 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploratory Approach Towards Investigating and Explaining Vision Transformer and Transfer Learning for Brain Disease Detection
May 21, 2025
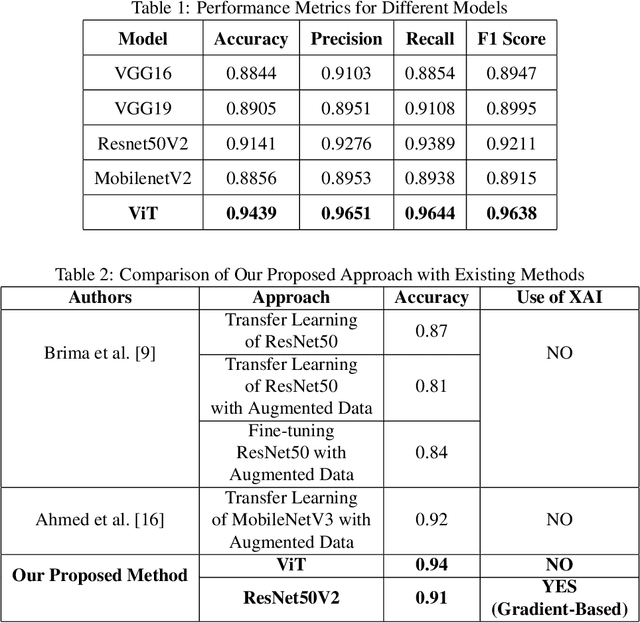
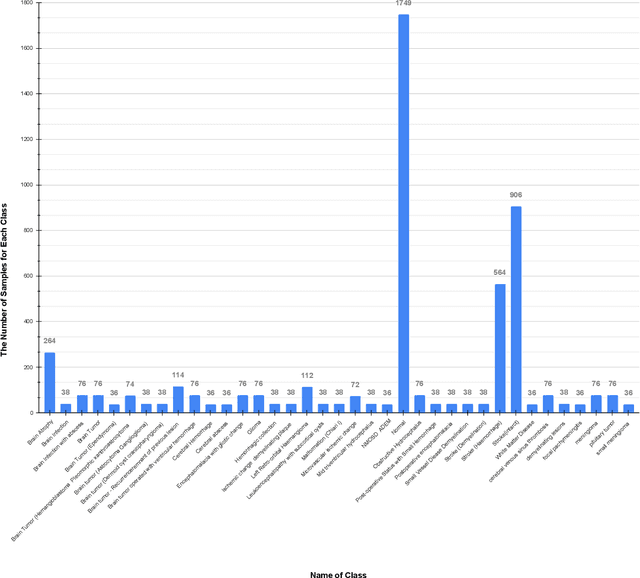
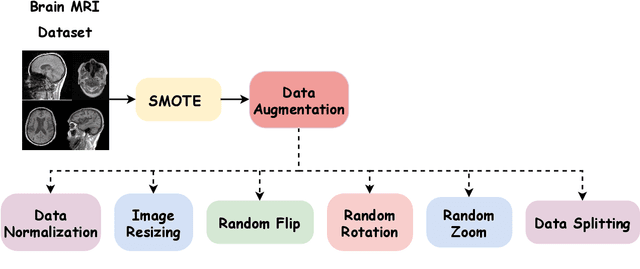
The brain is a highly complex organ that manages many important tasks, including movement, memory and thinking. Brain-related conditions, like tumors and degenerative disorders, can be hard to diagnose and treat. Magnetic Resonance Imaging (MRI) serves as a key tool for identifying these conditions, offering high-resolution images of brain structures. Despite this, interpreting MRI scans can be complicated. This study tackles this challenge by conducting a comparative analysis of Vision Transformer (ViT) and Transfer Learning (TL) models such as VGG16, VGG19, Resnet50V2, MobilenetV2 for classifying brain diseases using MRI data from Bangladesh based dataset. ViT, known for their ability to capture global relationships in images, are particularly effective for medical imaging tasks. Transfer learning helps to mitigate data constraints by fine-tuning pre-trained models. Furthermore, Explainable AI (XAI) methods such as GradCAM, GradCAM++, LayerCAM, ScoreCAM, and Faster-ScoreCAM are employed to interpret model predictions. The results demonstrate that ViT surpasses transfer learning models, achieving a classification accuracy of 94.39%. The integration of XAI methods enhances model transparency, offering crucial insights to aid medical professionals in diagnosing brain diseases with greater precision.
