 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Bengali Math Word Problem Solving with Chain of Thought Reasoning
May 27, 2025Solving Bengali Math Word Problems (MWPs) remains a major challenge in natural language processing (NLP) due to the language's low-resource status and the multi-step reasoning required. Existing models struggle with complex Bengali MWPs, largely because no human-annotated Bengali dataset has previously addressed this task. This gap has limited progress in Bengali mathematical reasoning. To address this, we created SOMADHAN, a dataset of 8792 complex Bengali MWPs with manually written, step-by-step solutions. We designed this dataset to support reasoning-focused evaluation and model development in a linguistically underrepresented context. Using SOMADHAN, we evaluated a range of large language models (LLMs) - including GPT-4o, GPT-3.5 Turbo, LLaMA series models, Deepseek, and Qwen - through both zero-shot and few-shot prompting with and without Chain of Thought (CoT) reasoning. CoT prompting consistently improved performance over standard prompting, especially in tasks requiring multi-step logic. LLaMA-3.3 70B achieved the highest accuracy of 88% with few-shot CoT prompting. We also applied Low-Rank Adaptation (LoRA) to fine-tune models efficiently, enabling them to adapt to Bengali MWPs with minimal computational cost. Our work fills a critical gap in Bengali NLP by providing a high-quality reasoning dataset and a scalable framework for solving complex MWPs. We aim to advance equitable research in low-resource languages and enhance reasoning capabilities in educational and language technologies.
Empowering Bengali Education with AI: Solving Bengali Math Word Problems through Transformer Models
Jan 05, 2025



Mathematical word problems (MWPs) involve the task of converting textual descriptions into mathematical equations. This poses a significant challenge in natural language processing, particularly for low-resource languages such as Bengali. This paper addresses this challenge by developing an innovative approach to solving Bengali MWPs using transformer-based models, including Basic Transformer, mT5, BanglaT5, and mBART50. To support this effort, the "PatiGonit" dataset was introduced, containing 10,000 Bengali math problems, and these models were fine-tuned to translate the word problems into equations accurately. The evaluation revealed that the mT5 model achieved the highest accuracy of 97.30%, demonstrating the effectiveness of transformer models in this domain. This research marks a significant step forward in Bengali natural language processing, offering valuable methodologies and resources for educational AI tools. By improving math education, it also supports the development of advanced problem-solving skills for Bengali-speaking students.
On-device Federated Learning in Smartphones for Detecting Depression from Reddit Posts
Oct 17, 2024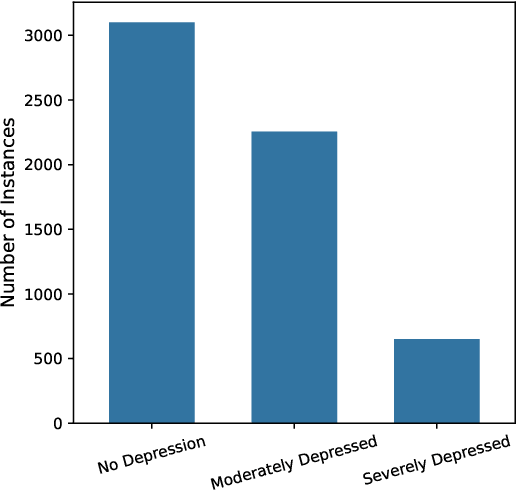
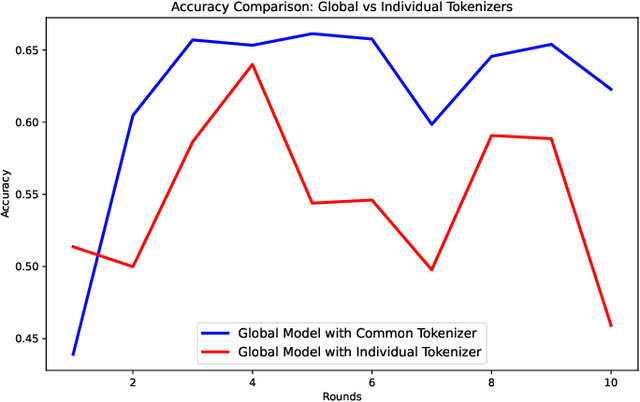
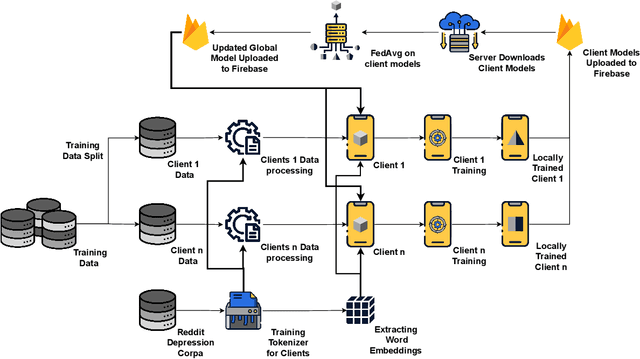
Depression detection using deep learning models has been widely explored in previous studies, especially due to the large amounts of data available from social media posts. These posts provide valuable information about individuals' mental health conditions and can be leveraged to train models and identify patterns in the data. However, distributed learning approaches have not been extensively explored in this domain. In this study, we adopt Federated Learning (FL) to facilitate decentralized training on smartphones while protecting user data privacy. We train three neural network architectures--GRU, RNN, and LSTM on Reddit posts to detect signs of depression and evaluate their performance under heterogeneous FL settings. To optimize the training process, we leverage a common tokenizer across all client devices, which reduces the computational load. Additionally, we analyze resource consumption and communication costs on smartphones to assess their impact in a real-world FL environment. Our experimental results demonstrate that the federated models achieve comparable performance to the centralized models. This study highlights the potential of FL for decentralized mental health prediction by providing a secure and efficient model training process on edge devices.
