 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Aware Unlearning via Activation Signatures: From Suppression to Knowledge-Signature Erasure
Jan 15, 2026Selective knowledge erasure from LLMs is critical for GDPR compliance and model safety, yet current unlearning methods conflate behavioral suppression with true knowledge removal, allowing latent capabilities to persist beneath surface-level refusals. In this work, we address this challenge by introducing Knowledge Immunization Framework (KIF), a representation-aware architecture that distinguishes genuine erasure from obfuscation by targeting internal activation signatures rather than surface outputs. Our approach combines dynamic suppression of subject-specific representations with parameter-efficient adaptation, enabling durable unlearning without full model retraining. KIF achieves near-oracle erasure (FQ approx 0.99 vs. 1.00) while preserving utility at oracle levels (MU = 0.62), effectively breaking the stability-erasure tradeoff that has constrained all prior work. We evaluate both standard foundation models (Llama and Mistral) and reasoning-prior models (Qwen and DeepSeek) across 3B to 14B parameters. Our observation shows that standard models exhibit scale-independent true erasure (<3% utility drift), while reasoning-prior models reveal fundamental architectural divergence. Our comprehensive dual-metric evaluation protocol, combining surface-level leakage with latent trace persistence, operationalizes the obfuscation - erasure distinction and enables the first systematic diagnosis of mechanism-level forgetting behavior across model families and scales.
A Comparative Analysis of Retrieval-Augmented Generation Techniques for Bengali Standard-to-Dialect Machine Translation Using LLMs
Dec 16, 2025Translating from a standard language to its regional dialects is a significant NLP challenge due to scarce data and linguistic variation, a problem prominent in the Bengali language. This paper proposes and compares two novel RAG pipelines for standard-to-dialectal Bengali translation. The first, a Transcript-Based Pipeline, uses large dialect sentence contexts from audio transcripts. The second, a more effective Standardized Sentence-Pairs Pipeline, utilizes structured local\_dialect:standard\_bengali sentence pairs. We evaluated both pipelines across six Bengali dialects and multiple LLMs using BLEU, ChrF, WER, and BERTScore. Our findings show that the sentence-pair pipeline consistently outperforms the transcript-based one, reducing Word Error Rate (WER) from 76\% to 55\% for the Chittagong dialect. Critically, this RAG approach enables smaller models (e.g., Llama-3.1-8B) to outperform much larger models (e.g., GPT-OSS-120B), demonstrating that a well-designed retrieval strategy can be more crucial than model size. This work contributes an effective, fine-tuning-free solution for low-resource dialect translation, offering a practical blueprint for preserving linguistic diversity.
Bridging Human and Model Perspectives: A Comparative Analysis of Political Bias Detection in News Media Using Large Language Models
Nov 18, 2025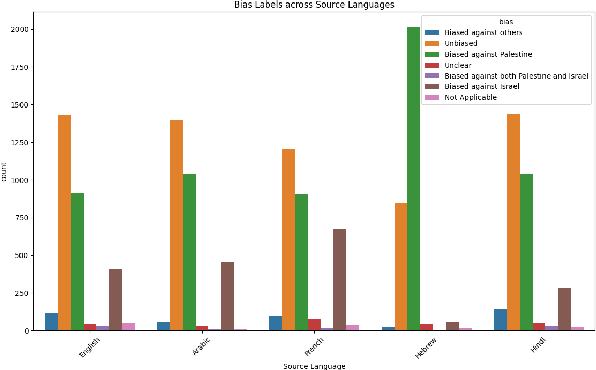



Detecting political bias in news media is a complex task that requires interpreting subtle linguistic and contextual cues. Although recent advances in Natural Language Processing (NLP) have enabled automatic bias classification, the extent to which large language models (LLMs) align with human judgment still remains relatively underexplored and not yet well understood. This study aims to present a comparative framework for evaluating the detection of political bias across human annotations and multiple LLMs, including GPT, BERT, RoBERTa, and FLAN. We construct a manually annotated dataset of news articles and assess annotation consistency, bias polarity, and inter-model agreement to quantify divergence between human and model perceptions of bias. Experimental results show that among traditional transformer-based models, RoBERTa achieves the highest alignment with human labels, whereas generative models such as GPT demonstrate the strongest overall agreement with human annotations in a zero-shot setting. Among all transformer-based baselines, our fine-tuned RoBERTa model acquired the highest accuracy and the strongest alignment with human-annotated labels. Our findings highlight systematic differences in how humans and LLMs perceive political slant, underscoring the need for hybrid evaluation frameworks that combine human interpretability with model scalability in automated media bias detection.