An Approach Towards Identifying Bangladeshi Leaf Diseases through Transfer Learning and XAI
May 21, 2025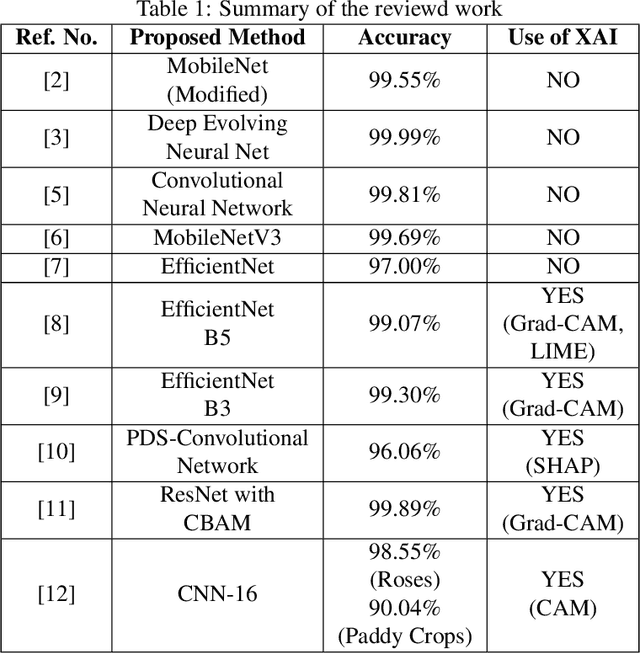

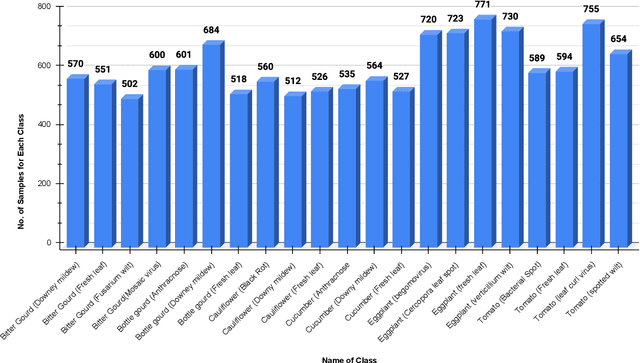
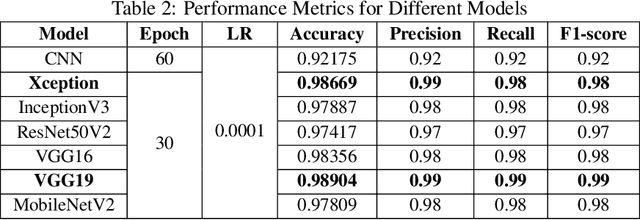
Leaf diseases are harmful conditions that affect the health, appearance and productivity of plants, leading to significant plant loss and negatively impacting farmers' livelihoods. These diseases cause visible symptoms such as lesions, color changes, and texture variations, making it difficult for farmers to manage plant health, especially in large or remote farms where expert knowledge is limited. The main motivation of this study is to provide an efficient and accessible solution for identifying plant leaf diseases in Bangladesh, where agriculture plays a critical role in food security. The objective of our research is to classify 21 distinct leaf diseases across six plants using deep learning models, improving disease detection accuracy while reducing the need for expert involvement. Deep Learning (DL) techniques, including CNN and Transfer Learning (TL) models like VGG16, VGG19, MobileNetV2, InceptionV3, ResNet50V2 and Xception are used. VGG19 and Xception achieve the highest accuracies, with 98.90% and 98.66% respectively. Additionally, Explainable AI (XAI) techniques such as GradCAM, GradCAM++, LayerCAM, ScoreCAM and FasterScoreCAM are used to enhance transparency by highlighting the regions of the models focused on during disease classification. This transparency ensures that farmers can understand the model's predictions and take necessary action. This approach not only improves disease management but also supports farmers in making informed decisions, leading to better plant protection and increased agricultural productivity.
