recognition are accomplished. A dataset of 1292 images of Bengali digits and characters was prepared for this project.
An Interpretable Systematic Review of Machine Learning Models for Predictive Maintenance of Aircraft Engine
Sep 23, 2023
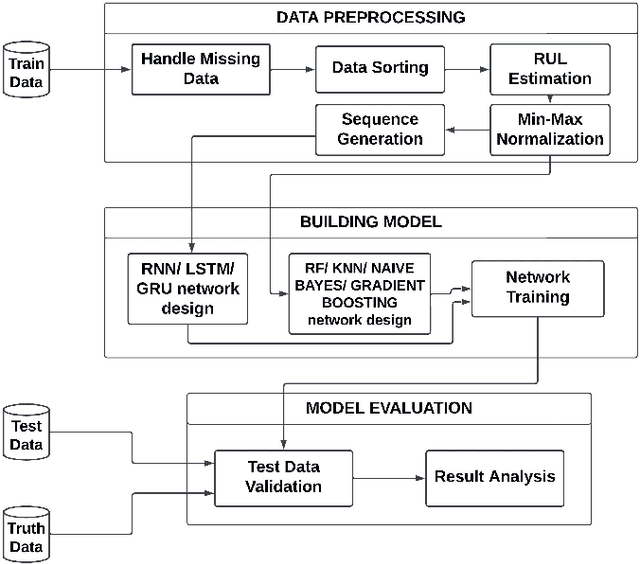

This paper presents an interpretable review of various machine learning and deep learning models to predict the maintenance of aircraft engine to avoid any kind of disaster. One of the advantages of the strategy is that it can work with modest datasets. In this study, sensor data is utilized to predict aircraft engine failure within a predetermined number of cycles using LSTM, Bi-LSTM, RNN, Bi-RNN GRU, Random Forest, KNN, Naive Bayes, and Gradient Boosting. We explain how deep learning and machine learning can be used to generate predictions in predictive maintenance using a straightforward scenario with just one data source. We applied lime to the models to help us understand why machine learning models did not perform well than deep learning models. An extensive analysis of the model's behavior is presented for several test data to understand the black box scenario of the models. A lucrative accuracy of 97.8%, 97.14%, and 96.42% are achieved by GRU, Bi-LSTM, and LSTM respectively which denotes the capability of the models to predict maintenance at an early stage.
Evaluating the Reliability of CNN Models on Classifying Traffic and Road Signs using LIME
Sep 11, 2023


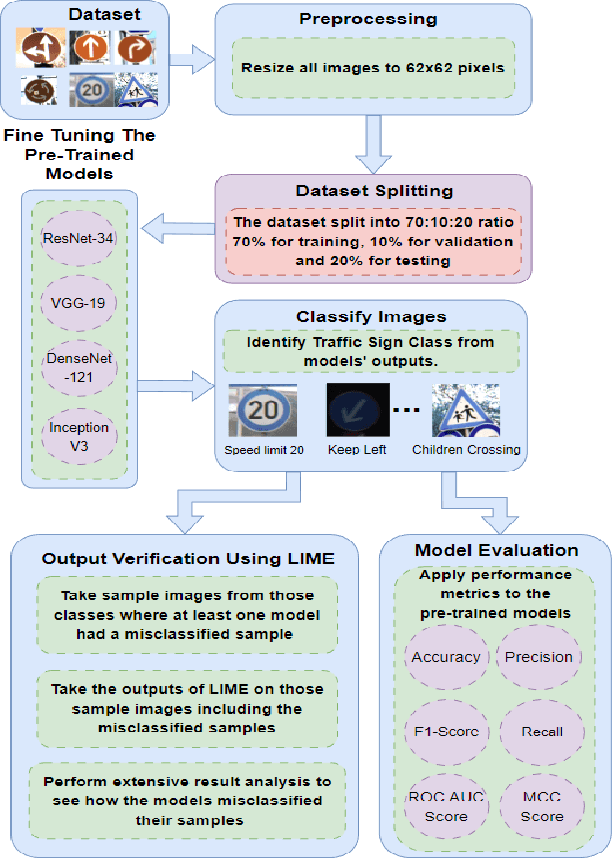
The objective of this investigation is to evaluate and contrast the effectiveness of four state-of-the-art pre-trained models, ResNet-34, VGG-19, DenseNet-121, and Inception V3, in classifying traffic and road signs with the utilization of the GTSRB public dataset. The study focuses on evaluating the accuracy of these models' predictions as well as their ability to employ appropriate features for image categorization. To gain insights into the strengths and limitations of the model's predictions, the study employs the local interpretable model-agnostic explanations (LIME) framework. The findings of this experiment indicate that LIME is a crucial tool for improving the interpretability and dependability of machine learning models for image identification, regardless of the models achieving an f1 score of 0.99 on classifying traffic and road signs. The conclusion of this study has important ramifications for how these models are used in practice, as it is crucial to ensure that model predictions are founded on the pertinent image features.
