 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotamot: A Dataset for Revealing the Supremacy of Large Language Models over Transformer Models in Bengali Political Sentiment Analysis
Jul 28, 2024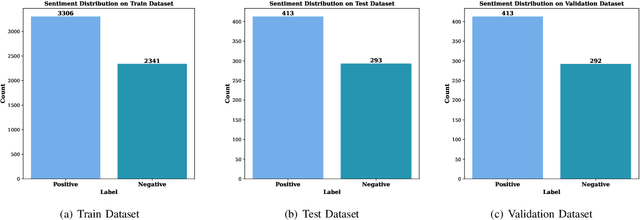

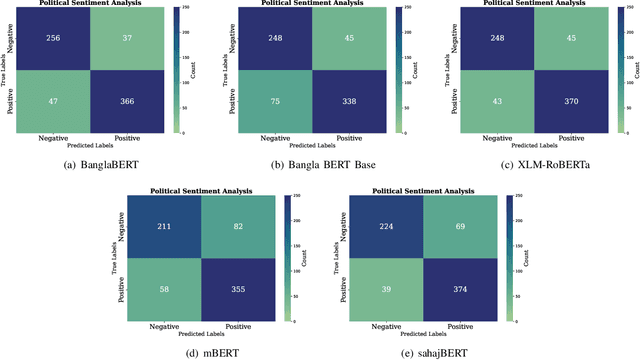

Sentiment analysis is the process of identifying and categorizing people's emotions or opinions regarding various topics. Analyzing political sentiment is critical for understanding the complexities of public opinion processes, especially during election seasons. It gives significant information on voter preferences, attitudes, and current trends. In this study, we investigate political sentiment analysis during Bangladeshi elections, specifically examining how effectively Pre-trained Language Models (PLMs) and Large Language Models (LLMs) capture complex sentiment characteristics. Our study centers on the creation of the "Motamot" dataset, comprising 7,058 instances annotated with positive and negative sentiments, sourced from diverse online newspaper portals, forming a comprehensive resource for political sentiment analysis. We meticulously evaluate the performance of various PLMs including BanglaBERT, Bangla BERT Base, XLM-RoBERTa, mBERT, and sahajBERT, alongside LLMs such as Gemini 1.5 Pro and GPT 3.5 Turbo. Moreover, we explore zero-shot and few-shot learning strategies to enhance our understanding of political sentiment analysis methodologies. Our findings underscore BanglaBERT's commendable accuracy of 88.10% among PLMs. However, the exploration into LLMs reveals even more promising results. Through the adept application of Few-Shot learning techniques, Gemini 1.5 Pro achieves an impressive accuracy of 96.33%, surpassing the remarkable performance of GPT 3.5 Turbo, which stands at 94%. This underscores Gemini 1.5 Pro's status as the superior performer in this comparison.