VR-FuseNet: A Fusion of Heterogeneous Fundus Data and Explainable Deep Network for Diabetic Retinopathy Classification
Apr 30, 2025Diabetic retinopathy is a severe eye condition caused by diabetes where the retinal blood vessels get damaged and can lead to vision loss and blindness if not treated. Early and accurate detection is key to intervention and stopping the disease progressing. For addressing this disease properly, this paper presents a comprehensive approach for automated diabetic retinopathy detection by proposing a new hybrid deep learning model called VR-FuseNet. Diabetic retinopathy is a major eye disease and leading cause of blindness especially among diabetic patients so accurate and efficient automated detection methods are required. To address the limitations of existing methods including dataset imbalance, diversity and generalization issues this paper presents a hybrid dataset created from five publicly available diabetic retinopathy datasets. Essential preprocessing techniques such as SMOTE for class balancing and CLAHE for image enhancement are applied systematically to the dataset to improve the robustness and generalizability of the dataset. The proposed VR-FuseNet model combines the strengths of two state-of-the-art convolutional neural networks, VGG19 which captures fine-grained spatial features and ResNet50V2 which is known for its deep hierarchical feature extraction. This fusion improves the diagnostic performance and achieves an accuracy of 91.824%. The model outperforms individual architectures on all performance metrics demonstrating the effectiveness of hybrid feature extraction in Diabetic Retinopathy classification tasks. To make the proposed model more clinically useful and interpretable this paper incorporates multiple XAI techniques. These techniques generate visual explanations that clearly indicate the retinal features affecting the model's prediction such as microaneurysms, hemorrhages and exudates so that clinicians can interpret and validate.
Bridging Dialects: Translating Standard Bangla to Regional Variants Using Neural Models
Jan 10, 2025The Bangla language includes many regional dialects, adding to its cultural richness. The translation of Bangla Language into regional dialects presents a challenge due to significant variations in vocabulary, pronunciation, and sentence structure across regions like Chittagong, Sylhet, Barishal, Noakhali, and Mymensingh. These dialects, though vital to local identities, lack of representation in technological applications. This study addresses this gap by translating standard Bangla into these dialects using neural machine translation (NMT) models, including BanglaT5, mT5, and mBART50. The work is motivated by the need to preserve linguistic diversity and improve communication among dialect speakers. The models were fine-tuned using the "Vashantor" dataset, containing 32,500 sentences across various dialects, and evaluated through Character Error Rate (CER) and Word Error Rate (WER) metrics. BanglaT5 demonstrated superior performance with a CER of 12.3% and WER of 15.7%, highlighting its effectiveness in capturing dialectal nuances. The outcomes of this research contribute to the development of inclusive language technologies that support regional dialects and promote linguistic diversity.
Explainable AI-Enhanced Deep Learning for Pumpkin Leaf Disease Detection: A Comparative Analysis of CNN Architectures
Jan 09, 2025Pumpkin leaf diseases are significant threats to agricultural productivity, requiring a timely and precise diagnosis for effective management. Traditional identification methods are laborious and susceptible to human error, emphasizing the necessity for automated solutions. This study employs on the "Pumpkin Leaf Disease Dataset", that comprises of 2000 high-resolution images separated into five categories. Downy mildew, powdery mildew, mosaic disease, bacterial leaf spot, and healthy leaves. The dataset was rigorously assembled from several agricultural fields to ensure a strong representation for model training. We explored many proficient deep learning architectures, including DenseNet201, DenseNet121, DenseNet169, Xception, ResNet50, ResNet101 and InceptionResNetV2, and observed that ResNet50 performed most effectively, with an accuracy of 90.5% and comparable precision, recall, and F1-Score. We used Explainable AI (XAI) approaches like Grad-CAM, Grad-CAM++, Score-CAM, and Layer-CAM to provide meaningful representations of model decision-making processes, which improved understanding and trust in automated disease diagnostics. These findings demonstrate ResNet50's potential to revolutionize pumpkin leaf disease detection, allowing for earlier and more accurate treatments.
