 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing AI Trustworthiness Through Patient Simulation: Risk Assessment of Conversational Agents for Antidepressant Selection
Feb 11, 2026Objective: This paper introduces a patient simulator designed to enable scalable, automated evaluation of healthcare conversational agents. The simulator generates realistic, controllable patient interactions that systematically vary across medical, linguistic, and behavioral dimensions, allowing annotators and an independent AI judge to assess agent performance, identify hallucinations and inaccuracies, and characterize risk patterns across diverse patient populations. Methods: The simulator is grounded in the NIST AI Risk Management Framework and integrates three profile components reflecting different dimensions of patient variation: (1) medical profiles constructed from electronic health records in the All of Us Research Program; (2) linguistic profiles modeling variation in health literacy and condition-specific communication patterns; and (3) behavioral profiles representing empirically observed interaction patterns, including cooperation, distraction, and adversarial engagement. We evaluated the simulator's effectiveness in identifying errors in an AI decision aid for antidepressant selection. Results: We generated 500 conversations between the patient simulator and the AI decision aid across systematic combinations of five linguistic and three behavioral profiles. Human annotators assessed 1,787 medical concepts across 100 conversations, achieving high agreement (F1=0.94, \k{appa}=0.73), and the LLM judge achieved comparable agreement with human annotators (F1=0.94, \k{appa}=0.78; paired bootstrap p=0.21). The simulator revealed a monotonic degradation in AI decision aid performance across the health literacy spectrum: rank-one concept retrieval accuracy increased from 47.9% for limited health literacy to 69.1% for functional and 81.6% for proficient.
Explainable Cost-Sensitive Deep Neural Networks for Brain Tumor Detection from Brain MRI Images considering Data Imbalance
Aug 01, 2023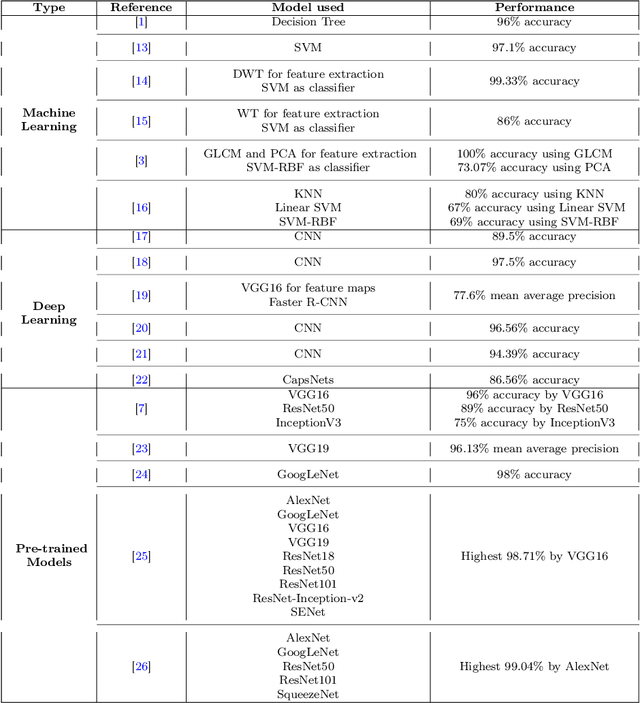
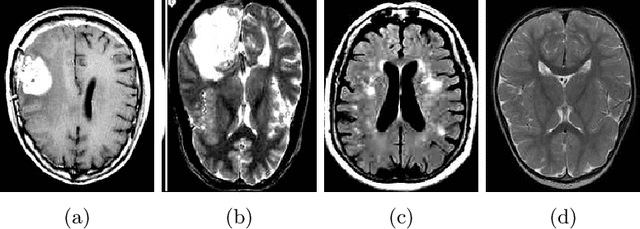

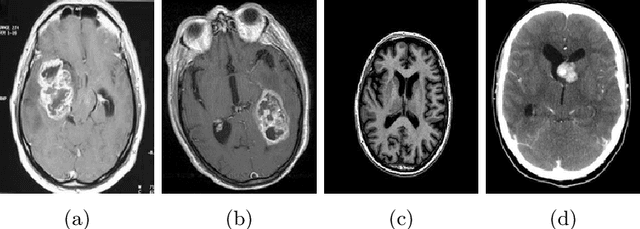
This paper presents a research study on the use of Convolutional Neural Network (CNN), ResNet50, InceptionV3, EfficientNetB0 and NASNetMobile models to efficiently detect brain tumors in order to reduce the time required for manual review of the report and create an automated system for classifying brain tumors. An automated pipeline is proposed, which encompasses five models: CNN, ResNet50, InceptionV3, EfficientNetB0 and NASNetMobile. The performance of the proposed architecture is evaluated on a balanced dataset and found to yield an accuracy of 99.33% for fine-tuned InceptionV3 model. Furthermore, Explainable AI approaches are incorporated to visualize the model's latent behavior in order to understand its black box behavior. To further optimize the training process, a cost-sensitive neural network approach has been proposed in order to work with imbalanced datasets which has achieved almost 4% more accuracy than the conventional models used in our experiments. The cost-sensitive InceptionV3 (CS-InceptionV3) and CNN (CS-CNN) show a promising accuracy of 92.31% and a recall value of 1.00 respectively on an imbalanced dataset. The proposed models have shown great potential in improving tumor detection accuracy and must be further developed for application in practical solutions. We have provided the datasets and made our implementations publicly available at - https://github.com/shahariar-shibli/Explainable-Cost-Sensitive-Deep-Neural-Networks-for-Brain-Tumor-Detection-from-Brain-MRI-Images
Bengali Handwritten Digit Recognition using CNN with Explainable AI
Dec 23, 2022



Handwritten character recognition is a hot topic for research nowadays. If we can convert a handwritten piece of paper into a text-searchable document using the Optical Character Recognition (OCR) technique, we can easily understand the content and do not need to read the handwritten document. OCR in the English language is very common, but in the Bengali language, it is very hard to find a good quality OCR application. If we can merge machine learning and deep learning with OCR, it could be a huge contribution to this field. Various researchers have proposed a number of strategies for recognizing Bengali handwritten characters. A lot of ML algorithms and deep neural networks were used in their work, but the explanations of their models are not available. In our work, we have used various machine learning algorithms and CNN to recognize handwritten Bengali digits. We have got acceptable accuracy from some ML models, and CNN has given us great testing accuracy. Grad-CAM was used as an XAI method on our CNN model, which gave us insights into the model and helped us detect the origin of interest for recognizing a digit from an image.