 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Vision-Language Model Framework with Adaptive PID-Tversky Loss for Lumbar Spinal Stenosis Diagnosis
Apr 02, 2026Lumbar Spinal Stenosis (LSS) diagnosis remains a critical clinical challenge, with diagnosis heavily dependent on labor-intensive manual interpretation of multi-view Magnetic Resonance Imaging (MRI), leading to substantial inter-observer variability and diagnostic delays. Existing vision-language models simultaneously fail to address the extreme class imbalance prevalent in clinical segmentation datasets while preserving spatial accuracy, primarily due to global pooling mechanisms that discard crucial anatomical hierarchies. We present an end-to-end Explainable Vision-Language Model framework designed to overcome these limitations, achieved through two principal objectives. We propose a Spatial Patch Cross-Attention module that enables precise, text-directed localization of spinal anomalies with spatial precision. A novel Adaptive PID-Tversky Loss function by integrating control theory principles dynamically further modifies training penalties to specifically address difficult, under-segmented minority instances. By incorporating foundational VLMs alongside an Automated Radiology Report Generation module, our framework demonstrates considerable performance: a diagnostic classification accuracy of 90.69%, a macro-averaged Dice score of 0.9512 for segmentation, and a CIDEr score of 92.80%. Furthermore, the framework shows explainability by converting complex segmentation predictions into radiologist-style clinical reports, thereby establishing a new benchmark for transparent, interpretable AI in clinical medical imaging that keeps essential human supervision while enhancing diagnostic capabilities.
Retrieval Augmented Enhanced Dual Co-Attention Framework for Target Aware Multimodal Bengali Hateful Meme Detection
Feb 22, 2026Hateful content on social media increasingly appears as multimodal memes that combine images and text to convey harmful narratives. In low-resource languages such as Bengali, automated detection remains challenging due to limited annotated data, class imbalance, and pervasive code-mixing. To address these issues, we augment the Bengali Hateful Memes (BHM) dataset with semantically aligned samples from the Multimodal Aggression Dataset in Bengali (MIMOSA), improving both class balance and semantic diversity. We propose the Enhanced Dual Co-attention Framework (xDORA), integrating vision encoders (CLIP, DINOv2) and multilingual text encoders (XGLM, XLM-R) via weighted attention pooling to learn robust cross-modal representations. Building on these embeddings, we develop a FAISS-based k-nearest neighbor classifier for non-parametric inference and introduce RAG-Fused DORA, which incorporates retrieval-driven contextual reasoning. We further evaluate LLaVA under zero-shot, few-shot, and retrieval-augmented prompting settings. Experiments on the extended dataset show that xDORA (CLIP + XLM-R) achieves macro-average F1-scores of 0.78 for hateful meme identification and 0.71 for target entity detection, while RAG-Fused DORA improves performance to 0.79 and 0.74, yielding gains over the DORA baseline. The FAISS-based classifier performs competitively and demonstrates robustness for rare classes through semantic similarity modeling. In contrast, LLaVA exhibits limited effectiveness in few-shot settings, with only modest improvements under retrieval augmentation, highlighting constraints of pretrained vision-language models for code-mixed Bengali content without fine-tuning. These findings demonstrate the effectiveness of supervised, retrieval-augmented, and non-parametric multimodal frameworks for addressing linguistic and cultural complexities in low-resource hate speech detection.