Bengali Fake Reviews: A Benchmark Dataset and Detection System
Aug 03, 2023
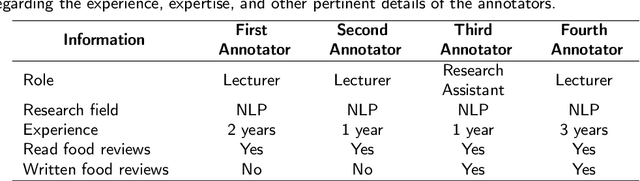
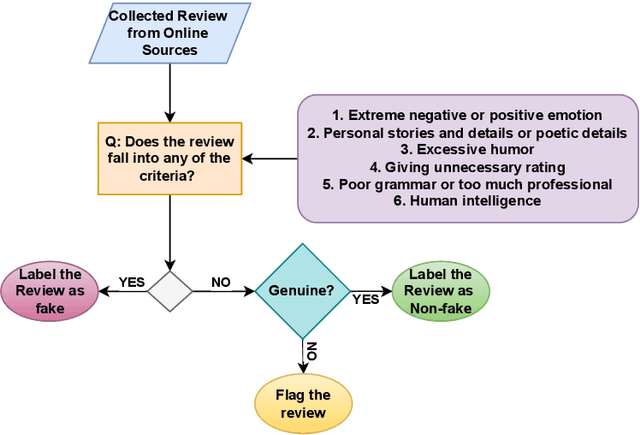
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Rank Your Summaries: Enhancing Bengali Text Summarization via Ranking-based Approach
Jul 14, 2023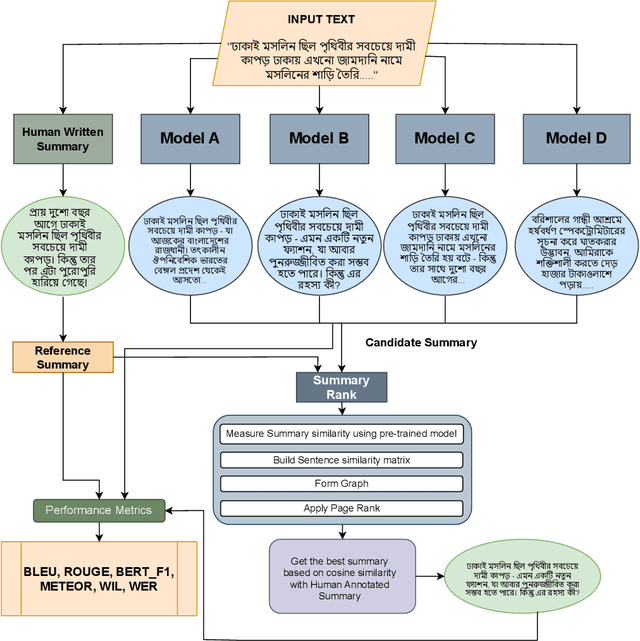



With the increasing need for text summarization techniques that are both efficient and accurate, it becomes crucial to explore avenues that enhance the quality and precision of pre-trained models specifically tailored for summarizing Bengali texts. When it comes to text summarization tasks, there are numerous pre-trained transformer models at one's disposal. Consequently, it becomes quite a challenge to discern the most informative and relevant summary for a given text among the various options generated by these pre-trained summarization models. This paper aims to identify the most accurate and informative summary for a given text by utilizing a simple but effective ranking-based approach that compares the output of four different pre-trained Bengali text summarization models. The process begins by carrying out preprocessing of the input text that involves eliminating unnecessary elements such as special characters and punctuation marks. Next, we utilize four pre-trained summarization models to generate summaries, followed by applying a text ranking algorithm to identify the most suitable summary. Ultimately, the summary with the highest ranking score is chosen as the final one. To evaluate the effectiveness of this approach, the generated summaries are compared against human-annotated summaries using standard NLG metrics such as BLEU, ROUGE, BERTScore, WIL, WER, and METEOR. Experimental results suggest that by leveraging the strengths of each pre-trained transformer model and combining them using a ranking-based approach, our methodology significantly improves the accuracy and effectiveness of the Bengali text summarization.