BNLI: A Linguistically-Refined Bengali Dataset for Natural Language Inference
Nov 11, 2025


Despite the growing progress in Natural Language Inference (NLI) research, resources for the Bengali language remain extremely limited. Existing Bengali NLI datasets exhibit several inconsistencies, including annotation errors, ambiguous sentence pairs, and inadequate linguistic diversity, which hinder effective model training and evaluation. To address these limitations, we introduce BNLI, a refined and linguistically curated Bengali NLI dataset designed to support robust language understanding and inference modeling. The dataset was constructed through a rigorous annotation pipeline emphasizing semantic clarity and balance across entailment, contradiction, and neutrality classes. We benchmarked BNLI using a suite of state-of-the-art transformer-based architectures, including multilingual and Bengali-specific models, to assess their ability to capture complex semantic relations in Bengali text. The experimental findings highlight the improved reliability and interpretability achieved with BNLI, establishing it as a strong foundation for advancing research in Bengali and other low-resource language inference tasks.
How Effectively Can BERT Models Interpret Context and Detect Bengali Communal Violent Text?
Jun 24, 2025


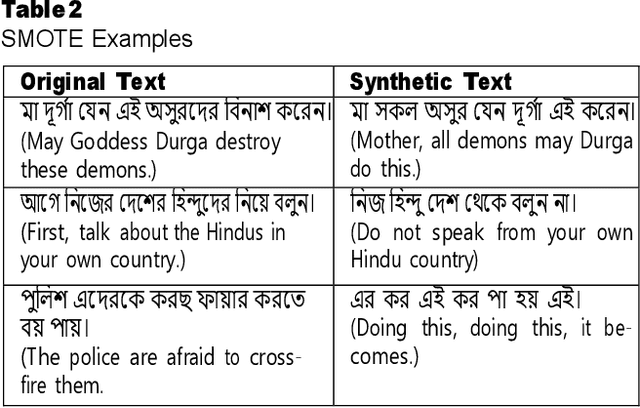
The spread of cyber hatred has led to communal violence, fueling aggression and conflicts between various religious, ethnic, and social groups, posing a significant threat to social harmony. Despite its critical importance, the classification of communal violent text remains an underexplored area in existing research. This study aims to enhance the accuracy of detecting text that incites communal violence, focusing specifically on Bengali textual data sourced from social media platforms. We introduce a fine-tuned BanglaBERT model tailored for this task, achieving a macro F1 score of 0.60. To address the issue of data imbalance, our dataset was expanded by adding 1,794 instances, which facilitated the development and evaluation of a fine-tuned ensemble model. This ensemble model demonstrated an improved performance, achieving a macro F1 score of 0.63, thus highlighting its effectiveness in this domain. In addition to quantitative performance metrics, qualitative analysis revealed instances where the models struggled with context understanding, leading to occasional misclassifications, even when predictions were made with high confidence. Through analyzing the cosine similarity between words, we identified certain limitations in the pre-trained BanglaBERT models, particularly in their ability to distinguish between closely related communal and non-communal terms. To further interpret the model's decisions, we applied LIME, which helped to uncover specific areas where the model struggled in understanding context, contributing to errors in classification. These findings highlight the promise of NLP and interpretability tools in reducing online communal violence. Our work contributes to the growing body of research in communal violence detection and offers a foundation for future studies aiming to refine these techniques for better accuracy and societal impact.
Med-IC: Fusing a Single Layer Involution with Convolutions for Enhanced Medical Image Classification and Segmentation
Sep 27, 2024The majority of medical images, especially those that resemble cells, have similar characteristics. These images, which occur in a variety of shapes, often show abnormalities in the organ or cell region. The convolution operation possesses a restricted capability to extract visual patterns across several spatial regions of an image. The involution process, which is the inverse operation of convolution, complements this inherent lack of spatial information extraction present in convolutions. In this study, we investigate how applying a single layer of involution prior to a convolutional neural network (CNN) architecture can significantly improve classification and segmentation performance, with a comparatively negligible amount of weight parameters. The study additionally shows how excessive use of involution layers might result in inaccurate predictions in a particular type of medical image. According to our findings from experiments, the strategy of adding only a single involution layer before a CNN-based model outperforms most of the previous works.
