 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Level of Toxicity Against Distinct Groups in Bangla Social Media Comments: A Comprehensive Investigation
Sep 25, 2024Social media platforms have a vital role in the modern world, serving as conduits for communication, the exchange of ideas, and the establishment of networks. However, the misuse of these platforms through toxic comments, which can range from offensive remarks to hate speech, is a concerning issue. This study focuses on identifying toxic comments in the Bengali language targeting three specific groups: transgender people, indigenous people, and migrant people, from multiple social media sources. The study delves into the intricate process of identifying and categorizing toxic language while considering the varying degrees of toxicity: high, medium, and low. The methodology involves creating a dataset, manual annotation, and employing pre-trained transformer models like Bangla-BERT, bangla-bert-base, distil-BERT, and Bert-base-multilingual-cased for classification. Diverse assessment metrics such as accuracy, recall, precision, and F1-score are employed to evaluate the model's effectiveness. The experimental findings reveal that Bangla-BERT surpasses alternative models, achieving an F1-score of 0.8903. This research exposes the complexity of toxicity in Bangla social media dialogues, revealing its differing impacts on diverse demographic groups.
Uddessho: An Extensive Benchmark Dataset for Multimodal Author Intent Classification in Low-Resource Bangla Language
Sep 14, 2024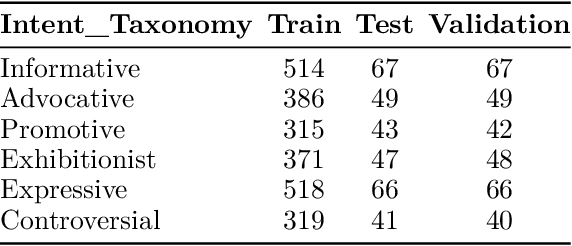
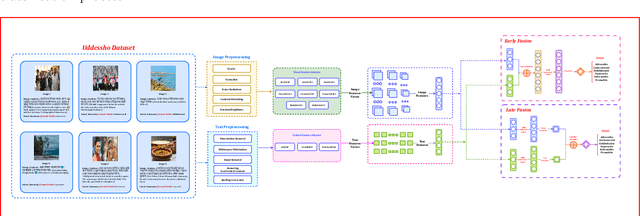
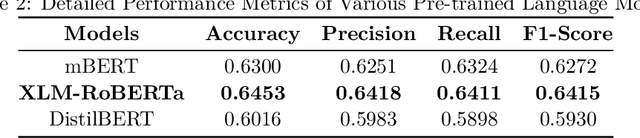

With the increasing popularity of daily information sharing and acquisition on the Internet, this paper introduces an innovative approach for intent classification in Bangla language, focusing on social media posts where individuals share their thoughts and opinions. The proposed method leverages multimodal data with particular emphasis on authorship identification, aiming to understand the underlying purpose behind textual content, especially in the context of varied user-generated posts on social media. Current methods often face challenges in low-resource languages like Bangla, particularly when author traits intricately link with intent, as observed in social media posts. To address this, we present the Multimodal-based Author Bangla Intent Classification (MABIC) framework, utilizing text and images to gain deeper insights into the conveyed intentions. We have created a dataset named "Uddessho," comprising 3,048 instances sourced from social media. Our methodology comprises two approaches for classifying textual intent and multimodal author intent, incorporating early fusion and late fusion techniques. In our experiments, the unimodal approach achieved an accuracy of 64.53% in interpreting Bangla textual intent. In contrast, our multimodal approach significantly outperformed traditional unimodal methods, achieving an accuracy of 76.19%. This represents an improvement of 11.66%. To our best knowledge, this is the first research work on multimodal-based author intent classification for low-resource Bangla language social media posts.
