 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Multi-Modal Embedded Vision Framework for Object Detection Facial Emotion Recognition and Biometric Identification on Low-Power Edge Platforms
Jan 17, 2026Intelligent surveillance systems often handle perceptual tasks such as object detection, facial recognition, and emotion analysis independently, but they lack a unified, adaptive runtime scheduler that dynamically allocates computational resources based on contextual triggers. This limits their holistic understanding and efficiency on low-power edge devices. To address this, we present a real-time multi-modal vision framework that integrates object detection, owner-specific face recognition, and emotion detection into a unified pipeline deployed on a Raspberry Pi 5 edge platform. The core of our system is an adaptive scheduling mechanism that reduces computational load by 65\% compared to continuous processing by selectively activating modules such as, YOLOv8n for object detection, a custom FaceNet-based embedding system for facial recognition, and DeepFace's CNN for emotion classification. Experimental results demonstrate the system's efficacy, with the object detection module achieving an Average Precision (AP) of 0.861, facial recognition attaining 88\% accuracy, and emotion detection showing strong discriminatory power (AUC up to 0.97 for specific emotions), while operating at 5.6 frames per second. Our work demonstrates that context-aware scheduling is the key to unlocking complex multi-modal AI on cost-effective edge hardware, making intelligent perception more accessible and privacy-preserving.
BaDLAD: A Large Multi-Domain Bengali Document Layout Analysis Dataset
Mar 10, 2023
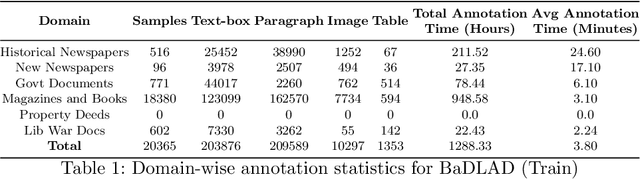
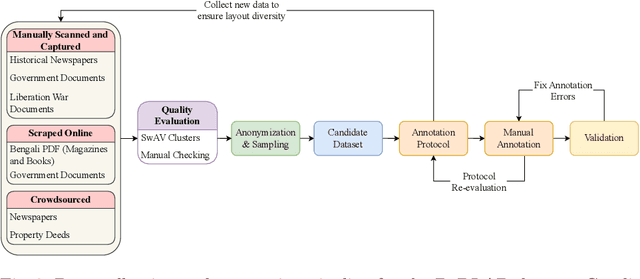
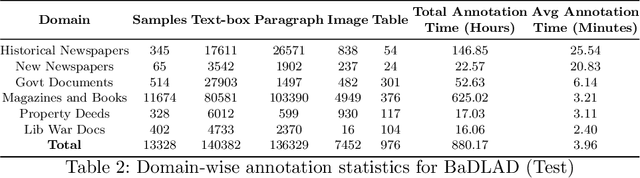
While strides have been made in deep learning based Bengali Optical Character Recognition (OCR) in the past decade, the absence of large Document Layout Analysis (DLA) datasets has hindered the application of OCR in document transcription, e.g., transcribing historical documents and newspapers. Moreover, rule-based DLA systems that are currently being employed in practice are not robust to domain variations and out-of-distribution layouts. To this end, we present the first multidomain large Bengali Document Layout Analysis Dataset: BaDLAD. This dataset contains 33,695 human annotated document samples from six domains - i) books and magazines, ii) public domain govt. documents, iii) liberation war documents, iv) newspapers, v) historical newspapers, and vi) property deeds, with 710K polygon annotations for four unit types: text-box, paragraph, image, and table. Through preliminary experiments benchmarking the performance of existing state-of-the-art deep learning architectures for English DLA, we demonstrate the efficacy of our dataset in training deep learning based Bengali document digitization models.