Bengali Fake Review Detection using Semi-supervised Generative Adversarial Networks
Apr 05, 2023



This paper investigates the potential of semi-supervised Generative Adversarial Networks (GANs) to fine-tune pretrained language models in order to classify Bengali fake reviews from real reviews with a few annotated data. With the rise of social media and e-commerce, the ability to detect fake or deceptive reviews is becoming increasingly important in order to protect consumers from being misled by false information. Any machine learning model will have trouble identifying a fake review, especially for a low resource language like Bengali. We have demonstrated that the proposed semi-supervised GAN-LM architecture (generative adversarial network on top of a pretrained language model) is a viable solution in classifying Bengali fake reviews as the experimental results suggest that even with only 1024 annotated samples, BanglaBERT with semi-supervised GAN (SSGAN) achieved an accuracy of 83.59% and a f1-score of 84.89% outperforming other pretrained language models - BanglaBERT generator, Bangla BERT Base and Bangla-Electra by almost 3%, 4% and 10% respectively in terms of accuracy. The experiments were conducted on a manually labeled food review dataset consisting of total 6014 real and fake reviews collected from various social media groups. Researchers that are experiencing difficulty recognizing not just fake reviews but other classification issues owing to a lack of labeled data may find a solution in our proposed methodology.
Effectiveness of Transformer Models on IoT Security Detection in StackOverflow Discussions
Jul 29, 2022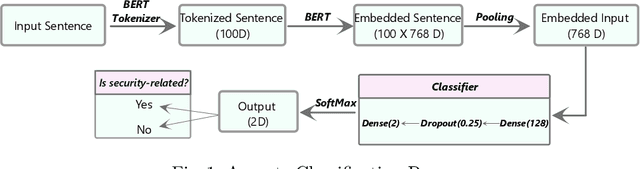
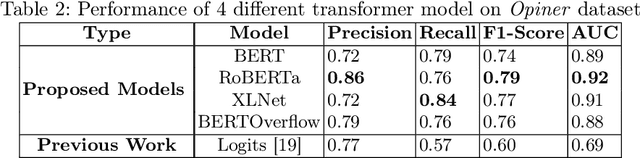
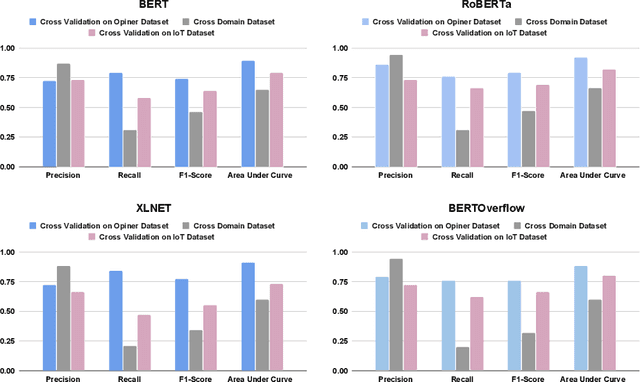
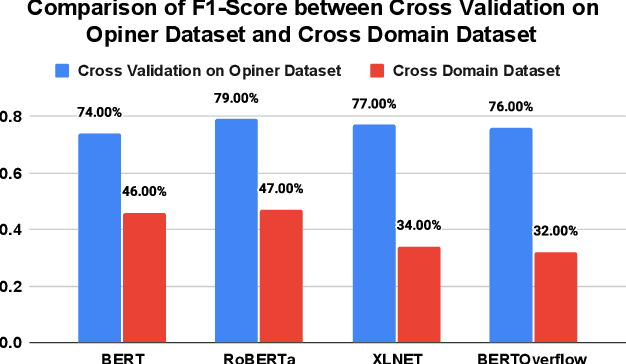
The Internet of Things (IoT) is an emerging concept that directly links to the billions of physical items, or "things", that are connected to the Internet and are all gathering and exchanging information between devices and systems. However, IoT devices were not built with security in mind, which might lead to security vulnerabilities in a multi-device system. Traditionally, we investigated IoT issues by polling IoT developers and specialists. This technique, however, is not scalable since surveying all IoT developers is not feasible. Another way to look into IoT issues is to look at IoT developer discussions on major online development forums like Stack Overflow (SO). However, finding discussions that are relevant to IoT issues is challenging since they are frequently not categorized with IoT-related terms. In this paper, we present the "IoT Security Dataset", a domain-specific dataset of 7147 samples focused solely on IoT security discussions. As there are no automated tools to label these samples, we manually labeled them. We further employed multiple transformer models to automatically detect security discussions. Through rigorous investigations, we found that IoT security discussions are different and more complex than traditional security discussions. We demonstrated a considerable performance loss (up to 44%) of transformer models on cross-domain datasets when we transferred knowledge from a general-purpose dataset "Opiner", supporting our claim. Thus, we built a domain-specific IoT security detector with an F1-Score of 0.69. We have made the dataset public in the hope that developers would learn more about the security discussion and vendors would enhance their concerns about product security.