 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM-CAFO: Prior-conditioned Remote-sensing Infrastructure Segmentation and Mapping for CAFOs
Jan 16, 2026Large-scale livestock operations pose significant risks to human health and the environment, while also being vulnerable to threats such as infectious diseases and extreme weather events. As the number of such operations continues to grow, accurate and scalable mapping has become increasingly important. In this work, we present an infrastructure-first, explainable pipeline for identifying and characterizing Concentrated Animal Feeding Operations (CAFOs) from aerial and satellite imagery. Our method (1) detects candidate infrastructure (e.g., barns, feedlots, manure lagoons, silos) with a domain-tuned YOLOv8 detector, then derives SAM2 masks from these boxes and filters component-specific criteria, (2) extracts structured descriptors (e.g., counts, areas, orientations, and spatial relations) and fuses them with deep visual features using a lightweight spatial cross-attention classifier, and (3) outputs both CAFO type predictions and mask-level attributions that link decisions to visible infrastructure. Through comprehensive evaluation, we show that our approach achieves state-of-the-art performance, with Swin-B+PRISM-CAFO surpassing the best performing baseline by up to 15\%. Beyond strong predictive performance across diverse U.S. regions, we run systematic gradient--activation analyses that quantify the impact of domain priors and show ho
IrrMap: A Large-Scale Comprehensive Dataset for Irrigation Method Mapping
May 13, 2025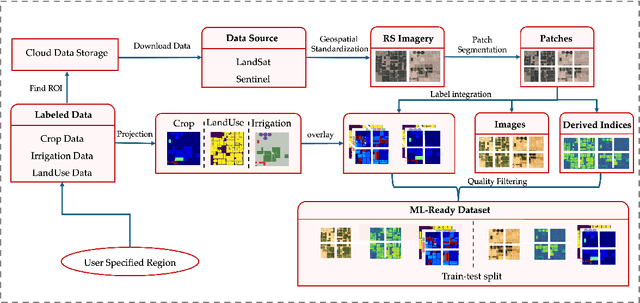
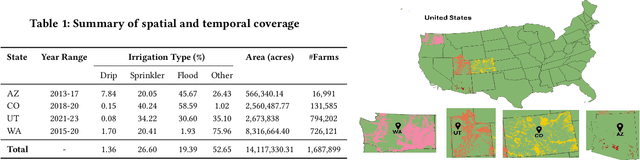

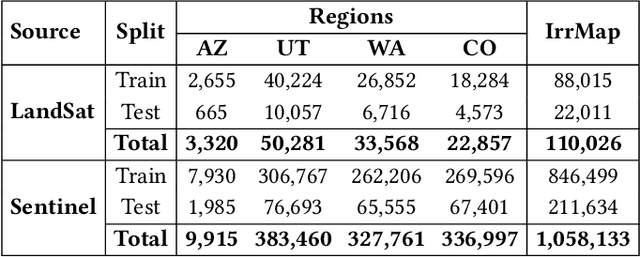
We introduce IrrMap, the first large-scale dataset (1.1 million patches) for irrigation method mapping across regions. IrrMap consists of multi-resolution satellite imagery from LandSat and Sentinel, along with key auxiliary data such as crop type, land use, and vegetation indices. The dataset spans 1,687,899 farms and 14,117,330 acres across multiple western U.S. states from 2013 to 2023, providing a rich and diverse foundation for irrigation analysis and ensuring geospatial alignment and quality control. The dataset is ML-ready, with standardized 224x224 GeoTIFF patches, the multiple input modalities, carefully chosen train-test-split data, and accompanying dataloaders for seamless deep learning model training andbenchmarking in irrigation mapping. The dataset is also accompanied by a complete pipeline for dataset generation, enabling researchers to extend IrrMap to new regions for irrigation data collection or adapt it with minimal effort for other similar applications in agricultural and geospatial analysis. We also analyze the irrigation method distribution across crop groups, spatial irrigation patterns (using Shannon diversity indices), and irrigated area variations for both LandSat and Sentinel, providing insights into regional and resolution-based differences. To promote further exploration, we openly release IrrMap, along with the derived datasets, benchmark models, and pipeline code, through a GitHub repository: https://github.com/Nibir088/IrrMap and Data repository: https://huggingface.co/Nibir/IrrMap, providing comprehensive documentation and implementation details.