Explainable Convolutional Neural Networks for Retinal Fundus Classification and Cutting-Edge Segmentation Models for Retinal Blood Vessels from Fundus Images
May 12, 2024
Our research focuses on the critical field of early diagnosis of disease by examining retinal blood vessels in fundus images. While automatic segmentation of retinal blood vessels holds promise for early detection, accurate analysis remains challenging due to the limitations of existing methods, which often lack discrimination power and are susceptible to influences from pathological regions. Our research in fundus image analysis advances deep learning-based classification using eight pre-trained CNN models. To enhance interpretability, we utilize Explainable AI techniques such as Grad-CAM, Grad-CAM++, Score-CAM, Faster Score-CAM, and Layer CAM. These techniques illuminate the decision-making processes of the models, fostering transparency and trust in their predictions. Expanding our exploration, we investigate ten models, including TransUNet with ResNet backbones, Attention U-Net with DenseNet and ResNet backbones, and Swin-UNET. Incorporating diverse architectures such as ResNet50V2, ResNet101V2, ResNet152V2, and DenseNet121 among others, this comprehensive study deepens our insights into attention mechanisms for enhanced fundus image analysis. Among the evaluated models for fundus image classification, ResNet101 emerged with the highest accuracy, achieving an impressive 94.17%. On the other end of the spectrum, EfficientNetB0 exhibited the lowest accuracy among the models, achieving a score of 88.33%. Furthermore, in the domain of fundus image segmentation, Swin-Unet demonstrated a Mean Pixel Accuracy of 86.19%, showcasing its effectiveness in accurately delineating regions of interest within fundus images. Conversely, Attention U-Net with DenseNet201 backbone exhibited the lowest Mean Pixel Accuracy among the evaluated models, achieving a score of 75.87%.
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
May 07, 2024



Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled "entailment". If the hypothesis contradicts the premise, the pair receives the "contradiction" label. When there is insufficient evidence to establish a connection, the pair is described as "neutral". Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.
Harnessing Large Language Models Over Transformer Models for Detecting Bengali Depressive Social Media Text: A Comprehensive Study
Jan 14, 2024



In an era where the silent struggle of underdiagnosed depression pervades globally, our research delves into the crucial link between mental health and social media. This work focuses on early detection of depression, particularly in extroverted social media users, using LLMs such as GPT 3.5, GPT 4 and our proposed GPT 3.5 fine-tuned model DepGPT, as well as advanced Deep learning models(LSTM, Bi-LSTM, GRU, BiGRU) and Transformer models(BERT, BanglaBERT, SahajBERT, BanglaBERT-Base). The study categorized Reddit and X datasets into "Depressive" and "Non-Depressive" segments, translated into Bengali by native speakers with expertise in mental health, resulting in the creation of the Bengali Social Media Depressive Dataset (BSMDD). Our work provides full architecture details for each model and a methodical way to assess their performance in Bengali depressive text categorization using zero-shot and few-shot learning techniques. Our work demonstrates the superiority of SahajBERT and Bi-LSTM with FastText embeddings in their respective domains also tackles explainability issues with transformer models and emphasizes the effectiveness of LLMs, especially DepGPT, demonstrating flexibility and competence in a range of learning contexts. According to the experiment results, the proposed model, DepGPT, outperformed not only Alpaca Lora 7B in zero-shot and few-shot scenarios but also every other model, achieving a near-perfect accuracy of 0.9796 and an F1-score of 0.9804, high recall, and exceptional precision. Although competitive, GPT-3.5 Turbo and Alpaca Lora 7B show relatively poorer effectiveness in zero-shot and few-shot situations. The work emphasizes the effectiveness and flexibility of LLMs in a variety of linguistic circumstances, providing insightful information about the complex field of depression detection models.
