 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineXDrama: Relevance Detection and Sentiment Analysis of Bangla YouTube Comments on Movie-Drama using Transformers: Insights from Interpretability Tool
Nov 10, 2024



In recent years, YouTube has become the leading platform for Bangla movies and dramas, where viewers express their opinions in comments that convey their sentiments about the content. However, not all comments are relevant for sentiment analysis, necessitating a filtering mechanism. We propose a system that first assesses the relevance of comments and then analyzes the sentiment of those deemed relevant. We introduce a dataset of 14,000 manually collected and preprocessed comments, annotated for relevance (relevant or irrelevant) and sentiment (positive or negative). Eight transformer models, including BanglaBERT, were used for classification tasks, with BanglaBERT achieving the highest accuracy (83.99% for relevance detection and 93.3% for sentiment analysis). The study also integrates LIME to interpret model decisions, enhancing transparency.
Assessing the Level of Toxicity Against Distinct Groups in Bangla Social Media Comments: A Comprehensive Investigation
Sep 25, 2024Social media platforms have a vital role in the modern world, serving as conduits for communication, the exchange of ideas, and the establishment of networks. However, the misuse of these platforms through toxic comments, which can range from offensive remarks to hate speech, is a concerning issue. This study focuses on identifying toxic comments in the Bengali language targeting three specific groups: transgender people, indigenous people, and migrant people, from multiple social media sources. The study delves into the intricate process of identifying and categorizing toxic language while considering the varying degrees of toxicity: high, medium, and low. The methodology involves creating a dataset, manual annotation, and employing pre-trained transformer models like Bangla-BERT, bangla-bert-base, distil-BERT, and Bert-base-multilingual-cased for classification. Diverse assessment metrics such as accuracy, recall, precision, and F1-score are employed to evaluate the model's effectiveness. The experimental findings reveal that Bangla-BERT surpasses alternative models, achieving an F1-score of 0.8903. This research exposes the complexity of toxicity in Bangla social media dialogues, revealing its differing impacts on diverse demographic groups.
Celeb-FBI: A Benchmark Dataset on Human Full Body Images and Age, Gender, Height and Weight Estimation using Deep Learning Approach
Jul 03, 2024