Knowledge-Informed Deep Learning for Irrigation Type Mapping from Remote Sensing
May 13, 2025Accurate mapping of irrigation methods is crucial for sustainable agricultural practices and food systems. However, existing models that rely solely on spectral features from satellite imagery are ineffective due to the complexity of agricultural landscapes and limited training data, making this a challenging problem. We present Knowledge-Informed Irrigation Mapping (KIIM), a novel Swin-Transformer based approach that uses (i) a specialized projection matrix to encode crop to irrigation probability, (ii) a spatial attention map to identify agricultural lands from non-agricultural lands, (iii) bi-directional cross-attention to focus complementary information from different modalities, and (iv) a weighted ensemble for combining predictions from images and crop information. Our experimentation on five states in the US shows up to 22.9\% (IoU) improvement over baseline with a 71.4% (IoU) improvement for hard-to-classify drip irrigation. In addition, we propose a two-phase transfer learning approach to enhance cross-state irrigation mapping, achieving a 51% IoU boost in a state with limited labeled data. The ability to achieve baseline performance with only 40% of the training data highlights its efficiency, reducing the dependency on extensive manual labeling efforts and making large-scale, automated irrigation mapping more feasible and cost-effective.
An Empirical Studies on How the Developers Discussed about Pandas Topics
Oct 07, 2022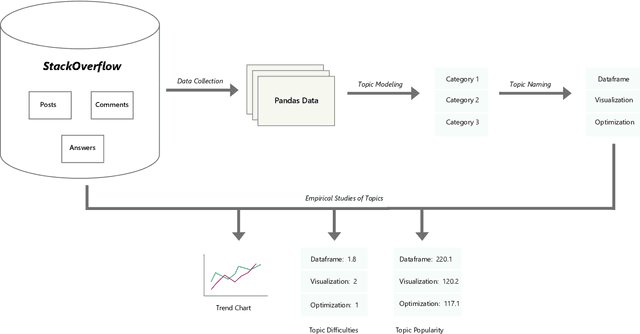
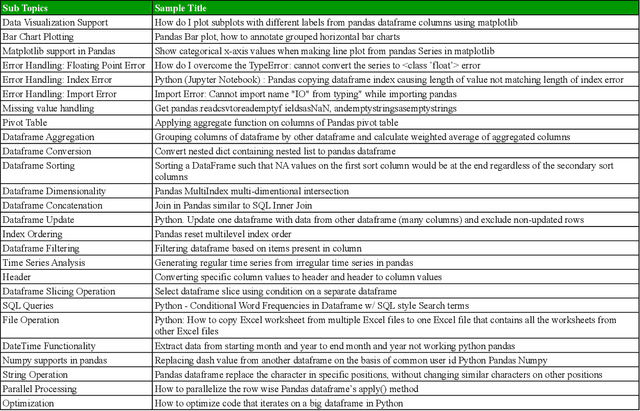
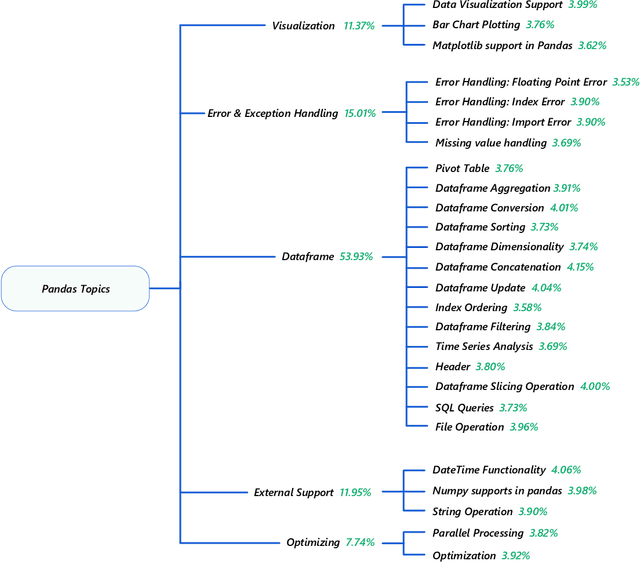
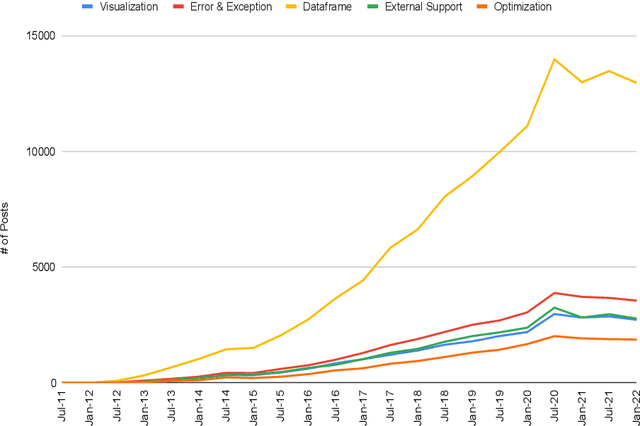
Pandas is defined as a software library which is used for data analysis in Python programming language. As pandas is a fast, easy and open source data analysis tool, it is rapidly used in different software engineering projects like software development, machine learning, computer vision, natural language processing, robotics, and others. So a huge interests are shown in software developers regarding pandas and a huge number of discussions are now becoming dominant in online developer forums, like Stack Overflow (SO). Such discussions can help to understand the popularity of pandas library and also can help to understand the importance, prevalence, difficulties of pandas topics. The main aim of this research paper is to find the popularity and difficulty of pandas topics. For this regard, SO posts are collected which are related to pandas topic discussions. Topic modeling are done on the textual contents of the posts. We found 26 topics which we further categorized into 5 board categories. We observed that developers discuss variety of pandas topics in SO related to error and excepting handling, visualization, External support, dataframe, and optimization. In addition, a trend chart is generated according to the discussion of topics in a predefined time series. The finding of this paper can provide a path to help the developers, educators and learners. For example, beginner developers can learn most important topics in pandas which are essential for develop any model. Educators can understand the topics which seem hard to learners and can build different tutorials which can make that pandas topic understandable. From this empirical study it is possible to understand the preferences of developers in pandas topic by processing their SO posts
Can Transformer Models Effectively Detect Software Aspects in StackOverflow Discussion?
