 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-IC: Fusing a Single Layer Involution with Convolutions for Enhanced Medical Image Classification and Segmentation
Sep 27, 2024The majority of medical images, especially those that resemble cells, have similar characteristics. These images, which occur in a variety of shapes, often show abnormalities in the organ or cell region. The convolution operation possesses a restricted capability to extract visual patterns across several spatial regions of an image. The involution process, which is the inverse operation of convolution, complements this inherent lack of spatial information extraction present in convolutions. In this study, we investigate how applying a single layer of involution prior to a convolutional neural network (CNN) architecture can significantly improve classification and segmentation performance, with a comparatively negligible amount of weight parameters. The study additionally shows how excessive use of involution layers might result in inaccurate predictions in a particular type of medical image. According to our findings from experiments, the strategy of adding only a single involution layer before a CNN-based model outperforms most of the previous works.
Spatially Optimized Compact Deep Metric Learning Model for Similarity Search
Apr 09, 2024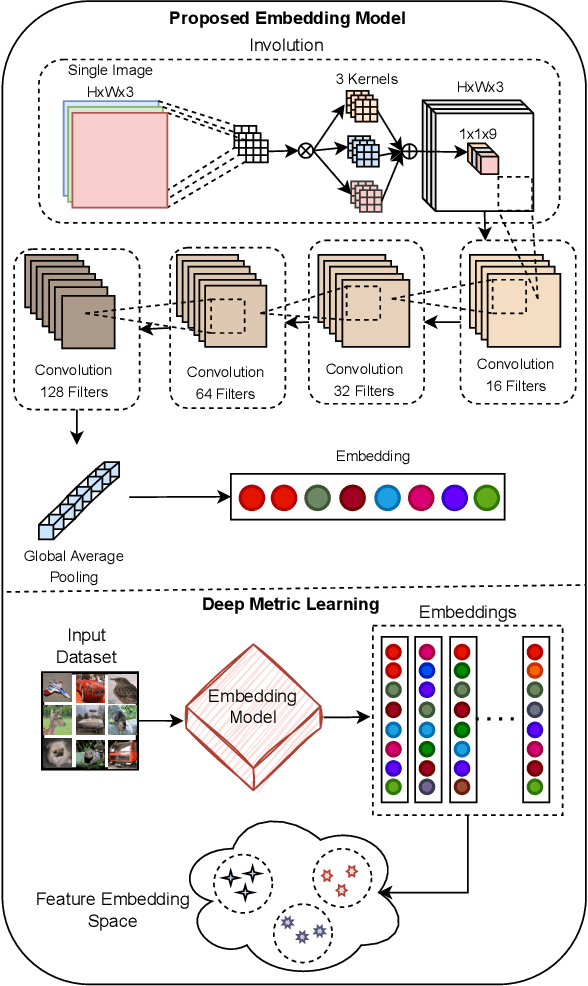
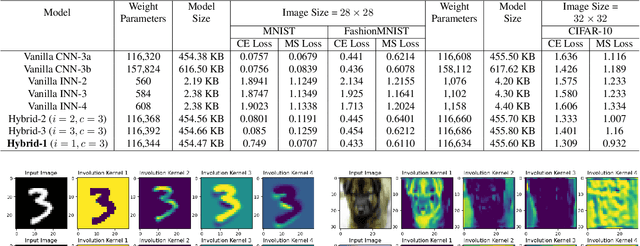

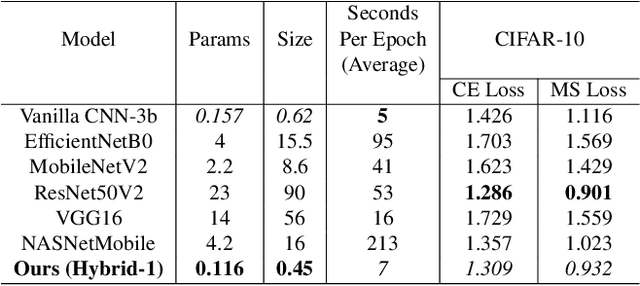
Spatial optimization is often overlooked in many computer vision tasks. Filters should be able to recognize the features of an object regardless of where it is in the image. Similarity search is a crucial task where spatial features decide an important output. The capacity of convolution to capture visual patterns across various locations is limited. In contrast to convolution, the involution kernel is dynamically created at each pixel based on the pixel value and parameters that have been learned. This study demonstrates that utilizing a single layer of involution feature extractor alongside a compact convolution model significantly enhances the performance of similarity search. Additionally, we improve predictions by using the GELU activation function rather than the ReLU. The negligible amount of weight parameters in involution with a compact model with better performance makes the model very useful in real-world implementations. Our proposed model is below 1 megabyte in size. We have experimented with our proposed methodology and other models on CIFAR-10, FashionMNIST, and MNIST datasets. Our proposed method outperforms across all three datasets.