PotatoGANs: Utilizing Generative Adversarial Networks, Instance Segmentation, and Explainable AI for Enhanced Potato Disease Identification and Classification
May 12, 2024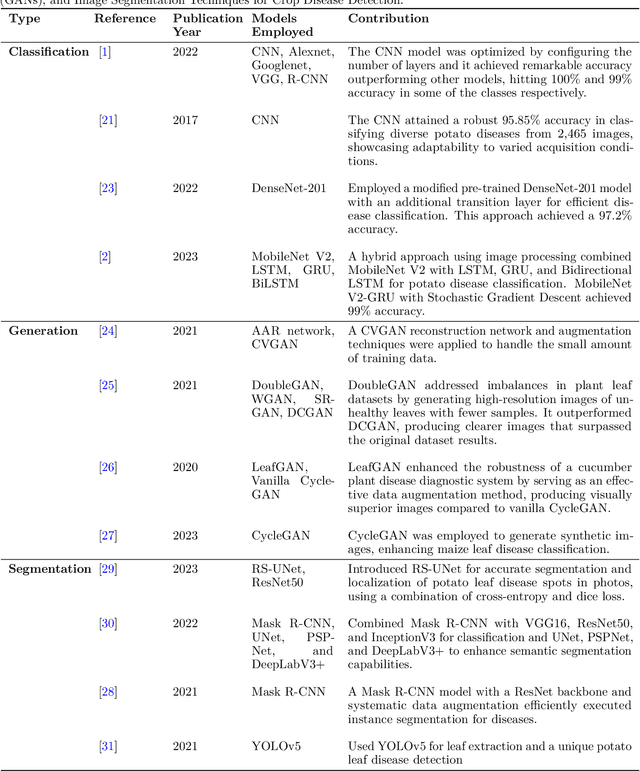
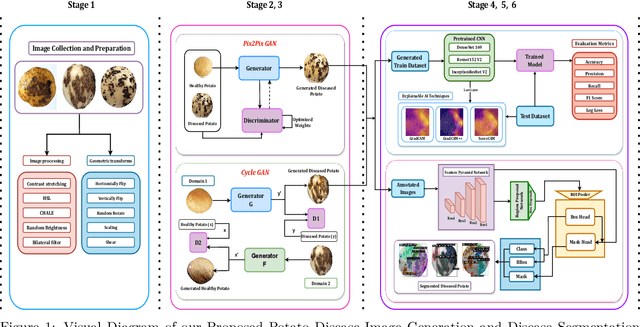


Numerous applications have resulted from the automation of agricultural disease segmentation using deep learning techniques. However, when applied to new conditions, these applications frequently face the difficulty of overfitting, resulting in lower segmentation performance. In the context of potato farming, where diseases have a large influence on yields, it is critical for the agricultural economy to quickly and properly identify these diseases. Traditional data augmentation approaches, such as rotation, flip, and translation, have limitations and frequently fail to provide strong generalization results. To address these issues, our research employs a novel approach termed as PotatoGANs. In this novel data augmentation approach, two types of Generative Adversarial Networks (GANs) are utilized to generate synthetic potato disease images from healthy potato images. This approach not only expands the dataset but also adds variety, which helps to enhance model generalization. Using the Inception score as a measure, our experiments show the better quality and realisticness of the images created by PotatoGANs, emphasizing their capacity to resemble real disease images closely. The CycleGAN model outperforms the Pix2Pix GAN model in terms of image quality, as evidenced by its higher IS scores CycleGAN achieves higher Inception scores (IS) of 1.2001 and 1.0900 for black scurf and common scab, respectively. This synthetic data can significantly improve the training of large neural networks. It also reduces data collection costs while enhancing data diversity and generalization capabilities. Our work improves interpretability by combining three gradient-based Explainable AI algorithms (GradCAM, GradCAM++, and ScoreCAM) with three distinct CNN architectures (DenseNet169, Resnet152 V2, InceptionResNet V2) for potato disease classification.
