 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Performance Analysis of Classification and Segmentation Models on Bangladeshi Pothole Dataset
Jan 11, 2025



The study involves a comprehensive performance analysis of popular classification and segmentation models, applied over a Bangladeshi pothole dataset, being developed by the authors of this research. This custom dataset of 824 samples, collected from the streets of Dhaka and Bogura performs competitively against the existing industrial and custom datasets utilized in the present literature. The dataset was further augmented four-fold for segmentation and ten-fold for classification evaluation. We tested nine classification models (CCT, CNN, INN, Swin Transformer, ConvMixer, VGG16, ResNet50, DenseNet201, and Xception) and four segmentation models (U-Net, ResU-Net, U-Net++, and Attention-Unet) over both the datasets. Among the classification models, lightweight models namely CCT, CNN, INN, Swin Transformer, and ConvMixer were emphasized due to their low computational requirements and faster prediction times. The lightweight models performed respectfully, oftentimes equating to the performance of heavyweight models. In addition, augmentation was found to enhance the performance of all the tested models. The experimental results exhibit that, our dataset performs on par or outperforms the similar classification models utilized in the existing literature, reaching accuracy and f1-scores over 99%. The dataset also performed on par with the existing datasets for segmentation, achieving model Dice Similarity Coefficient up to 67.54% and IoU scores up to 59.39%.
Med-IC: Fusing a Single Layer Involution with Convolutions for Enhanced Medical Image Classification and Segmentation
Sep 27, 2024The majority of medical images, especially those that resemble cells, have similar characteristics. These images, which occur in a variety of shapes, often show abnormalities in the organ or cell region. The convolution operation possesses a restricted capability to extract visual patterns across several spatial regions of an image. The involution process, which is the inverse operation of convolution, complements this inherent lack of spatial information extraction present in convolutions. In this study, we investigate how applying a single layer of involution prior to a convolutional neural network (CNN) architecture can significantly improve classification and segmentation performance, with a comparatively negligible amount of weight parameters. The study additionally shows how excessive use of involution layers might result in inaccurate predictions in a particular type of medical image. According to our findings from experiments, the strategy of adding only a single involution layer before a CNN-based model outperforms most of the previous works.
Spatially Optimized Compact Deep Metric Learning Model for Similarity Search
Apr 09, 2024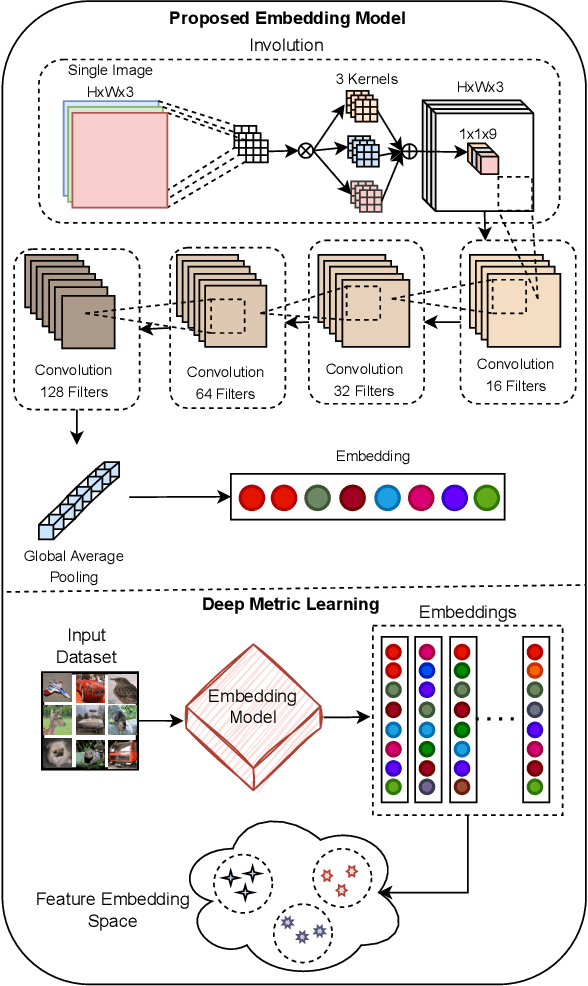
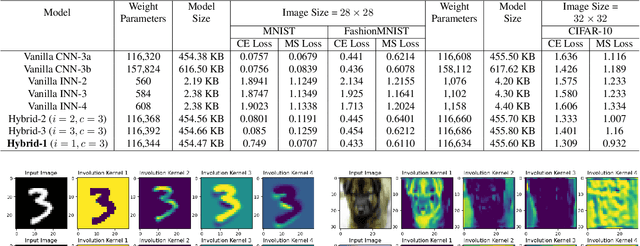

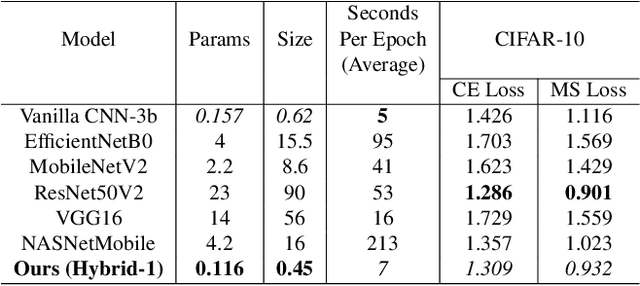
Spatial optimization is often overlooked in many computer vision tasks. Filters should be able to recognize the features of an object regardless of where it is in the image. Similarity search is a crucial task where spatial features decide an important output. The capacity of convolution to capture visual patterns across various locations is limited. In contrast to convolution, the involution kernel is dynamically created at each pixel based on the pixel value and parameters that have been learned. This study demonstrates that utilizing a single layer of involution feature extractor alongside a compact convolution model significantly enhances the performance of similarity search. Additionally, we improve predictions by using the GELU activation function rather than the ReLU. The negligible amount of weight parameters in involution with a compact model with better performance makes the model very useful in real-world implementations. Our proposed model is below 1 megabyte in size. We have experimented with our proposed methodology and other models on CIFAR-10, FashionMNIST, and MNIST datasets. Our proposed method outperforms across all three datasets.
