 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaDLAD: A Large Multi-Domain Bengali Document Layout Analysis Dataset
Paper and Code

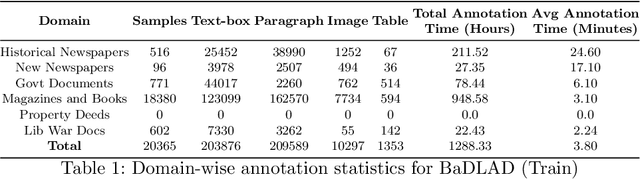
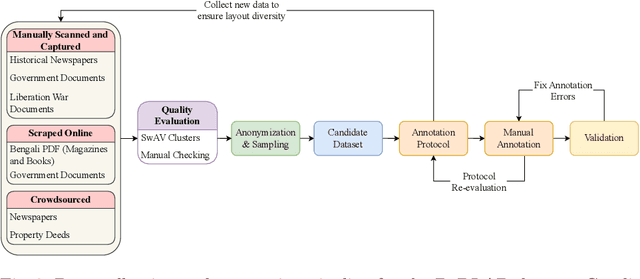
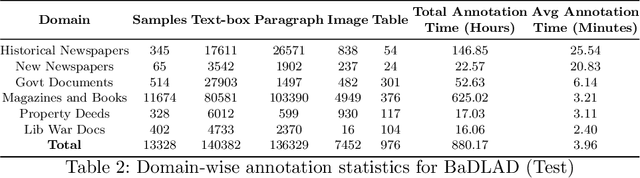
While strides have been made in deep learning based Bengali Optical Character Recognition (OCR) in the past decade, the absence of large Document Layout Analysis (DLA) datasets has hindered the application of OCR in document transcription, e.g., transcribing historical documents and newspapers. Moreover, rule-based DLA systems that are currently being employed in practice are not robust to domain variations and out-of-distribution layouts. To this end, we present the first multidomain large Bengali Document Layout Analysis Dataset: BaDLAD. This dataset contains 33,695 human annotated document samples from six domains - i) books and magazines, ii) public domain govt. documents, iii) liberation war documents, iv) newspapers, v) historical newspapers, and vi) property deeds, with 710K polygon annotations for four unit types: text-box, paragraph, image, and table. Through preliminary experiments benchmarking the performance of existing state-of-the-art deep learning architectures for English DLA, we demonstrate the efficacy of our dataset in training deep learning based Bengali document digitization models.