Exploring Explainable AI Techniques for Improved Interpretability in Lung and Colon Cancer Classification
May 07, 2024
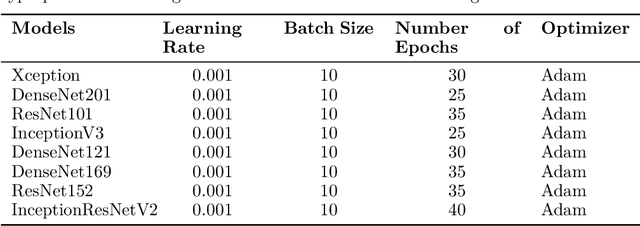
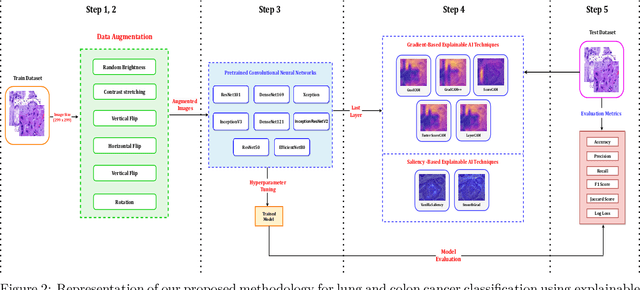
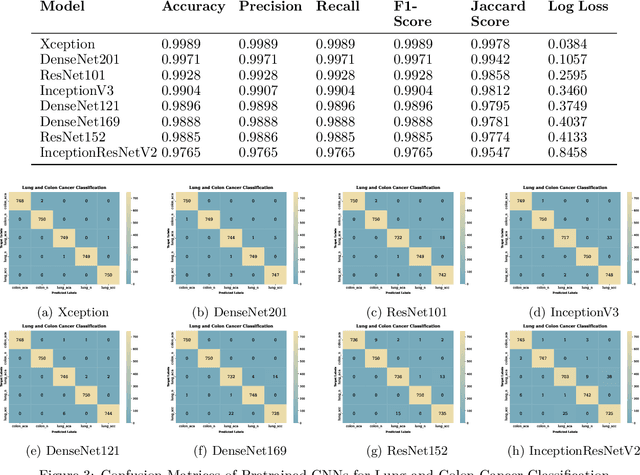
Lung and colon cancer are serious worldwide health challenges that require early and precise identification to reduce mortality risks. However, diagnosis, which is mostly dependent on histopathologists' competence, presents difficulties and hazards when expertise is insufficient. While diagnostic methods like imaging and blood markers contribute to early detection, histopathology remains the gold standard, although time-consuming and vulnerable to inter-observer mistakes. Limited access to high-end technology further limits patients' ability to receive immediate medical care and diagnosis. Recent advances in deep learning have generated interest in its application to medical imaging analysis, specifically the use of histopathological images to diagnose lung and colon cancer. The goal of this investigation is to use and adapt existing pre-trained CNN-based models, such as Xception, DenseNet201, ResNet101, InceptionV3, DenseNet121, DenseNet169, ResNet152, and InceptionResNetV2, to enhance classification through better augmentation strategies. The results show tremendous progress, with all eight models reaching impressive accuracy ranging from 97% to 99%. Furthermore, attention visualization techniques such as GradCAM, GradCAM++, ScoreCAM, Faster Score-CAM, and LayerCAM, as well as Vanilla Saliency and SmoothGrad, are used to provide insights into the models' classification decisions, thereby improving interpretability and understanding of malignant and benign image classification.
Bengali Fake Reviews: A Benchmark Dataset and Detection System
Aug 03, 2023
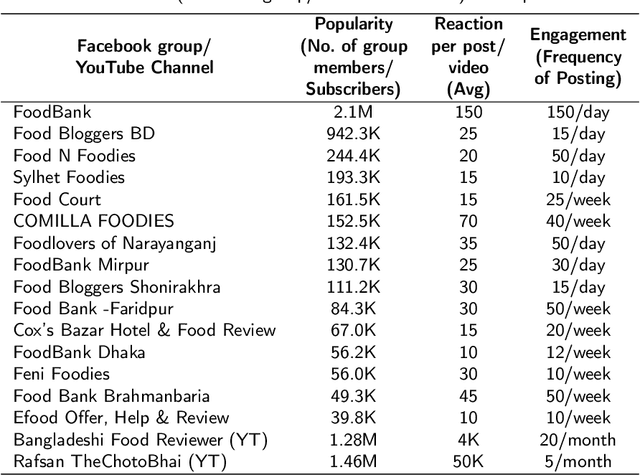
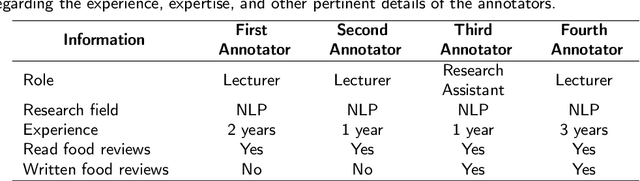
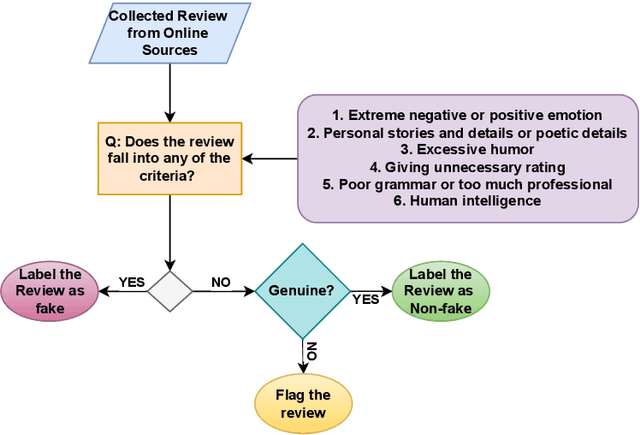
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Bengali Fake Review Detection using Semi-supervised Generative Adversarial Networks
