 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Bias Mitigation for Bangla Classification Tasks
Nov 16, 2024



In this study, we investigate gender bias in Bangla pretrained language models, a largely under explored area in low-resource languages. To assess this bias, we applied gender-name swapping techniques to existing datasets, creating four manually annotated, task-specific datasets for sentiment analysis, toxicity detection, hate speech detection, and sarcasm detection. By altering names and gender-specific terms, we ensured these datasets were suitable for detecting and mitigating gender bias. We then proposed a joint loss optimization technique to mitigate gender bias across task-specific pretrained models. Our approach was evaluated against existing bias mitigation methods, with results showing that our technique not only effectively reduces bias but also maintains competitive accuracy compared to other baseline approaches. To promote further research, we have made both our implementation and datasets publicly available https://github.com/sajib-kumar/Gender-Bias-Mitigation-From-Bangla-PLM
Explainable Cost-Sensitive Deep Neural Networks for Brain Tumor Detection from Brain MRI Images considering Data Imbalance
Aug 01, 2023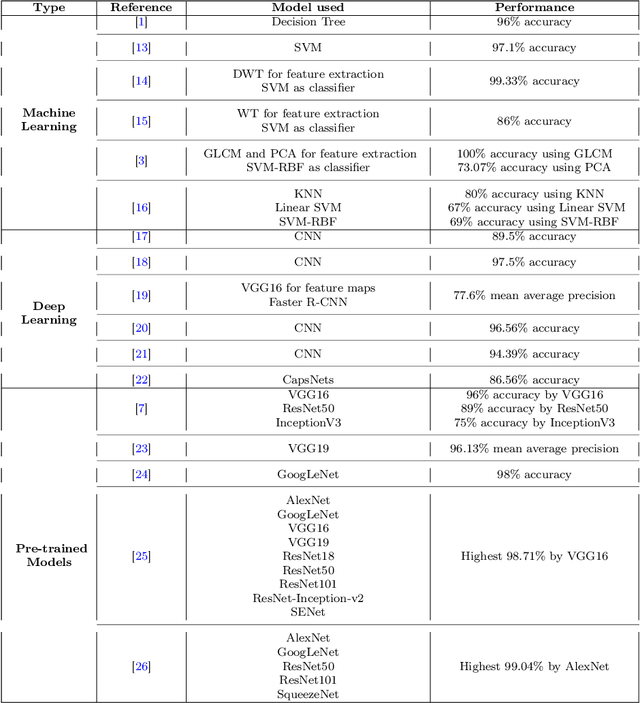