Sep 24, 2022



Dozens of new tools and technologies are being incorporated to help developers, which is becoming a source of consternation as they struggle to choose one over the others. For example, there are at least ten frameworks available to developers for developing web applications, posing a conundrum in selecting the best one that meets their needs. As a result, developers are continuously searching for all of the benefits and drawbacks of each API, framework, tool, and so on. One of the typical approaches is to examine all of the features through official documentation and discussion. This approach is time-consuming, often makes it difficult to determine which aspects are the most important to a particular developer and whether a particular aspect is important to the community at large. In this paper, we have used a benchmark API aspects dataset (Opiner) collected from StackOverflow posts and observed how Transformer models (BERT, RoBERTa, DistilBERT, and XLNet) perform in detecting software aspects in textual developer discussion with respect to the baseline Support Vector Machine (SVM) model. Through extensive experimentation, we have found that transformer models improve the performance of baseline SVM for most of the aspects, i.e., `Performance', `Security', `Usability', `Documentation', `Bug', `Legal', `OnlySentiment', and `Others'. However, the models fail to apprehend some of the aspects (e.g., `Community' and `Potability') and their performance varies depending on the aspects. Also, larger architectures like XLNet are ineffective in interpreting software aspects compared to smaller architectures like DistilBERT.
Effectiveness of Transformer Models on IoT Security Detection in StackOverflow Discussions
Jul 29, 2022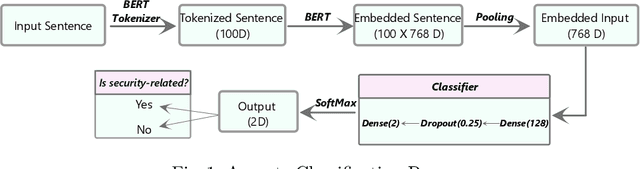
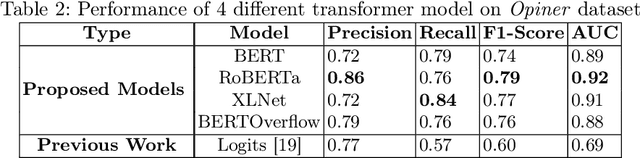
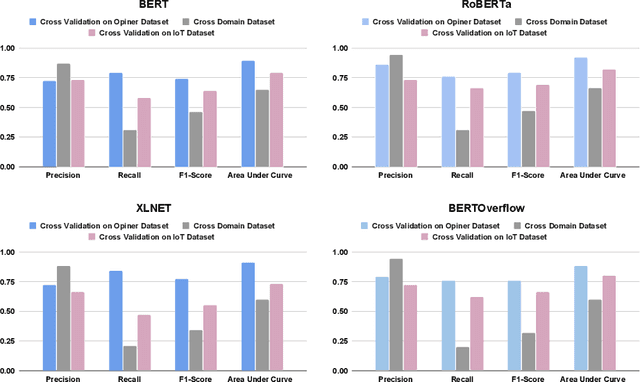
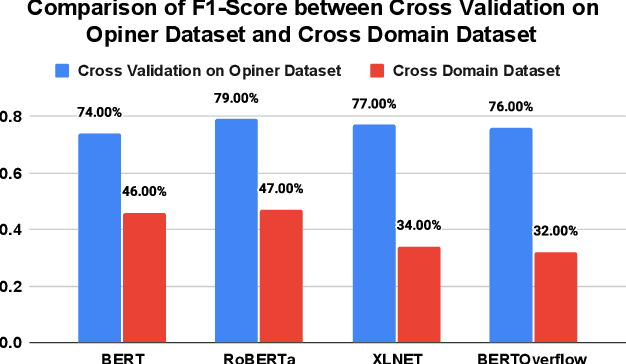
The Internet of Things (IoT) is an emerging concept that directly links to the billions of physical items, or "things", that are connected to the Internet and are all gathering and exchanging information between devices and systems. However, IoT devices were not built with security in mind, which might lead to security vulnerabilities in a multi-device system. Traditionally, we investigated IoT issues by polling IoT developers and specialists. This technique, however, is not scalable since surveying all IoT developers is not feasible. Another way to look into IoT issues is to look at IoT developer discussions on major online development forums like Stack Overflow (SO). However, finding discussions that are relevant to IoT issues is challenging since they are frequently not categorized with IoT-related terms. In this paper, we present the "IoT Security Dataset", a domain-specific dataset of 7147 samples focused solely on IoT security discussions. As there are no automated tools to label these samples, we manually labeled them. We further employed multiple transformer models to automatically detect security discussions. Through rigorous investigations, we found that IoT security discussions are different and more complex than traditional security discussions. We demonstrated a considerable performance loss (up to 44%) of transformer models on cross-domain datasets when we transferred knowledge from a general-purpose dataset "Opiner", supporting our claim. Thus, we built a domain-specific IoT security detector with an F1-Score of 0.69. We have made the dataset public in the hope that developers would learn more about the security discussion and vendors would enhance their concerns about product security.