Apr 05, 2023



This paper investigates the potential of semi-supervised Generative Adversarial Networks (GANs) to fine-tune pretrained language models in order to classify Bengali fake reviews from real reviews with a few annotated data. With the rise of social media and e-commerce, the ability to detect fake or deceptive reviews is becoming increasingly important in order to protect consumers from being misled by false information. Any machine learning model will have trouble identifying a fake review, especially for a low resource language like Bengali. We have demonstrated that the proposed semi-supervised GAN-LM architecture (generative adversarial network on top of a pretrained language model) is a viable solution in classifying Bengali fake reviews as the experimental results suggest that even with only 1024 annotated samples, BanglaBERT with semi-supervised GAN (SSGAN) achieved an accuracy of 83.59% and a f1-score of 84.89% outperforming other pretrained language models - BanglaBERT generator, Bangla BERT Base and Bangla-Electra by almost 3%, 4% and 10% respectively in terms of accuracy. The experiments were conducted on a manually labeled food review dataset consisting of total 6014 real and fake reviews collected from various social media groups. Researchers that are experiencing difficulty recognizing not just fake reviews but other classification issues owing to a lack of labeled data may find a solution in our proposed methodology.
Crime Prediction using Machine Learning with a Novel Crime Dataset
Nov 03, 2022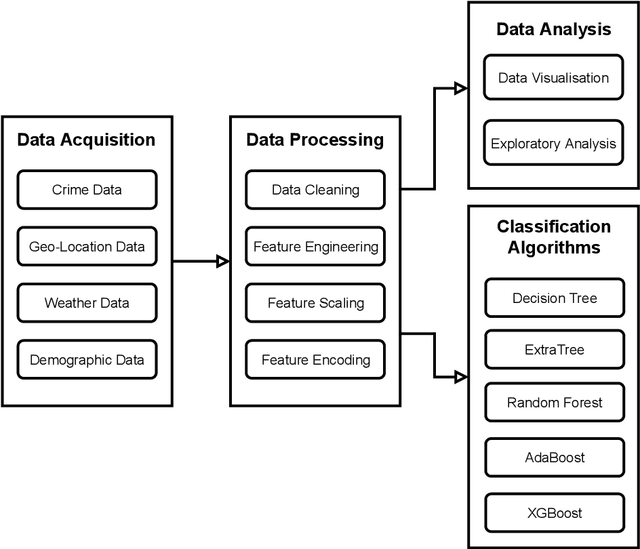

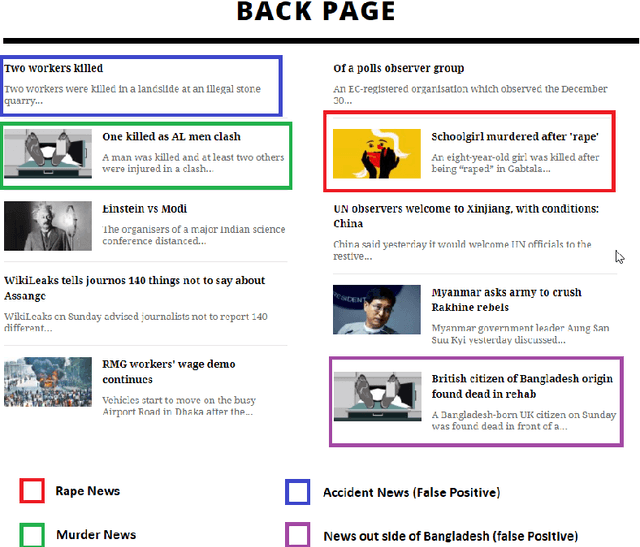
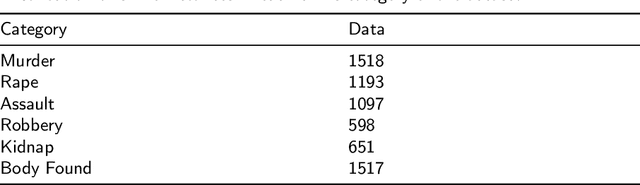