Motamot: A Dataset for Revealing the Supremacy of Large Language Models over Transformer Models in Bengali Political Sentiment Analysis
Jul 28, 2024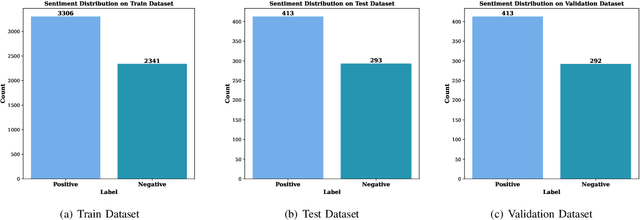

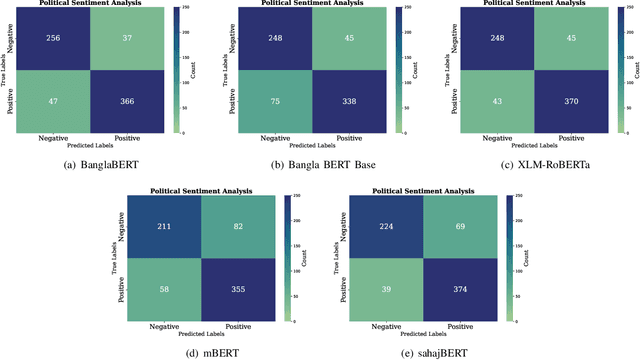

Sentiment analysis is the process of identifying and categorizing people's emotions or opinions regarding various topics. Analyzing political sentiment is critical for understanding the complexities of public opinion processes, especially during election seasons. It gives significant information on voter preferences, attitudes, and current trends. In this study, we investigate political sentiment analysis during Bangladeshi elections, specifically examining how effectively Pre-trained Language Models (PLMs) and Large Language Models (LLMs) capture complex sentiment characteristics. Our study centers on the creation of the "Motamot" dataset, comprising 7,058 instances annotated with positive and negative sentiments, sourced from diverse online newspaper portals, forming a comprehensive resource for political sentiment analysis. We meticulously evaluate the performance of various PLMs including BanglaBERT, Bangla BERT Base, XLM-RoBERTa, mBERT, and sahajBERT, alongside LLMs such as Gemini 1.5 Pro and GPT 3.5 Turbo. Moreover, we explore zero-shot and few-shot learning strategies to enhance our understanding of political sentiment analysis methodologies. Our findings underscore BanglaBERT's commendable accuracy of 88.10% among PLMs. However, the exploration into LLMs reveals even more promising results. Through the adept application of Few-Shot learning techniques, Gemini 1.5 Pro achieves an impressive accuracy of 96.33%, surpassing the remarkable performance of GPT 3.5 Turbo, which stands at 94%. This underscores Gemini 1.5 Pro's status as the superior performer in this comparison.
PotatoGANs: Utilizing Generative Adversarial Networks, Instance Segmentation, and Explainable AI for Enhanced Potato Disease Identification and Classification
May 12, 2024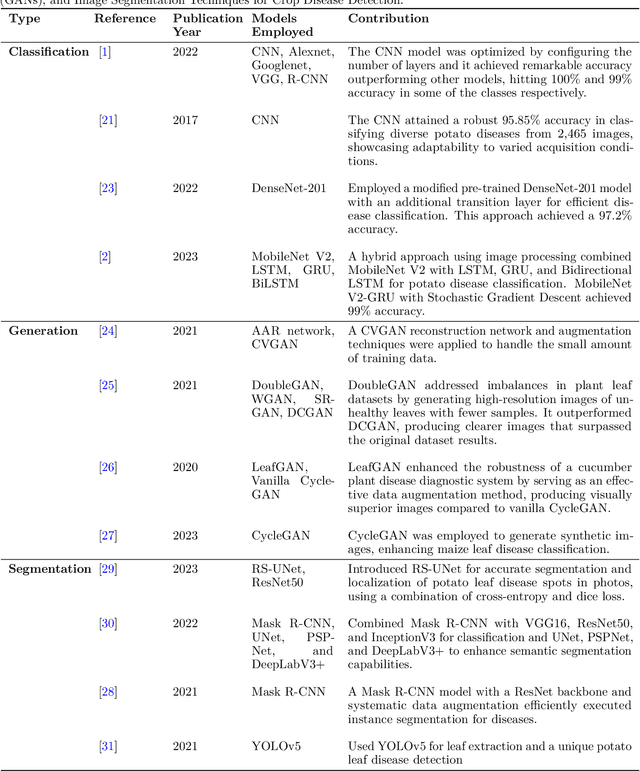
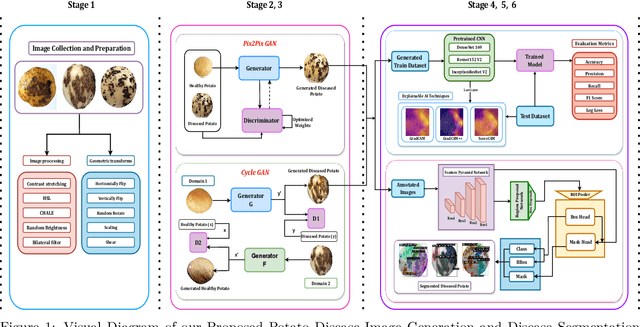