The scarcity of comprehensive datasets in surveillance, identification, image retrieval systems, and healthcare poses a significant challenge for researchers in exploring new methodologies and advancing knowledge in these respective fields. Furthermore, the need for full-body image datasets with detailed attributes like height, weight, age, and gender is particularly significant in areas such as fashion industry analytics, ergonomic design assessment, virtual reality avatar creation, and sports performance analysis. To address this gap, we have created the 'Celeb-FBI' dataset which contains 7,211 full-body images of individuals accompanied by detailed information on their height, age, weight, and gender. Following the dataset creation, we proceed with the preprocessing stages, including image cleaning, scaling, and the application of Synthetic Minority Oversampling Technique (SMOTE). Subsequently, utilizing this prepared dataset, we employed three deep learning approaches: Convolutional Neural Network (CNN), 50-layer ResNet, and 16-layer VGG, which are used for estimating height, weight, age, and gender from human full-body images. From the results obtained, ResNet-50 performed best for the system with an accuracy rate of 79.18% for age, 95.43% for gender, 85.60% for height and 81.91% for weight.
Explainable Convolutional Neural Networks for Retinal Fundus Classification and Cutting-Edge Segmentation Models for Retinal Blood Vessels from Fundus Images
May 12, 2024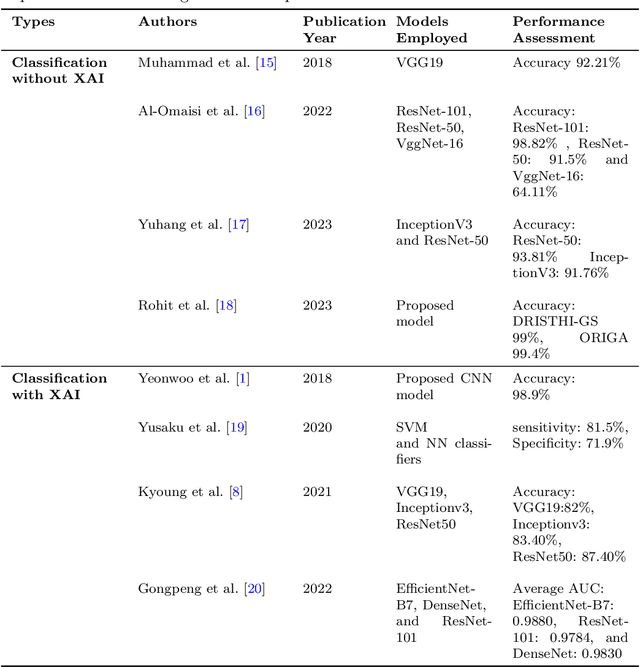
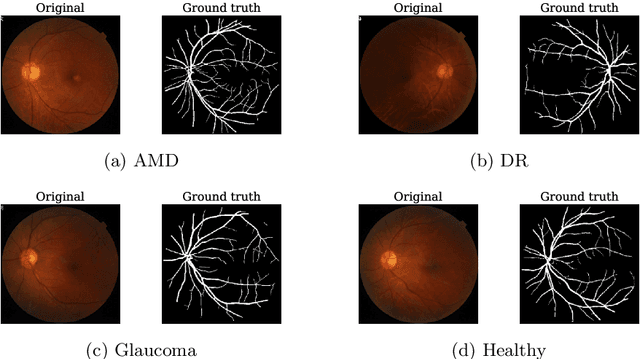
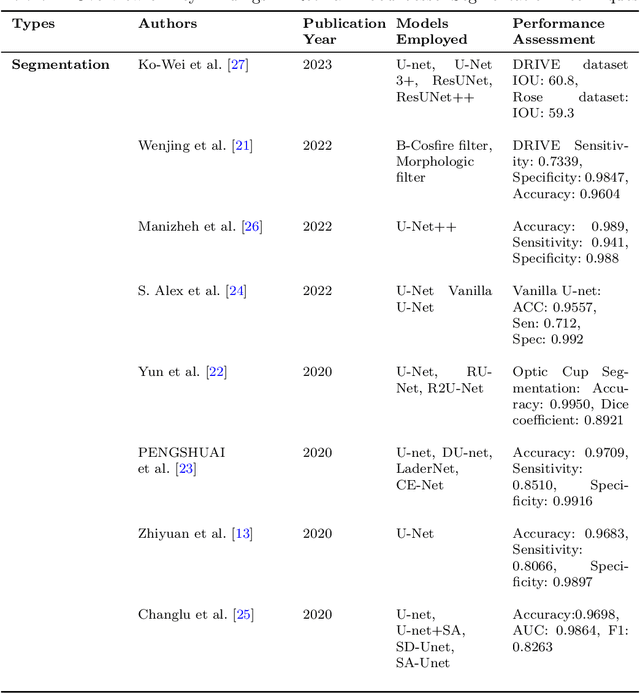
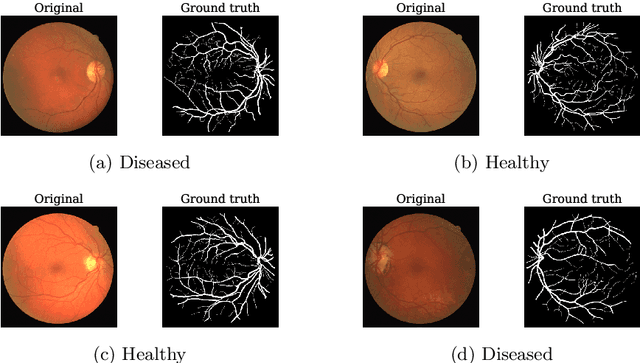
Our research focuses on the critical field of early diagnosis of disease by examining retinal blood vessels in fundus images. While automatic segmentation of retinal blood vessels holds promise for early detection, accurate analysis remains challenging due to the limitations of existing methods, which often lack discrimination power and are susceptible to influences from pathological regions. Our research in fundus image analysis advances deep learning-based classification using eight pre-trained CNN models. To enhance interpretability, we utilize Explainable AI techniques such as Grad-CAM, Grad-CAM++, Score-CAM, Faster Score-CAM, and Layer CAM. These techniques illuminate the decision-making processes of the models, fostering transparency and trust in their predictions. Expanding our exploration, we investigate ten models, including TransUNet with ResNet backbones, Attention U-Net with DenseNet and ResNet backbones, and Swin-UNET. Incorporating diverse architectures such as ResNet50V2, ResNet101V2, ResNet152V2, and DenseNet121 among others, this comprehensive study deepens our insights into attention mechanisms for enhanced fundus image analysis. Among the evaluated models for fundus image classification, ResNet101 emerged with the highest accuracy, achieving an impressive 94.17%. On the other end of the spectrum, EfficientNetB0 exhibited the lowest accuracy among the models, achieving a score of 88.33%. Furthermore, in the domain of fundus image segmentation, Swin-Unet demonstrated a Mean Pixel Accuracy of 86.19%, showcasing its effectiveness in accurately delineating regions of interest within fundus images. Conversely, Attention U-Net with DenseNet201 backbone exhibited the lowest Mean Pixel Accuracy among the evaluated models, achieving a score of 75.87%.
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
May 07, 2024



Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled "entailment". If the hypothesis contradicts the premise, the pair receives the "contradiction" label. When there is insufficient evidence to establish a connection, the pair is described as "neutral". Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.