Crime is an unlawful act that carries legal repercussions. Bangladesh has a high crime rate due to poverty, population growth, and many other socio-economic issues. For law enforcement agencies, understanding crime patterns is essential for preventing future criminal activity. For this purpose, these agencies need structured crime database. This paper introduces a novel crime dataset that contains temporal, geographic, weather, and demographic data about 6574 crime incidents of Bangladesh. We manually gather crime news articles of a seven year time span from a daily newspaper archive. We extract basic features from these raw text. Using these basic features, we then consult standard service-providers of geo-location and weather data in order to garner these information related to the collected crime incidents. Furthermore, we collect demographic information from Bangladesh National Census data. All these information are combined that results in a standard machine learning dataset. Together, 36 features are engineered for the crime prediction task. Five supervised machine learning classification algorithms are then evaluated on this newly built dataset and satisfactory results are achieved. We also conduct exploratory analysis on various aspects the dataset. This dataset is expected to serve as the foundation for crime incidence prediction systems for Bangladesh and other countries. The findings of this study will help law enforcement agencies to forecast and contain crime as well as to ensure optimal resource allocation for crime patrol and prevention.
An Approach of Adjusting the Switch Probability based on Dimension Size: A Case Study for Performance Improvement of the Flower Pollination Algorithm
Aug 20, 2022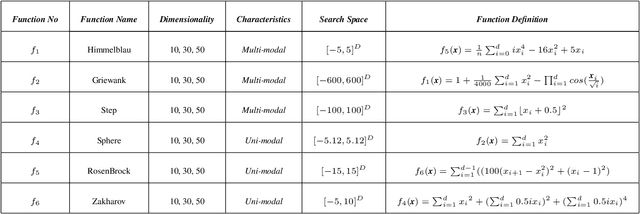
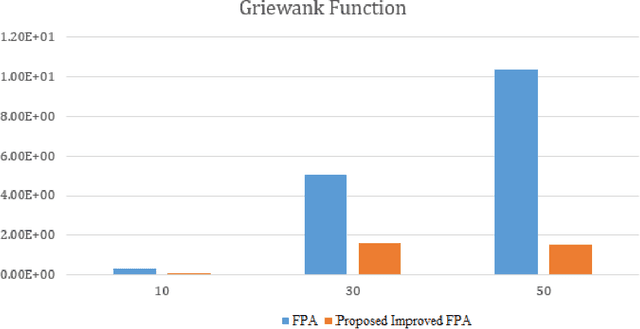
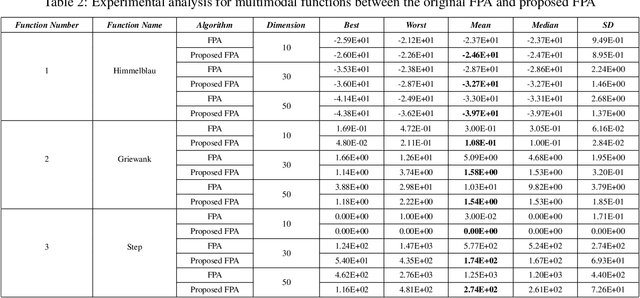
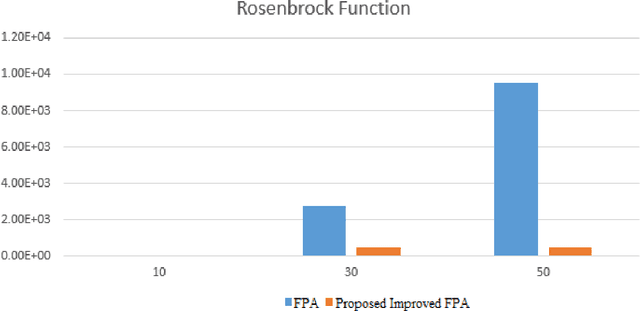
Numerous meta-heuristic algorithms have been influenced by nature. Over the past couple of decades, their quantity has been significantly escalating. The majority of these algorithms attempt to emulate natural biological and physical phenomena. This research concentrates on the Flower Pollination algorithm, which is one of several bio-inspired algorithms. The original approach was suggested for pollen grain exploration