Mapping Violence: Developing an Extensive Framework to Build a Bangla Sectarian Expression Dataset from Social Media Interactions
Apr 17, 2024Communal violence in online forums has become extremely prevalent in South Asia, where many communities of different cultures coexist and share resources. These societies exhibit a phenomenon characterized by strong bonds within their own groups and animosity towards others, leading to conflicts that frequently escalate into violent confrontations. To address this issue, we have developed the first comprehensive framework for the automatic detection of communal violence markers in online Bangla content accompanying the largest collection (13K raw sentences) of social media interactions that fall under the definition of four major violence class and their 16 coarse expressions. Our workflow introduces a 7-step expert annotation process incorporating insights from social scientists, linguists, and psychologists. By presenting data statistics and benchmarking performance using this dataset, we have determined that, aside from the category of Non-communal violence, Religio-communal violence is particularly pervasive in Bangla text. Moreover, we have substantiated the effectiveness of fine-tuning language models in identifying violent comments by conducting preliminary benchmarking on the state-of-the-art Bangla deep learning model.
IPA Transcription of Bengali Texts
Mar 29, 2024The International Phonetic Alphabet (IPA) serves to systematize phonemes in language, enabling precise textual representation of pronunciation. In Bengali phonology and phonetics, ongoing scholarly deliberations persist concerning the IPA standard and core Bengali phonemes. This work examines prior research, identifies current and potential issues, and suggests a framework for a Bengali IPA standard, facilitating linguistic analysis and NLP resource creation and downstream technology development. In this work, we present a comprehensive study of Bengali IPA transcription and introduce a novel IPA transcription framework incorporating a novel dataset with DL-based benchmarks.
Gazetteer-Enhanced Bangla Named Entity Recognition with BanglaBERT Semantic Embeddings K-Means-Infused CRF Model
Jan 30, 2024Named Entity Recognition (NER) is a sub-task of Natural Language Processing (NLP) that distinguishes entities from unorganized text into predefined categorization. In recent years, a lot of Bangla NLP subtasks have received quite a lot of attention; but Named Entity Recognition in Bangla still lags behind. In this research, we explored the existing state of research in Bangla Named Entity Recognition. We tried to figure out the limitations that current techniques and datasets face, and we would like to address these limitations in our research. Additionally, We developed a Gazetteer that has the ability to significantly boost the performance of NER. We also proposed a new NER solution by taking advantage of state-of-the-art NLP tools that outperform conventional techniques.
Involution Fused ConvNet for Classifying Eye-Tracking Patterns of Children with Autism Spectrum Disorder
Jan 07, 2024Autism Spectrum Disorder (ASD) is a complicated neurological condition which is challenging to diagnose. Numerous studies demonstrate that children diagnosed with autism struggle with maintaining attention spans and have less focused vision. The eye-tracking technology has drawn special attention in the context of ASD since anomalies in gaze have long been acknowledged as a defining feature of autism in general. Deep Learning (DL) approaches coupled with eye-tracking sensors are exploiting additional capabilities to advance the diagnostic and its applications. By learning intricate nonlinear input-output relations, DL can accurately recognize the various gaze and eye-tracking patterns and adjust to the data. Convolutions alone are insufficient to capture the important spatial information in gaze patterns or eye tracking. The dynamic kernel-based process known as involutions can improve the efficiency of classifying gaze patterns or eye tracking data. In this paper, we utilise two different image-processing operations to see how these processes learn eye-tracking patterns. Since these patterns are primarily based on spatial information, we use involution with convolution making it a hybrid, which adds location-specific capability to a deep learning model. Our proposed model is implemented in a simple yet effective approach, which makes it easier for applying in real life. We investigate the reasons why our approach works well for classifying eye-tracking patterns. For comparative analysis, we experiment with two separate datasets as well as a combined version of both. The results show that IC with three involution layers outperforms the previous approaches.