Vashantor: A Large-scale Multilingual Benchmark Dataset for Automated Translation of Bangla Regional Dialects to Bangla Language
Nov 18, 2023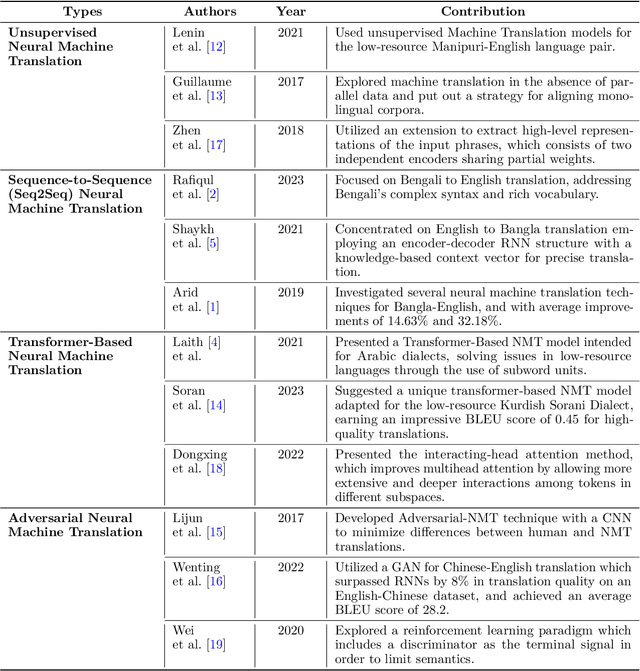



The Bangla linguistic variety is a fascinating mix of regional dialects that adds to the cultural diversity of the Bangla-speaking community. Despite extensive study into translating Bangla to English, English to Bangla, and Banglish to Bangla in the past, there has been a noticeable gap in translating Bangla regional dialects into standard Bangla. In this study, we set out to fill this gap by creating a collection of 32,500 sentences, encompassing Bangla, Banglish, and English, representing five regional Bangla dialects. Our aim is to translate these regional dialects into standard Bangla and detect regions accurately. To achieve this, we proposed models known as mT5 and BanglaT5 for translating regional dialects into standard Bangla. Additionally, we employed mBERT and Bangla-bert-base to determine the specific regions from where these dialects originated. Our experimental results showed the highest BLEU score of 69.06 for Mymensingh regional dialects and the lowest BLEU score of 36.75 for Chittagong regional dialects. We also observed the lowest average word error rate of 0.1548 for Mymensingh regional dialects and the highest of 0.3385 for Chittagong regional dialects. For region detection, we achieved an accuracy of 85.86% for Bangla-bert-base and 84.36% for mBERT. This is the first large-scale investigation of Bangla regional dialects to Bangla machine translation. We believe our findings will not only pave the way for future work on Bangla regional dialects to Bangla machine translation, but will also be useful in solving similar language-related challenges in low-resource language conditions.
Can Transformer Models Effectively Detect Software Aspects in StackOverflow Discussion?
Sep 24, 2022



Dozens of new tools and technologies are being incorporated to help developers, which is becoming a source of consternation as they struggle to choose one over the others. For example, there are at least ten frameworks available to developers for developing web applications, posing a conundrum in selecting the best one that meets their needs. As a result, developers are continuously searching for all of the benefits and drawbacks of each API, framework, tool, and so on. One of the typical approaches is to examine all of the features through official documentation and discussion. This approach is time-consuming, often makes it difficult to determine which aspects are the most important to a particular developer and whether a particular aspect is important to the community at large. In this paper, we have used a benchmark API aspects dataset (Opiner) collected from StackOverflow posts and observed how Transformer models (BERT, RoBERTa, DistilBERT, and XLNet) perform in detecting software aspects in textual developer discussion with respect to the baseline Support Vector Machine (SVM) model. Through extensive experimentation, we have found that transformer models improve the performance of baseline SVM for most of the aspects, i.e., `Performance', `Security', `Usability', `Documentation', `Bug', `Legal', `OnlySentiment', and `Others'. However, the models fail to apprehend some of the aspects (e.g., `Community' and `Potability') and their performance varies depending on the aspects. Also, larger architectures like XLNet are ineffective in interpreting software aspects compared to smaller architectures like DistilBERT.