and exploitation in confined space using a specific global pollination and local pollination strategy. As a "swarm intelligence" meta-heuristic algorithm, its strength lies in locating the vicinity of the optimum solution rather than identifying the minimum. A modification to the original method is detailed in this work. This research found that by changing the specific value of "switch probability" with dynamic values of different dimension sizes and functions, the outcome was mainly improved over the original flower pollination method.
Transformer-Based Deep Learning Model for Stock Price Prediction: A Case Study on Bangladesh Stock Market
Aug 17, 2022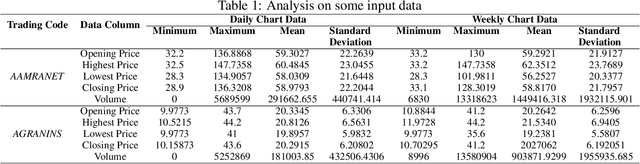

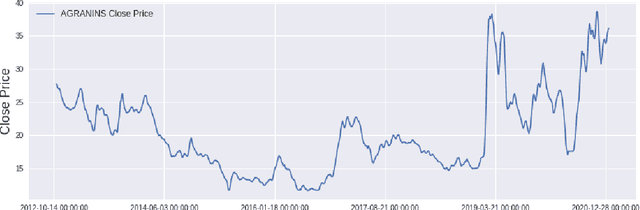
In modern capital market the price of a stock is often considered to be highly volatile and unpredictable because of various social, financial, political and other dynamic factors. With calculated and thoughtful investment, stock market can ensure a handsome profit with minimal capital investment, while incorrect prediction can easily bring catastrophic financial loss to the investors. This paper introduces the application of a recently introduced machine learning model - the Transformer model, to predict the future price of stocks of Dhaka Stock Exchange (DSE), the leading stock exchange in Bangladesh. The transformer model has been widely leveraged for natural language processing and computer vision tasks, but, to the best of our knowledge, has never been used for stock price prediction task at DSE. Recently the introduction of time2vec encoding to represent the time series features has made it possible to employ the transformer model for the stock price prediction. This paper concentrates on the application of transformer-based model to predict the price movement of eight specific stocks listed in DSE based on their historical daily and weekly data. Our experiments demonstrate promising results and acceptable root mean squared error on most of the stocks.