Numerous applications have resulted from the automation of agricultural disease segmentation using deep learning techniques. However, when applied to new conditions, these applications frequently face the difficulty of overfitting, resulting in lower segmentation performance. In the context of potato farming, where diseases have a large influence on yields, it is critical for the agricultural economy to quickly and properly identify these diseases. Traditional data augmentation approaches, such as rotation, flip, and translation, have limitations and frequently fail to provide strong generalization results. To address these issues, our research employs a novel approach termed as PotatoGANs. In this novel data augmentation approach, two types of Generative Adversarial Networks (GANs) are utilized to generate synthetic potato disease images from healthy potato images. This approach not only expands the dataset but also adds variety, which helps to enhance model generalization. Using the Inception score as a measure, our experiments show the better quality and realisticness of the images created by PotatoGANs, emphasizing their capacity to resemble real disease images closely. The CycleGAN model outperforms the Pix2Pix GAN model in terms of image quality, as evidenced by its higher IS scores CycleGAN achieves higher Inception scores (IS) of 1.2001 and 1.0900 for black scurf and common scab, respectively. This synthetic data can significantly improve the training of large neural networks. It also reduces data collection costs while enhancing data diversity and generalization capabilities. Our work improves interpretability by combining three gradient-based Explainable AI algorithms (GradCAM, GradCAM++, and ScoreCAM) with three distinct CNN architectures (DenseNet169, Resnet152 V2, InceptionResNet V2) for potato disease classification.
Explainable Convolutional Neural Networks for Retinal Fundus Classification and Cutting-Edge Segmentation Models for Retinal Blood Vessels from Fundus Images
May 12, 2024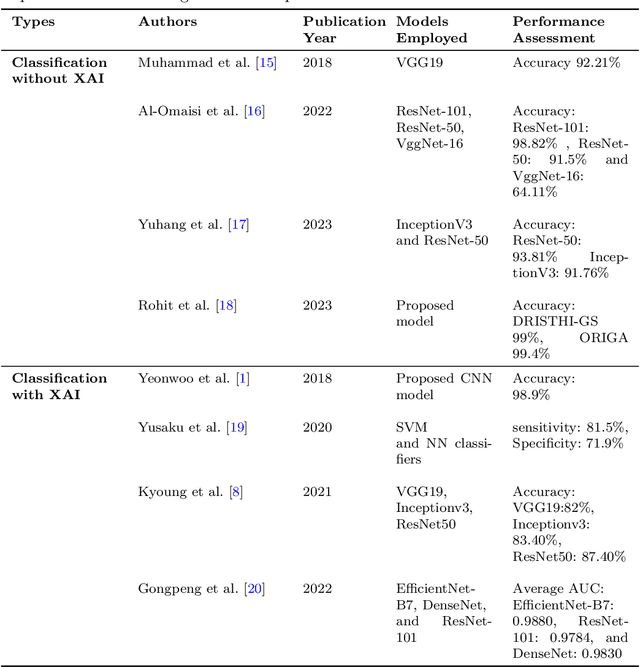
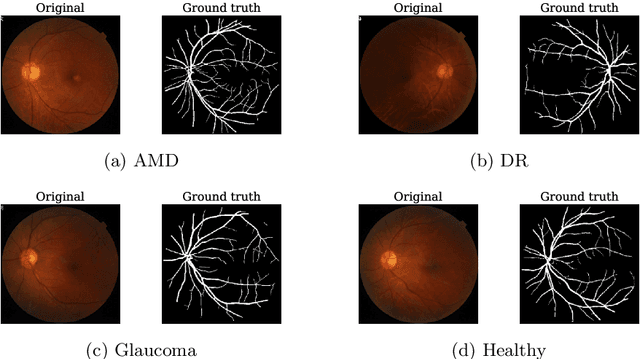
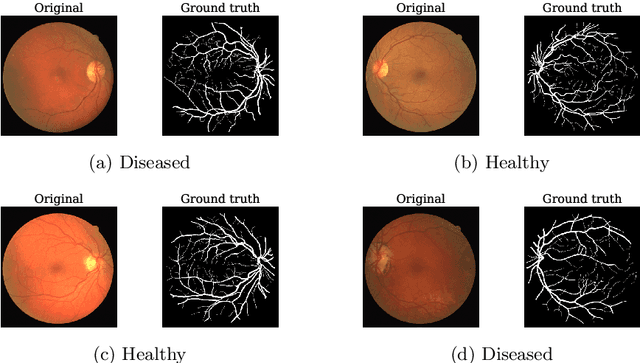