A Hybrid Federated Learning Based Ensemble Approach for Lung Disease Diagnosis Leveraging Fusion of SWIN Transformer and CNN
Feb 19, 2026The significant advancements in computational power cre- ate a vast opportunity for using Artificial Intelligence in different ap- plications of healthcare and medical science. A Hybrid FL-Enabled Ensemble Approach For Lung Disease Diagnosis Leveraging a Combination of SWIN Transformer and CNN is the combination of cutting-edge technology of AI and Federated Learning. Since, medi- cal specialists and hospitals will have shared data space, based on that data, with the help of Artificial Intelligence and integration of federated learning, we can introduce a secure and distributed system for medical data processing and create an efficient and reliable system. The proposed hybrid model enables the detection of COVID-19 and Pneumonia based on x-ray reports. We will use advanced and the latest available tech- nology offered by Tensorflow and Keras along with Microsoft-developed Vision Transformer, that can help to fight against the pandemic that the world has to fight together as a united. We focused on using the latest available CNN models (DenseNet201, Inception V3, VGG 19) and the Transformer model SWIN Transformer in order to prepare our hy- brid model that can provide a reliable solution as a helping hand for the physician in the medical field. In this research, we will discuss how the Federated learning-based Hybrid AI model can improve the accuracy of disease diagnosis and severity prediction of a patient using the real-time continual learning approach and how the integration of federated learn- ing can ensure hybrid model security and keep the authenticity of the information.
When LLM meets Fuzzy-TOPSIS for Personnel Selection through Automated Profile Analysis
Jan 30, 2026In this highly competitive employment environment, the selection of suitable personnel is essential for organizational success. This study presents an automated personnel selection system that utilizes sophisticated natural language processing (NLP) methods to assess and rank software engineering applicants. A distinctive dataset was created by aggregating LinkedIn profiles that include essential features such as education, work experience, abilities, and self-introduction, further enhanced with expert assessments to function as standards. The research combines large language models (LLMs) with multicriteria decision-making (MCDM) theory to develop the LLM-TOPSIS framework. In this context, we utilized the TOPSIS method enhanced by fuzzy logic (Fuzzy TOPSIS) to address the intrinsic ambiguity and subjectivity in human assessments. We utilized triangular fuzzy numbers (TFNs) to describe criteria weights and scores, thereby addressing the ambiguity frequently encountered in candidate evaluations. For candidate ranking, the DistilRoBERTa model was fine-tuned and integrated with the fuzzy TOPSIS method, achieving rankings closely aligned with human expert evaluations and attaining an accuracy of up to 91% for the Experience attribute and the Overall attribute. The study underlines the potential of NLP-driven frameworks to improve recruitment procedures by boosting scalability, consistency, and minimizing prejudice. Future endeavors will concentrate on augmenting the dataset, enhancing model interpretability, and verifying the system in actual recruitment scenarios to better evaluate its practical applicability. This research highlights the intriguing potential of merging NLP with fuzzy decision-making methods in personnel selection, enabling scalable and unbiased solutions to recruitment difficulties.
* 10 pages, 8 figures. This paper has been peer-reviewed and published in IEEE Access. The arXiv version corresponds to the accepted author manuscript (AAM)
An Extensive Study on D2C: Overfitting Remediation in Deep Learning Using a Decentralized Approach
Nov 24, 2024Overfitting remains a significant challenge in deep learning, often arising from data outliers, noise, and limited training data. To address this, we propose Divide2Conquer (D2C), a novel technique to mitigate overfitting. D2C partitions the training data into multiple subsets and trains identical models independently on each subset. To balance model generalization and subset-specific learning, the model parameters are periodically aggregated and averaged during training. This process enables the learning of robust patterns while minimizing the influence of outliers and noise. Empirical evaluations on benchmark datasets across diverse deep-learning tasks demonstrate that D2C significantly enhances generalization performance, particularly with larger datasets. Our analysis includes evaluations of decision boundaries, loss curves, and other performance metrics, highlighting D2C's effectiveness both as a standalone technique and in combination with other overfitting reduction methods. We further provide a rigorous mathematical justification for D2C's underlying principles and examine its applicability across multiple domains. Finally, we explore the trade-offs associated with D2C and propose strategies to address them, offering a holistic view of its strengths and limitations. This study establishes D2C as a versatile and effective approach to combating overfitting in deep learning. Our codes are publicly available at: https://github.com/Saiful185/Divide2Conquer.