Involution Fused ConvNet for Classifying Eye-Tracking Patterns of Children with Autism Spectrum Disorder
Jan 07, 2024Autism Spectrum Disorder (ASD) is a complicated neurological condition which is challenging to diagnose. Numerous studies demonstrate that children diagnosed with autism struggle with maintaining attention spans and have less focused vision. The eye-tracking technology has drawn special attention in the context of ASD since anomalies in gaze have long been acknowledged as a defining feature of autism in general. Deep Learning (DL) approaches coupled with eye-tracking sensors are exploiting additional capabilities to advance the diagnostic and its applications. By learning intricate nonlinear input-output relations, DL can accurately recognize the various gaze and eye-tracking patterns and adjust to the data. Convolutions alone are insufficient to capture the important spatial information in gaze patterns or eye tracking. The dynamic kernel-based process known as involutions can improve the efficiency of classifying gaze patterns or eye tracking data. In this paper, we utilise two different image-processing operations to see how these processes learn eye-tracking patterns. Since these patterns are primarily based on spatial information, we use involution with convolution making it a hybrid, which adds location-specific capability to a deep learning model. Our proposed model is implemented in a simple yet effective approach, which makes it easier for applying in real life. We investigate the reasons why our approach works well for classifying eye-tracking patterns. For comparative analysis, we experiment with two separate datasets as well as a combined version of both. The results show that IC with three involution layers outperforms the previous approaches.
Unmasking the Invisible: Finding Location-Specific Aggregated Air Quality Index with Smartphone-Captured Images
Aug 06, 2023The prevalence and mobility of smartphones make these a widely used tool for environmental health research. However, their potential for determining aggregated air quality index (AQI) based on PM2.5 concentration in specific locations remains largely unexplored in the existing literature. In this paper, we thoroughly examine the challenges associated with predicting location-specific PM2.5 concentration using images taken with smartphone cameras. The focus of our study is on Dhaka, the capital of Bangladesh, due to its significant air pollution levels and the large population exposed to it. Our research involves the development of a Deep Convolutional Neural Network (DCNN), which we train using over a thousand outdoor images taken and annotated. These photos are captured at various locations in Dhaka, and their labels are based on PM2.5 concentration data obtained from the local US consulate, calculated using the NowCast algorithm. Through supervised learning, our model establishes a correlation index during training, enhancing its ability to function as a Picture-based Predictor of PM2.5 Concentration (PPPC). This enables the algorithm to calculate an equivalent daily averaged AQI index from a smartphone image. Unlike, popular overly parameterized models, our model shows resource efficiency since it uses fewer parameters. Furthermore, test results indicate that our model outperforms popular models like ViT and INN, as well as popular CNN-based models such as VGG19, ResNet50, and MobileNetV2, in predicting location-specific PM2.5 concentration. Our dataset is the first publicly available collection that includes atmospheric images and corresponding PM2.5 measurements from Dhaka. Our code and dataset will be made public when publishing the paper.