Our research focuses on the critical field of early diagnosis of disease by examining retinal blood vessels in fundus images. While automatic segmentation of retinal blood vessels holds promise for early detection, accurate analysis remains challenging due to the limitations of existing methods, which often lack discrimination power and are susceptible to influences from pathological regions. Our research in fundus image analysis advances deep learning-based classification using eight pre-trained CNN models. To enhance interpretability, we utilize Explainable AI techniques such as Grad-CAM, Grad-CAM++, Score-CAM, Faster Score-CAM, and Layer CAM. These techniques illuminate the decision-making processes of the models, fostering transparency and trust in their predictions. Expanding our exploration, we investigate ten models, including TransUNet with ResNet backbones, Attention U-Net with DenseNet and ResNet backbones, and Swin-UNET. Incorporating diverse architectures such as ResNet50V2, ResNet101V2, ResNet152V2, and DenseNet121 among others, this comprehensive study deepens our insights into attention mechanisms for enhanced fundus image analysis. Among the evaluated models for fundus image classification, ResNet101 emerged with the highest accuracy, achieving an impressive 94.17%. On the other end of the spectrum, EfficientNetB0 exhibited the lowest accuracy among the models, achieving a score of 88.33%. Furthermore, in the domain of fundus image segmentation, Swin-Unet demonstrated a Mean Pixel Accuracy of 86.19%, showcasing its effectiveness in accurately delineating regions of interest within fundus images. Conversely, Attention U-Net with DenseNet201 backbone exhibited the lowest Mean Pixel Accuracy among the evaluated models, achieving a score of 75.87%.
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
May 07, 2024



Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled "entailment". If the hypothesis contradicts the premise, the pair receives the "contradiction" label. When there is insufficient evidence to establish a connection, the pair is described as "neutral". Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.
