 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLM meets Fuzzy-TOPSIS for Personnel Selection through Automated Profile Analysis
Jan 30, 2026In this highly competitive employment environment, the selection of suitable personnel is essential for organizational success. This study presents an automated personnel selection system that utilizes sophisticated natural language processing (NLP) methods to assess and rank software engineering applicants. A distinctive dataset was created by aggregating LinkedIn profiles that include essential features such as education, work experience, abilities, and self-introduction, further enhanced with expert assessments to function as standards. The research combines large language models (LLMs) with multicriteria decision-making (MCDM) theory to develop the LLM-TOPSIS framework. In this context, we utilized the TOPSIS method enhanced by fuzzy logic (Fuzzy TOPSIS) to address the intrinsic ambiguity and subjectivity in human assessments. We utilized triangular fuzzy numbers (TFNs) to describe criteria weights and scores, thereby addressing the ambiguity frequently encountered in candidate evaluations. For candidate ranking, the DistilRoBERTa model was fine-tuned and integrated with the fuzzy TOPSIS method, achieving rankings closely aligned with human expert evaluations and attaining an accuracy of up to 91% for the Experience attribute and the Overall attribute. The study underlines the potential of NLP-driven frameworks to improve recruitment procedures by boosting scalability, consistency, and minimizing prejudice. Future endeavors will concentrate on augmenting the dataset, enhancing model interpretability, and verifying the system in actual recruitment scenarios to better evaluate its practical applicability. This research highlights the intriguing potential of merging NLP with fuzzy decision-making methods in personnel selection, enabling scalable and unbiased solutions to recruitment difficulties.
* 10 pages, 8 figures. This paper has been peer-reviewed and published in IEEE Access. The arXiv version corresponds to the accepted author manuscript (AAM)
Enhancing Multi-Class Disease Classification: Neoplasms, Cardiovascular, Nervous System, and Digestive Disorders Using Advanced LLMs
Nov 19, 2024In this research, we explored the improvement in terms of multi-class disease classification via pre-trained language models over Medical-Abstracts-TC-Corpus that spans five medical conditions. We excluded non-cancer conditions and examined four specific diseases. We assessed four LLMs, BioBERT, XLNet, and BERT, as well as a novel base model (Last-BERT). BioBERT, which was pre-trained on medical data, demonstrated superior performance in medical text classification (97% accuracy). Surprisingly, XLNet followed closely (96% accuracy), demonstrating its generalizability across domains even though it was not pre-trained on medical data. LastBERT, a custom model based on the lighter version of BERT, also proved competitive with 87.10% accuracy (just under BERT's 89.33%). Our findings confirm the importance of specialized models such as BioBERT and also support impressions around more general solutions like XLNet and well-tuned transformer architectures with fewer parameters (in this case, LastBERT) in medical domain tasks.
Strengthening Fake News Detection: Leveraging SVM and Sophisticated Text Vectorization Techniques. Defying BERT?
Nov 19, 2024
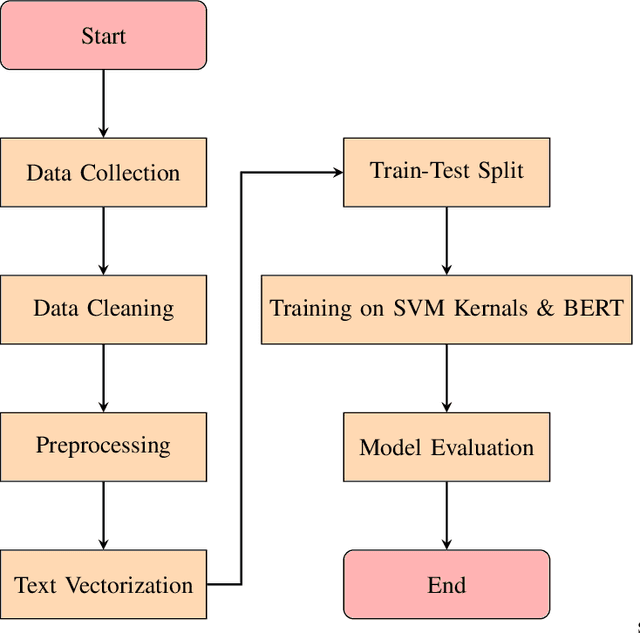
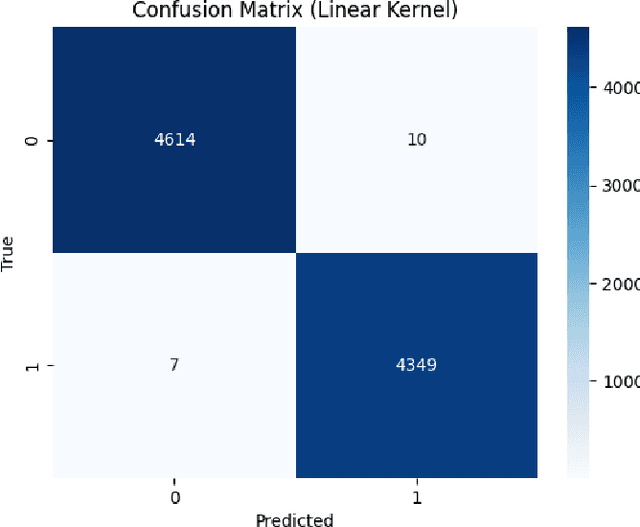
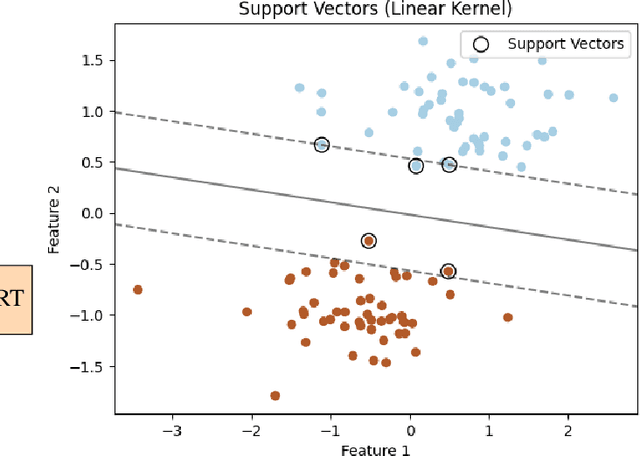
The rapid spread of misinformation, particularly through online platforms, underscores the urgent need for reliable detection systems. This study explores the utilization of machine learning and natural language processing, specifically Support Vector Machines (SVM) and BERT, to detect news that are fake. We employ three distinct text vectorization methods for SVM: Term Frequency Inverse Document Frequency (TF-IDF), Word2Vec, and Bag of Words (BoW) evaluating their effectiveness in distinguishing between genuine and fake news. Additionally, we compare these methods against the transformer large language model, BERT. Our comprehensive approach includes detailed preprocessing steps, rigorous model implementation, and thorough evaluation to determine the most effective techniques. The results demonstrate that while BERT achieves superior accuracy with 99.98% and an F1-score of 0.9998, the SVM model with a linear kernel and BoW vectorization also performs exceptionally well, achieving 99.81% accuracy and an F1-score of 0.9980. These findings highlight that, despite BERT's superior performance, SVM models with BoW and TF-IDF vectorization methods come remarkably close, offering highly competitive performance with the advantage of lower computational requirements.