An Approach of Adjusting the Switch Probability based on Dimension Size: A Case Study for Performance Improvement of the Flower Pollination Algorithm
Aug 20, 2022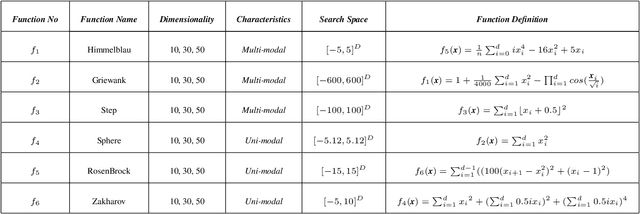
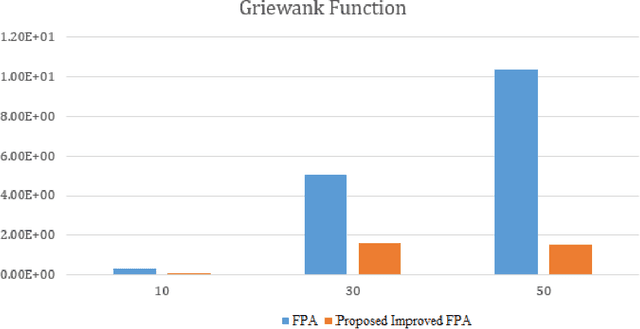
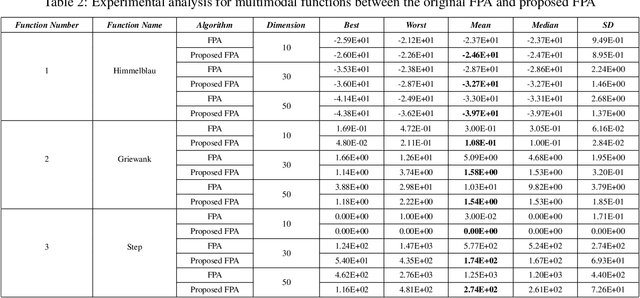
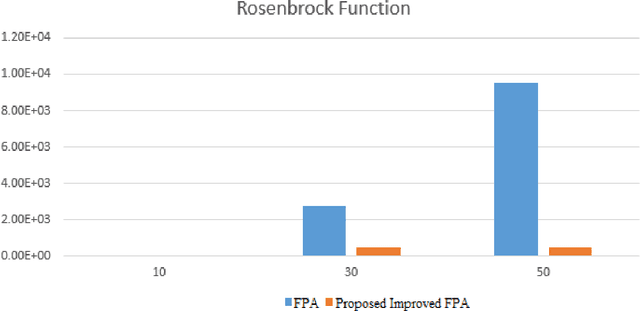
Numerous meta-heuristic algorithms have been influenced by nature. Over the past couple of decades, their quantity has been significantly escalating. The majority of these algorithms attempt to emulate natural biological and physical phenomena. This research concentrates on the Flower Pollination algorithm, which is one of several bio-inspired algorithms. The original approach was suggested for pollen grain exploration and exploitation in confined space using a specific global pollination and local pollination strategy. As a "swarm intelligence" meta-heuristic algorithm, its strength lies in locating the vicinity of the optimum solution rather than identifying the minimum. A modification to the original method is detailed in this work. This research found that by changing the specific value of "switch probability" with dynamic values of different dimension sizes and functions, the outcome was mainly improved over the original flower pollination method.
Transformer-Based Deep Learning Model for Stock Price Prediction: A Case Study on Bangladesh Stock Market
Aug 17, 2022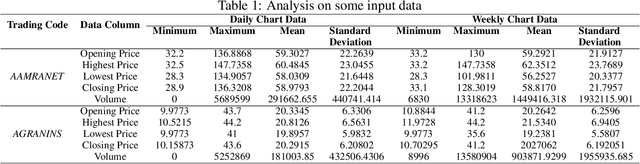

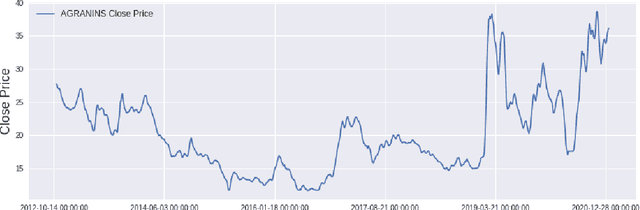
In modern capital market the price of a stock is often considered to be highly volatile and unpredictable because of various social, financial, political and other dynamic factors. With calculated and thoughtful investment, stock market can ensure a handsome profit with minimal capital investment, while incorrect prediction can easily bring catastrophic financial loss to the investors. This paper introduces the application of a recently introduced machine learning model - the Transformer model, to predict the future price of stocks of Dhaka Stock Exchange (DSE), the leading stock exchange in Bangladesh. The transformer model has been widely leveraged for natural language processing and computer vision tasks, but, to the best of our knowledge, has never been used for stock price prediction task at DSE. Recently the introduction of time2vec encoding to represent the time series features has made it possible to employ the transformer model for the stock price prediction. This paper concentrates on the application of transformer-based model to predict the price movement of eight specific stocks listed in DSE based on their historical daily and weekly data. Our experiments demonstrate promising results and acceptable root mean squared error on most of the stocks.