Larger models yield better results? Streamlined severity classification of ADHD-related concerns using BERT-based knowledge distillation
Oct 30, 2024This work focuses on the efficiency of the knowledge distillation approach in generating a lightweight yet powerful BERT based model for natural language processing applications. After the model creation, we applied the resulting model, LastBERT, to a real-world task classifying severity levels of Attention Deficit Hyperactivity Disorder (ADHD)-related concerns from social media text data. Referring to LastBERT, a customized student BERT model, we significantly lowered model parameters from 110 million BERT base to 29 million, resulting in a model approximately 73.64% smaller. On the GLUE benchmark, comprising paraphrase identification, sentiment analysis, and text classification, the student model maintained strong performance across many tasks despite this reduction. The model was also used on a real-world ADHD dataset with an accuracy and F1 score of 85%. When compared to DistilBERT (66M) and ClinicalBERT (110M), LastBERT demonstrated comparable performance, with DistilBERT slightly outperforming it at 87%, and ClinicalBERT achieving 86% across the same metrics. These findings highlight the LastBERT model's capacity to classify degrees of ADHD severity properly, so it offers a useful tool for mental health professionals to assess and comprehend material produced by users on social networking platforms. The study emphasizes the possibilities of knowledge distillation to produce effective models fit for use in resource-limited conditions, hence advancing NLP and mental health diagnosis. Furthermore underlined by the considerable decrease in model size without appreciable performance loss is the lower computational resources needed for training and deployment, hence facilitating greater applicability. Especially using readily available computational tools like Google Colab. This study shows the accessibility and usefulness of advanced NLP methods in pragmatic world applications.
Transforming Precision: A Comparative Analysis of Vision Transformers, CNNs, and Traditional ML for Knee Osteoarthritis Severity Diagnosis
Oct 26, 2024Knee osteoarthritis(KO) is a degenerative joint disease that can cause severe pain and impairment. With increased prevalence, precise diagnosis by medical imaging analytics is crucial for appropriate illness management. This research investigates a comparative analysis between traditional machine learning techniques and new deep learning models for diagnosing KO severity from X-ray pictures. This study does not introduce new architectural innovations but rather illuminates the robust applicability and comparative effectiveness of pre-existing ViT models in a medical imaging context, specifically for KO severity diagnosis. The insights garnered from this comparative analysis advocate for the integration of advanced ViT models in clinical diagnostic workflows, potentially revolutionizing the precision and reliability of KO assessments. This study does not introduce new architectural innovations but rather illuminates the robust applicability and comparative effectiveness of pre-existing ViT models in a medical imaging context, specifically for KO severity diagnosis. The insights garnered from this comparative analysis advocate for the integration of advanced ViT models in clinical diagnostic workflows, potentially revolutionizing the precision & reliability of KO assessments. The study utilizes an osteoarthritis dataset from the Osteoarthritis Initiative (OAI) comprising images with 5 severity categories and uneven class distribution. While classic machine learning models like GaussianNB and KNN struggle in feature extraction, Convolutional Neural Networks such as Inception-V3, VGG-19 achieve better accuracy between 55-65% by learning hierarchical visual patterns. However, Vision Transformer architectures like Da-VIT, GCViT and MaxViT emerge as indisputable champions, displaying 66.14% accuracy, 0.703 precision, 0.614 recall, AUC exceeding 0.835 thanks to self-attention processes.