A Computer Vision Based Approach for Stalking Detection Using a CNN-LSTM-MLP Hybrid Fusion Model
Feb 05, 2024Criminal and suspicious activity detection has become a popular research topic in recent years. The rapid growth of computer vision technologies has had a crucial impact on solving this issue. However, physical stalking detection is still a less explored area despite the evolution of modern technology. Nowadays, stalking in public places has become a common occurrence with women being the most affected. Stalking is a visible action that usually occurs before any criminal activity begins as the stalker begins to follow, loiter, and stare at the victim before committing any criminal activity such as assault, kidnapping, rape, and so on. Therefore, it has become a necessity to detect stalking as all of these criminal activities can be stopped in the first place through stalking detection. In this research, we propose a novel deep learning-based hybrid fusion model to detect potential stalkers from a single video with a minimal number of frames. We extract multiple relevant features, such as facial landmarks, head pose estimation, and relative distance, as numerical values from video frames. This data is fed into a multilayer perceptron (MLP) to perform a classification task between a stalking and a non-stalking scenario. Simultaneously, the video frames are fed into a combination of convolutional and LSTM models to extract the spatio-temporal features. We use a fusion of these numerical and spatio-temporal features to build a classifier to detect stalking incidents. Additionally, we introduce a dataset consisting of stalking and non-stalking videos gathered from various feature films and television series, which is also used to train the model. The experimental results show the efficiency and dynamism of our proposed stalker detection system, achieving 89.58% testing accuracy with a significant improvement as compared to the state-of-the-art approaches.
Explainable AI based Glaucoma Detection using Transfer Learning and LIME
Oct 07, 2022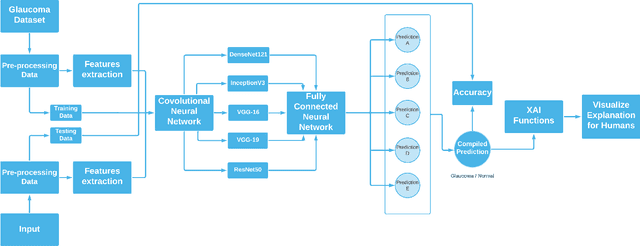

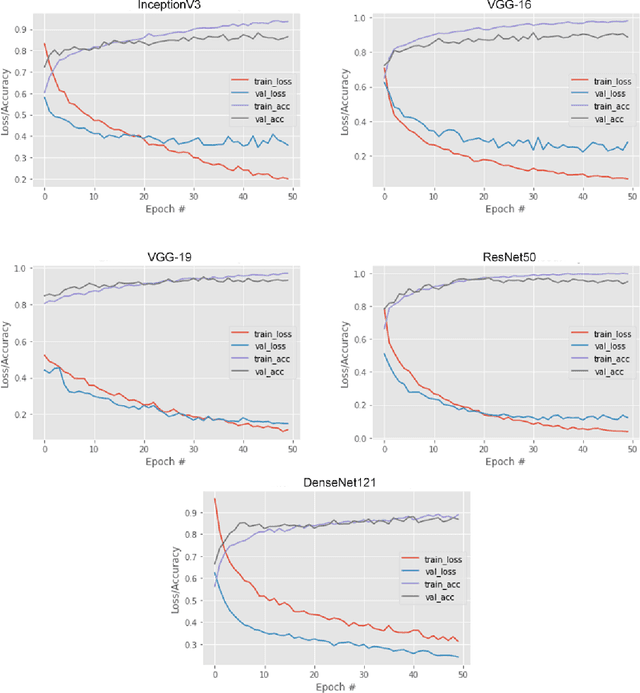
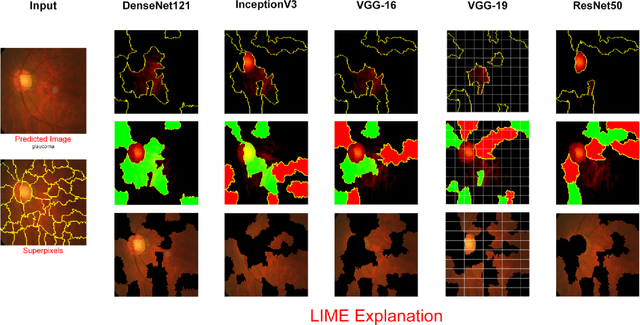
Glaucoma is the second driving reason for partial or complete blindness among all the visual deficiencies which mainly occurs because of excessive pressure in the eye due to anxiety or depression which damages the optic nerve and creates complications in vision. Traditional glaucoma screening is a time-consuming process that necessitates the medical professionals' constant attention, and even so time to time due to the time constrains and pressure they fail to classify correctly that leads to wrong treatment. Numerous efforts have been made to automate the entire glaucoma classification procedure however, these existing models in general have a black box characteristics that prevents users from understanding the key reasons behind the prediction and thus medical practitioners generally can not rely on these system. In this article after comparing with various pre-trained models, we propose a transfer learning model that is able to classify Glaucoma with 94.71\% accuracy. In addition, we have utilized Local Interpretable Model-Agnostic Explanations(LIME) that introduces explainability in our system. This improvement enables medical professionals obtain important and comprehensive information that aid them in making judgments. It also lessen the opacity and fragility of the traditional deep learning models.