This paper presents a research study on the use of Convolutional Neural Network (CNN), ResNet50, InceptionV3, EfficientNetB0 and NASNetMobile models to efficiently detect brain tumors in order to reduce the time required for manual review of the report and create an automated system for classifying brain tumors. An automated pipeline is proposed, which encompasses five models: CNN, ResNet50, InceptionV3, EfficientNetB0 and NASNetMobile. The performance of the proposed architecture is evaluated on a balanced dataset and found to yield an accuracy of 99.33% for fine-tuned InceptionV3 model. Furthermore, Explainable AI approaches are incorporated to visualize the model's latent behavior in order to understand its black box behavior. To further optimize the training process, a cost-sensitive neural network approach has been proposed in order to work with imbalanced datasets which has achieved almost 4% more accuracy than the conventional models used in our experiments. The cost-sensitive InceptionV3 (CS-InceptionV3) and CNN (CS-CNN) show a promising accuracy of 92.31% and a recall value of 1.00 respectively on an imbalanced dataset. The proposed models have shown great potential in improving tumor detection accuracy and must be further developed for application in practical solutions. We have provided the datasets and made our implementations publicly available at - https://github.com/shahariar-shibli/Explainable-Cost-Sensitive-Deep-Neural-Networks-for-Brain-Tumor-Detection-from-Brain-MRI-Images
An Empirical Studies on How the Developers Discussed about Pandas Topics
Oct 07, 2022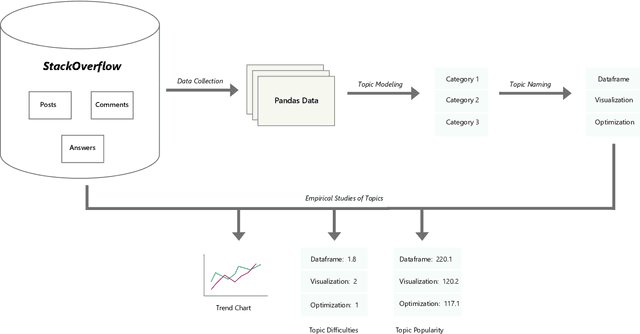
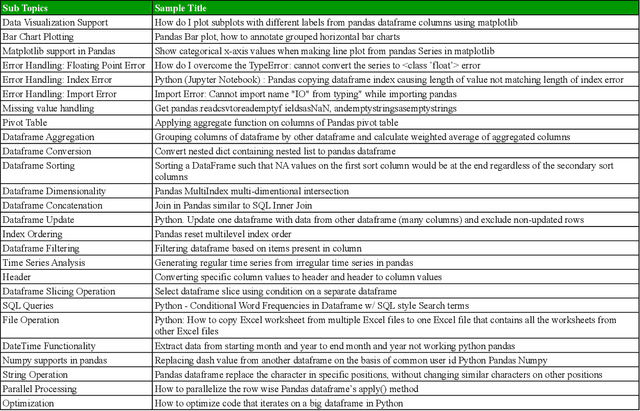
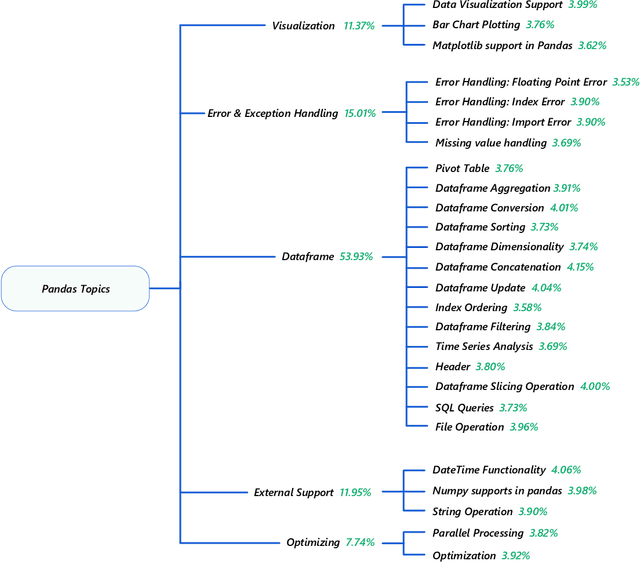
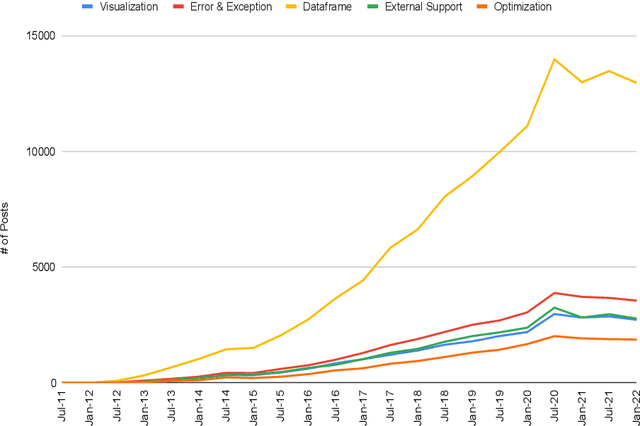
Pandas is defined as a software library which is used for data analysis in Python programming language. As pandas is a fast, easy and open source data analysis tool, it is rapidly used in different software engineering projects like software development, machine learning, computer vision, natural language processing, robotics, and others. So a huge interests are shown in software developers regarding pandas and a huge number of discussions are now becoming dominant in online developer forums, like Stack Overflow (SO). Such discussions can help to understand the popularity of pandas library and also can help to understand the importance, prevalence, difficulties of pandas topics. The main aim of this research paper is to find the popularity and difficulty of pandas topics. For this regard, SO posts are collected which are related to pandas topic discussions. Topic modeling are done on the textual contents of the posts. We found 26 topics which we further categorized into 5 board categories. We observed that developers discuss variety of pandas topics in SO related to error and excepting handling, visualization, External support, dataframe, and optimization. In addition, a trend chart is generated according to the discussion of topics in a predefined time series. The finding of this paper can provide a path to help the developers, educators and learners. For example, beginner developers can learn most important topics in pandas which are essential for develop any model. Educators can understand the topics which seem hard to learners and can build different tutorials which can make that pandas topic understandable. From this empirical study it is possible to understand the preferences of developers in pandas topic by processing their SO posts
A Comparative Study on COVID-19 Fake News Detection Using Different Transformer Based Models
Aug 02, 2022
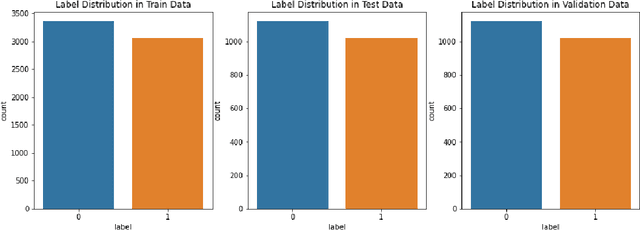
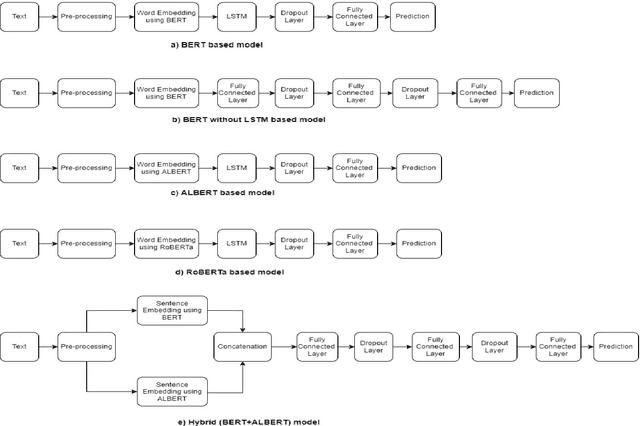

The rapid advancement of social networks and the convenience of internet availability have accelerated the rampant spread of false news and rumors on social media sites. Amid the COVID 19 epidemic, this misleading information has aggravated the situation by putting peoples mental and physical lives in danger. To limit the spread of such inaccuracies, identifying the fake news from online platforms could be the first and foremost step. In this research, the authors have conducted a comparative analysis by implementing five transformer based models such as BERT, BERT without LSTM, ALBERT, RoBERTa, and a Hybrid of BERT & ALBERT in order to detect the fraudulent news of COVID 19 from the internet. COVID 19 Fake News Dataset has been used for training and testing the models. Among all these models, the RoBERTa model has performed better than other models by obtaining an F1 score of 0.98 in both real and fake classes.