Exploring Explainable AI Techniques for Improved Interpretability in Lung and Colon Cancer Classification
May 07, 2024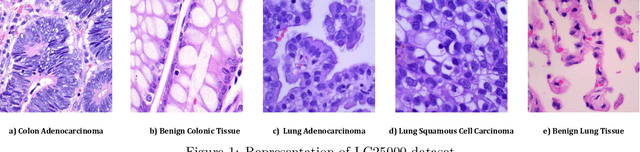
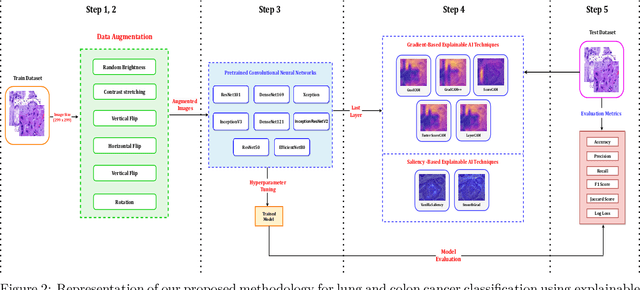
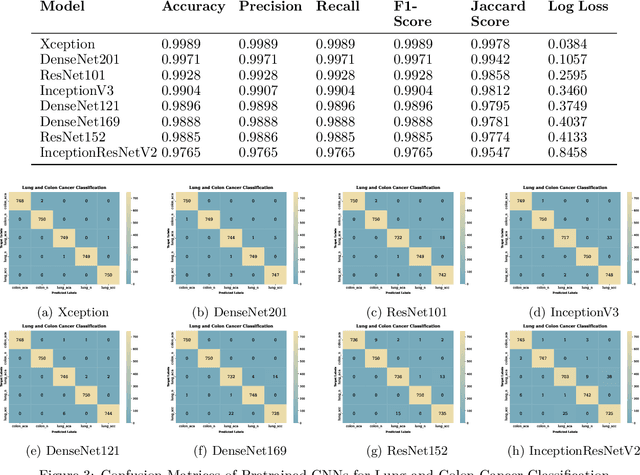
Lung and colon cancer are serious worldwide health challenges that require early and precise identification to reduce mortality risks. However, diagnosis, which is mostly dependent on histopathologists' competence, presents difficulties and hazards when expertise is insufficient. While diagnostic methods like imaging and blood markers contribute to early detection, histopathology remains the gold standard, although time-consuming and vulnerable to inter-observer mistakes. Limited access to high-end technology further limits patients' ability to receive immediate medical care and diagnosis. Recent advances in deep learning have generated interest in its application to medical imaging analysis, specifically the use of histopathological images to diagnose lung and colon cancer. The goal of this investigation is to use and adapt existing pre-trained CNN-based models, such as Xception, DenseNet201, ResNet101, InceptionV3, DenseNet121, DenseNet169, ResNet152, and InceptionResNetV2, to enhance classification through better augmentation strategies. The results show tremendous progress, with all eight models reaching impressive accuracy ranging from 97% to 99%. Furthermore, attention visualization techniques such as GradCAM, GradCAM++, ScoreCAM, Faster Score-CAM, and LayerCAM, as well as Vanilla Saliency and SmoothGrad, are used to provide insights into the models' classification decisions, thereby improving interpretability and understanding of malignant and benign image classification.
Vashantor: A Large-scale Multilingual Benchmark Dataset for Automated Translation of Bangla Regional Dialects to Bangla Language
Nov 18, 2023



The Bangla linguistic variety is a fascinating mix of regional dialects that adds to the cultural diversity of the Bangla-speaking community. Despite extensive study into translating Bangla to English, English to Bangla, and Banglish to Bangla in the past, there has been a noticeable gap in translating Bangla regional dialects into standard Bangla. In this study, we set out to fill this gap by creating a collection of 32,500 sentences, encompassing Bangla, Banglish, and English, representing five regional Bangla dialects. Our aim is to translate these regional dialects into standard Bangla and detect regions accurately. To achieve this, we proposed models known as mT5 and BanglaT5 for translating regional dialects into standard Bangla. Additionally, we employed mBERT and Bangla-bert-base to determine the specific regions from where these dialects originated. Our experimental results showed the highest BLEU score of 69.06 for Mymensingh regional dialects and the lowest BLEU score of 36.75 for Chittagong regional dialects. We also observed the lowest average word error rate of 0.1548 for Mymensingh regional dialects and the highest of 0.3385 for Chittagong regional dialects. For region detection, we achieved an accuracy of 85.86% for Bangla-bert-base and 84.36% for mBERT. This is the first large-scale investigation of Bangla regional dialects to Bangla machine translation. We believe our findings will not only pave the way for future work on Bangla regional dialects to Bangla machine translation, but will also be useful in solving similar language-related challenges in low-resource language conditions.