Bengali Fake Reviews: A Benchmark Dataset and Detection System
Aug 03, 2023
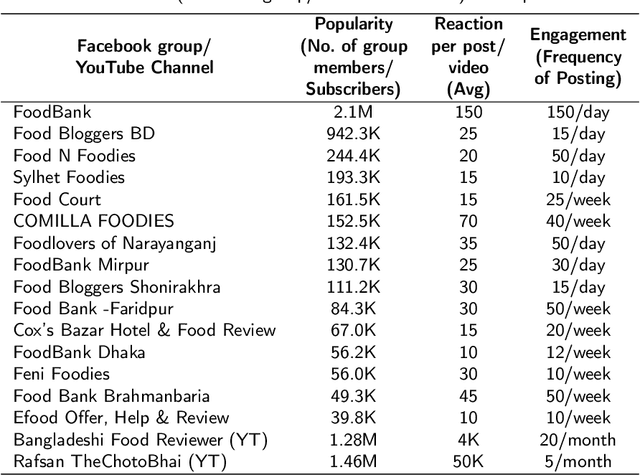
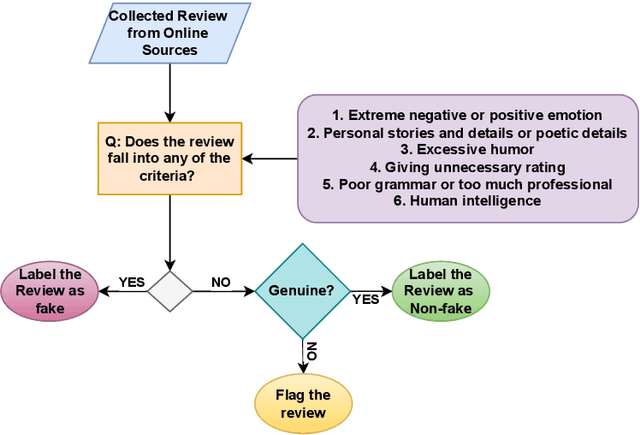
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Bengali Fake Review Detection using Semi-supervised Generative Adversarial Networks
Apr 05, 2023



This paper investigates the potential of semi-supervised Generative Adversarial Networks (GANs) to fine-tune pretrained language models in order to classify Bengali fake reviews from real reviews with a few annotated data. With the rise of social media and e-commerce, the ability to detect fake or deceptive reviews is becoming increasingly important in order to protect consumers from being misled by false information. Any machine learning model will have trouble identifying a fake review, especially for a low resource language like Bengali. We have demonstrated that the proposed semi-supervised GAN-LM architecture (generative adversarial network on top of a pretrained language model) is a viable solution in classifying Bengali fake reviews as the experimental results suggest that even with only 1024 annotated samples, BanglaBERT with semi-supervised GAN (SSGAN) achieved an accuracy of 83.59% and a f1-score of 84.89% outperforming other pretrained language models - BanglaBERT generator, Bangla BERT Base and Bangla-Electra by almost 3%, 4% and 10% respectively in terms of accuracy. The experiments were conducted on a manually labeled food review dataset consisting of total 6014 real and fake reviews collected from various social media groups. Researchers that are experiencing difficulty recognizing not just fake reviews but other classification issues owing to a lack of labeled data may find a solution in our proposed methodology.