An advanced data fabric architecture leveraging homomorphic encryption and federated learning
Feb 15, 2024

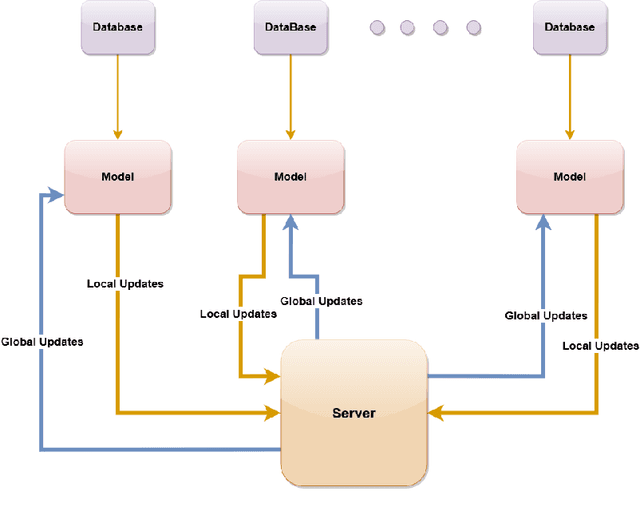

Data fabric is an automated and AI-driven data fusion approach to accomplish data management unification without moving data to a centralized location for solving complex data problems. In a Federated learning architecture, the global model is trained based on the learned parameters of several local models that eliminate the necessity of moving data to a centralized repository for machine learning. This paper introduces a secure approach for medical image analysis using federated learning and partially homomorphic encryption within a distributed data fabric architecture. With this method, multiple parties can collaborate in training a machine-learning model without exchanging raw data but using the learned or fused features. The approach complies with laws and regulations such as HIPAA and GDPR, ensuring the privacy and security of the data. The study demonstrates the method's effectiveness through a case study on pituitary tumor classification, achieving a significant level of accuracy. However, the primary focus of the study is on the development and evaluation of federated learning and partially homomorphic encryption as tools for secure medical image analysis. The results highlight the potential of these techniques to be applied to other privacy-sensitive domains and contribute to the growing body of research on secure and privacy-preserving machine learning.
A Computer Vision Based Approach for Stalking Detection Using a CNN-LSTM-MLP Hybrid Fusion Model
Feb 05, 2024Criminal and suspicious activity detection has become a popular research topic in recent years. The rapid growth of computer vision technologies has had a crucial impact on solving this issue. However, physical stalking detection is still a less explored area despite the evolution of modern technology. Nowadays, stalking in public places has become a common occurrence with women being the most affected. Stalking is a visible action that usually occurs before any criminal activity begins as the stalker begins to follow, loiter, and stare at the victim before committing any criminal activity such as assault, kidnapping, rape, and so on. Therefore, it has become a necessity to detect stalking as all of these criminal activities can be stopped in the first place through stalking detection. In this research, we propose a novel