An Empirical Study of IoT Security Aspects at Sentence-Level in Developer Textual Discussions
Jun 07, 2022
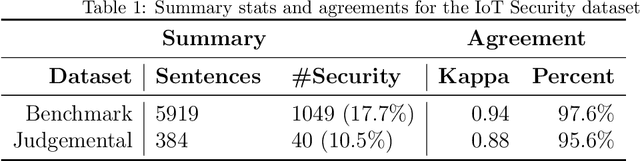
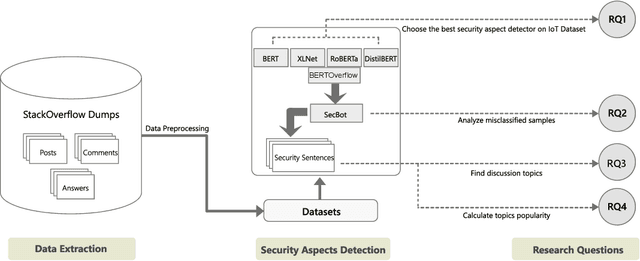
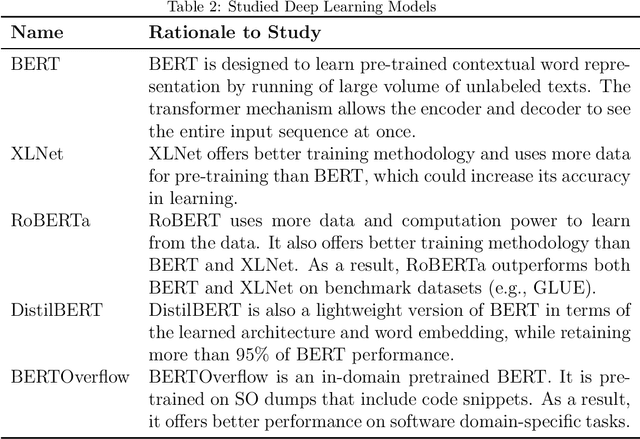
IoT is a rapidly emerging paradigm that now encompasses almost every aspect of our modern life. As such, ensuring the security of IoT devices is crucial. IoT devices can differ from traditional computing, thereby the design and implementation of proper security measures can be challenging in IoT devices. We observed that IoT developers discuss their security-related challenges in developer forums like Stack Overflow(SO). However, we find that IoT security discussions can also be buried inside non-security discussions in SO. In this paper, we aim to understand the challenges IoT developers face while applying security practices and techniques to IoT devices. We have two goals: (1) Develop a model that can automatically find security-related IoT discussions in SO, and (2) Study the model output to learn about IoT developer security-related challenges. First, we download 53K posts from SO that contain discussions about IoT. Second, we manually labeled 5,919 sentences from 53K posts as 1 or 0. Third, we use this benchmark to investigate a suite of deep learning transformer models. The best performing model is called SecBot. Fourth, we apply SecBot on the entire posts and find around 30K security related sentences. Fifth, we apply topic modeling to the security-related sentences. Then we label and categorize the topics. Sixth, we analyze the evolution of the topics in SO. We found that (1) SecBot is based on the retraining of the deep learning model RoBERTa. SecBot offers the best F1-Score of 0.935, (2) there are six error categories in misclassified samples by SecBot. SecBot was mostly wrong when the keywords/contexts were ambiguous (e.g., gateway can be a security gateway or a simple gateway), (3) there are 9 security topics grouped into three categories: Software, Hardware, and Network, and (4) the highest number of topics belongs to software security, followed by network security.