Larger models yield better results? Streamlined severity classification of ADHD-related concerns using BERT-based knowledge distillation
Oct 30, 2024This work focuses on the efficiency of the knowledge distillation approach in generating a lightweight yet powerful BERT based model for natural language processing applications. After the model creation, we applied the resulting model, LastBERT, to a real-world task classifying severity levels of Attention Deficit Hyperactivity Disorder (ADHD)-related concerns from social media text data. Referring to LastBERT, a customized student BERT model, we significantly lowered model parameters from 110 million BERT base to 29 million, resulting in a model approximately 73.64% smaller. On the GLUE benchmark, comprising paraphrase identification, sentiment analysis, and text classification, the student model maintained strong performance across many tasks despite this reduction. The model was also used on a real-world ADHD dataset with an accuracy and F1 score of 85%. When compared to DistilBERT (66M) and ClinicalBERT (110M), LastBERT demonstrated comparable performance, with DistilBERT slightly outperforming it at 87%, and ClinicalBERT achieving 86% across the same metrics. These findings highlight the LastBERT model's capacity to classify degrees of ADHD severity properly, so it offers a useful tool for mental health professionals to assess and comprehend material produced by users on social networking platforms. The study emphasizes the possibilities of knowledge distillation to produce effective models fit for use in resource-limited conditions, hence advancing NLP and mental health diagnosis. Furthermore underlined by the considerable decrease in model size without appreciable performance loss is the lower computational resources needed for training and deployment, hence facilitating greater applicability. Especially using readily available computational tools like Google Colab. This study shows the accessibility and usefulness of advanced NLP methods in pragmatic world applications.
Advanced Vision Transformers and Open-Set Learning for Robust Mosquito Classification: A Novel Approach to Entomological Studies
Aug 12, 2024



Mosquito-related diseases pose a significant threat to global public health, necessitating efficient and accurate mosquito classification for effective surveillance and control. This work presents an innovative approach to mosquito classification by leveraging state-of-the-art vision transformers and open-set learning techniques. A novel framework has been introduced that integrates Transformer-based deep learning models with comprehensive data augmentation and preprocessing methods, enabling robust and precise identification of ten mosquito species. The Swin Transformer model achieves the best performance for traditional closed-set learning with 99.80\% accuracy and 0.998 F1 score. The lightweight MobileViT technique attains an almost similar accuracy of 98.90\% with significantly reduced parameters and model complexities. Next, the applied deep learning models' adaptability and generalizability in a static environment have been enhanced by using new classes of data samples during the inference stage that have not been included in the training set. The proposed framework's ability to handle unseen classes like insects similar to mosquitoes, even humans, through open-set learning further enhances its practical applicability employing the OpenMax technique and Weibull distribution. The traditional CNN model, Xception, outperforms the latest transformer with higher accuracy and F1 score for open-set learning. The study's findings highlight the transformative potential of advanced deep-learning architectures in entomology, providing a strong groundwork for future research and development in mosquito surveillance and vector control. The implications of this work extend beyond mosquito classification, offering valuable insights for broader ecological and environmental monitoring applications.