deep learning-based hybrid fusion model to detect potential stalkers from a single video with a minimal number of frames. We extract multiple relevant features, such as facial landmarks, head pose estimation, and relative distance, as numerical values from video frames. This data is fed into a multilayer perceptron (MLP) to perform a classification task between a stalking and a non-stalking scenario. Simultaneously, the video frames are fed into a combination of convolutional and LSTM models to extract the spatio-temporal features. We use a fusion of these numerical and spatio-temporal features to build a classifier to detect stalking incidents. Additionally, we introduce a dataset consisting of stalking and non-stalking videos gathered from various feature films and television series, which is also used to train the model. The experimental results show the efficiency and dynamism of our proposed stalker detection system, achieving 89.58% testing accuracy with a significant improvement as compared to the state-of-the-art approaches.
SynthEnsemble: A Fusion of CNN, Vision Transformer, and Hybrid Models for Multi-Label Chest X-Ray Classification
Nov 20, 2023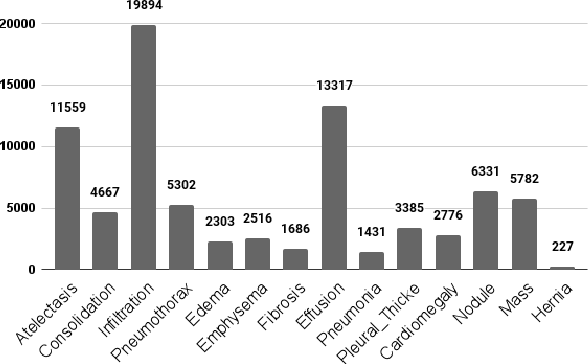
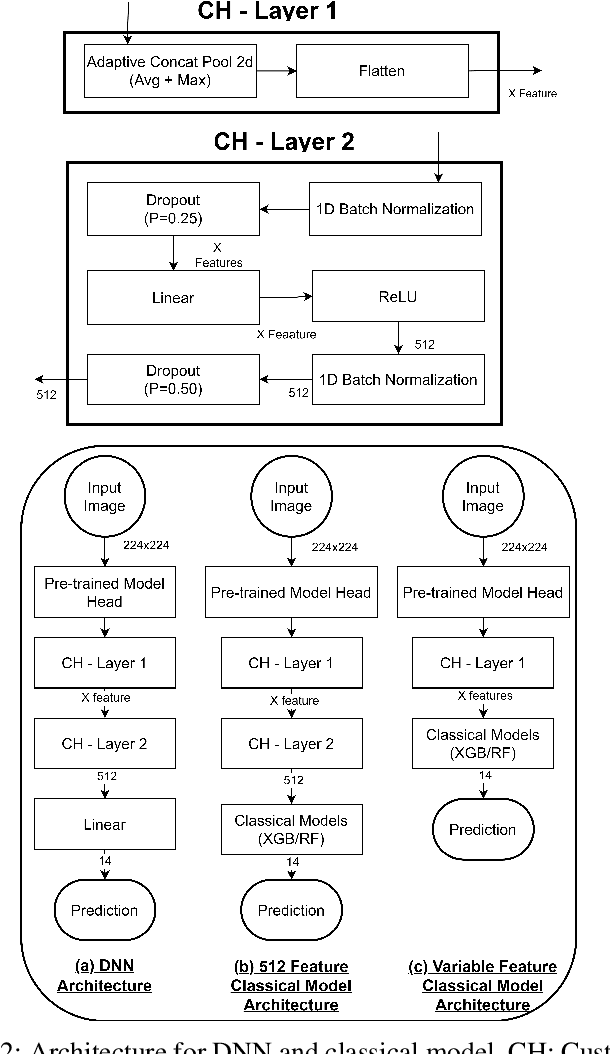
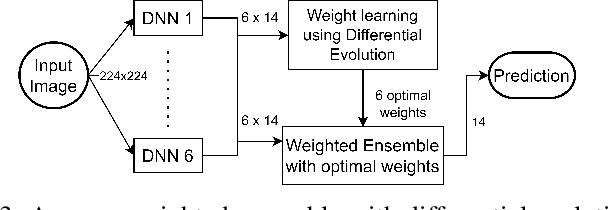
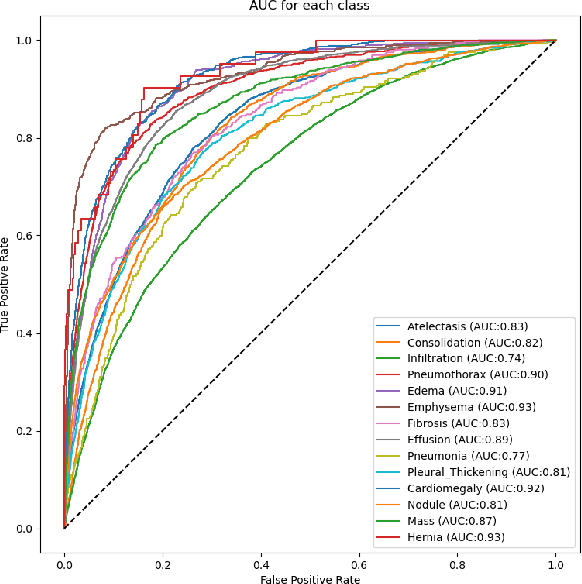
Chest X-rays are widely used to diagnose thoracic diseases, but the lack of detailed information about these abnormalities makes it challenging to develop accurate automated diagnosis systems, which is crucial for early detection and effective treatment. To address this challenge, we employed deep learning techniques to identify patterns in chest X-rays that correspond to different diseases. We conducted experiments on the "ChestX-ray14" dataset using various pre-trained CNNs, transformers, hybrid(CNN+Transformer) models and classical models. The best individual model was the CoAtNet, which achieved an area under the receiver operating characteristic curve (AUROC) of 84.2%. By combining the predictions of all trained models using a weighted average ensemble where the weight of each model was determined using differential evolution, we further improved the AUROC to 85.4%, outperforming other state-of-the-art methods in this field. Our findings demonstrate the potential of deep learning techniques, particularly ensemble deep learning, for improving the accuracy of automatic diagnosis of thoracic diseases from chest X-rays.