 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotatoGANs: Utilizing Generative Adversarial Networks, Instance Segmentation, and Explainable AI for Enhanced Potato Disease Identification and Classification
May 12, 2024
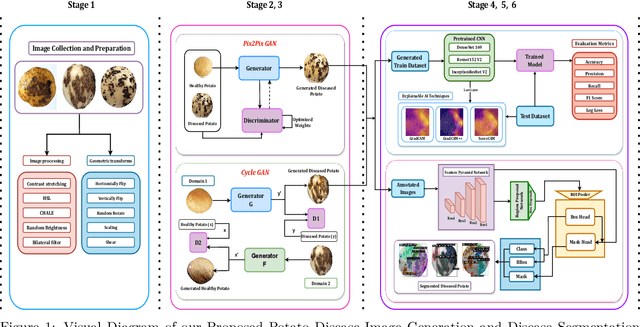


Numerous applications have resulted from the automation of agricultural disease segmentation using deep learning techniques. However, when applied to new conditions, these applications frequently face the difficulty of overfitting, resulting in lower segmentation performance. In the context of potato farming, where diseases have a large influence on yields, it is critical for the agricultural economy to quickly and properly identify these diseases. Traditional data augmentation approaches, such as rotation, flip, and translation, have limitations and frequently fail to provide strong generalization results. To address these issues, our research employs a novel approach termed as PotatoGANs. In this novel data augmentation approach, two types of Generative Adversarial Networks (GANs) are utilized to generate synthetic potato disease images from healthy potato images. This approach not only expands the dataset but also adds variety, which helps to enhance model generalization. Using the Inception score as a measure, our experiments show the better quality and realisticness of the images created by PotatoGANs, emphasizing their capacity to resemble real disease images closely. The CycleGAN model outperforms the Pix2Pix GAN model in terms of image quality, as evidenced by its higher IS scores CycleGAN achieves higher Inception scores (IS) of 1.2001 and 1.0900 for black scurf and common scab, respectively. This synthetic data can significantly improve the training of large neural networks. It also reduces data collection costs while enhancing data diversity and generalization capabilities. Our work improves interpretability by combining three gradient-based Explainable AI algorithms (GradCAM, GradCAM++, and ScoreCAM) with three distinct CNN architectures (DenseNet169, Resnet152 V2, InceptionResNet V2) for potato disease classification.
Vashantor: A Large-scale Multilingual Benchmark Dataset for Automated Translation of Bangla Regional Dialects to Bangla Language
Nov 18, 2023



The Bangla linguistic variety is a fascinating mix of regional dialects that adds to the cultural diversity of the Bangla-speaking community. Despite extensive study into translating Bangla to English, English to Bangla, and Banglish to Bangla in the past, there has been a noticeable gap in translating Bangla regional dialects into standard Bangla. In this study, we set out to fill this gap by creating a collection of 32,500 sentences, encompassing Bangla, Banglish, and English, representing five regional Bangla dialects. Our aim is to translate these regional dialects into standard Bangla and detect regions accurately. To achieve this, we proposed models known as mT5 and BanglaT5 for translating regional dialects into standard Bangla. Additionally, we employed mBERT and Bangla-bert-base to determine the specific regions from where these dialects originated. Our experimental results showed the highest BLEU score of 69.06 for Mymensingh regional dialects and the lowest BLEU score of 36.75 for Chittagong regional dialects. We also observed the lowest average word error rate of 0.1548 for Mymensingh regional dialects and the highest of 0.3385 for Chittagong regional dialects. For region detection, we achieved an accuracy of 85.86% for Bangla-bert-base and 84.36% for mBERT. This is the first large-scale investigation of Bangla regional dialects to Bangla machine translation. We believe our findings will not only pave the way for future work on Bangla regional dialects to Bangla machine translation, but will also be useful in solving similar language-related challenges in low-resource language conditions.