Spam Review Detection Using Deep Learning
Nov 03, 2022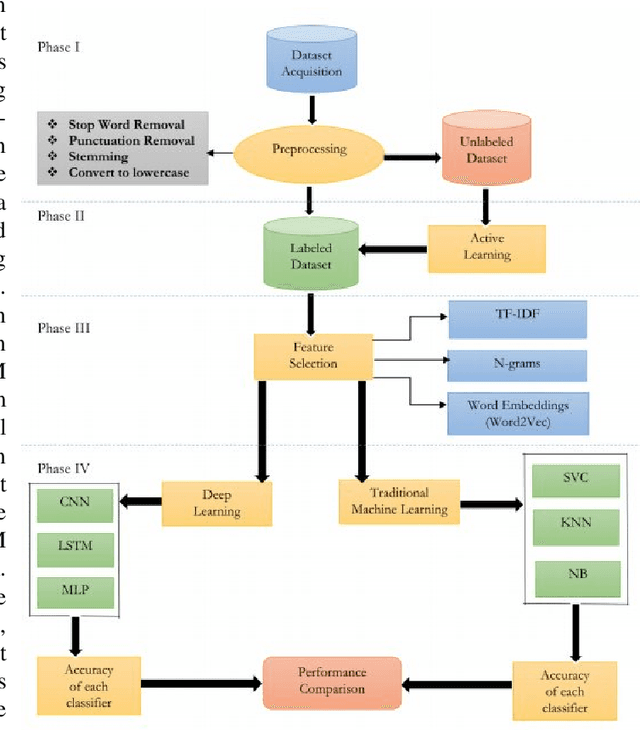
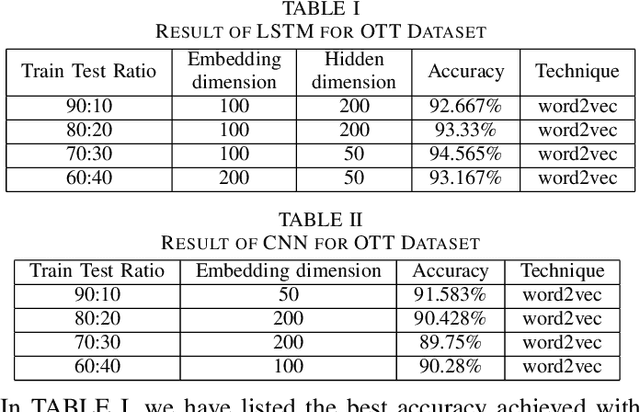
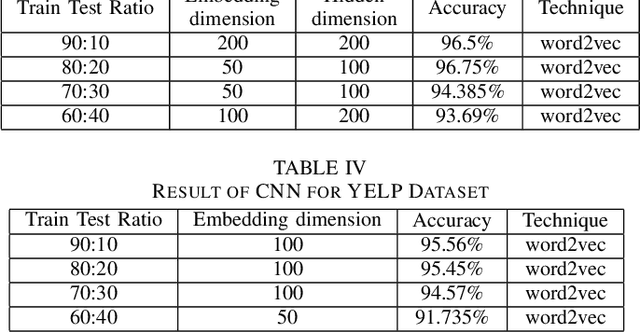

A robust and reliable system of detecting spam reviews is a crying need in todays world in order to purchase products without being cheated from online sites. In many online sites, there are options for posting reviews, and thus creating scopes for fake paid reviews or untruthful reviews. These concocted reviews can mislead the general public and put them in a perplexity whether to believe the review or not. Prominent machine learning techniques have been introduced to solve the problem of spam review detection. The majority of current research has concentrated on supervised learning methods, which require labeled data - an inadequacy when it comes to online review. Our focus in this article is to detect any deceptive text reviews. In order to achieve that we have worked with both labeled and unlabeled data and proposed deep learning methods for spam review detection which includes Multi-Layer Perceptron (MLP), Convolutional Neural Network (CNN) and a variant of Recurrent Neural Network (RNN) that is Long Short-Term Memory (LSTM). We have also applied some traditional machine learning classifiers such as Nave Bayes (NB), K Nearest Neighbor (KNN) and Support Vector Machine (SVM) to detect spam reviews and finally, we have shown the performance comparison for both traditional and deep learning classifiers.
Brain Tumor Segmentation using Enhanced U-Net Model with Empirical Analysis
Oct 24, 2022



Cancer of the brain is deadly and requires careful surgical segmentation. The brain tumors were segmented using U-Net using a Convolutional Neural Network (CNN). When looking for overlaps of necrotic, edematous, growing, and healthy tissue, it might be hard to get relevant information from the images. The 2D U-Net network was improved and trained with the BraTS datasets to find these four areas. U-Net can set up many encoder and decoder routes that can be used to get information from images that can be used in different ways. To reduce computational time, we use image segmentation to exclude insignificant background details. Experiments on the BraTS datasets show that our proposed model for segmenting brain tumors from MRI (MRI) works well. In this study, we demonstrate that the BraTS datasets for 2017, 2018, 2019, and 2020 do not significantly differ from the BraTS 2019 dataset's attained dice scores of 0.8717 (necrotic), 0.9506 (edema), and 0.9427 (enhancing).