 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Violence: Developing an Extensive Framework to Build a Bangla Sectarian Expression Dataset from Social Media Interactions
Apr 17, 2024Communal violence in online forums has become extremely prevalent in South Asia, where many communities of different cultures coexist and share resources. These societies exhibit a phenomenon characterized by strong bonds within their own groups and animosity towards others, leading to conflicts that frequently escalate into violent confrontations. To address this issue, we have developed the first comprehensive framework for the automatic detection of communal violence markers in online Bangla content accompanying the largest collection (13K raw sentences) of social media interactions that fall under the definition of four major violence class and their 16 coarse expressions. Our workflow introduces a 7-step expert annotation process incorporating insights from social scientists, linguists, and psychologists. By presenting data statistics and benchmarking performance using this dataset, we have determined that, aside from the category of Non-communal violence, Religio-communal violence is particularly pervasive in Bangla text. Moreover, we have substantiated the effectiveness of fine-tuning language models in identifying violent comments by conducting preliminary benchmarking on the state-of-the-art Bangla deep learning model.
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking
May 15, 2023We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from $22,645$ native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.
BaDLAD: A Large Multi-Domain Bengali Document Layout Analysis Dataset
Mar 10, 2023
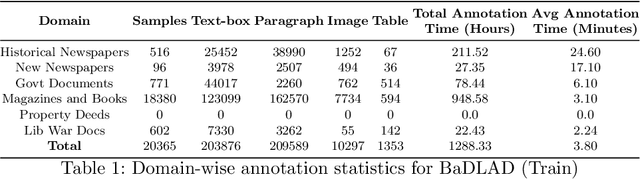
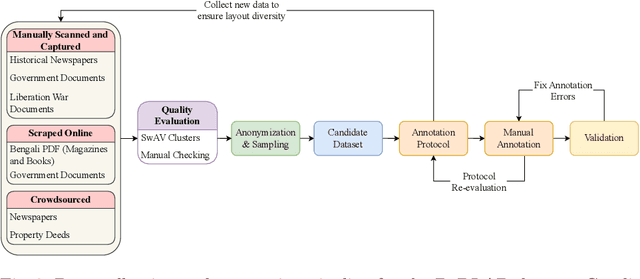
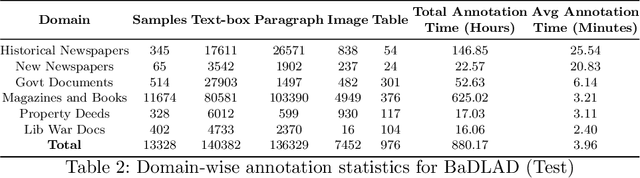
While strides have been made in deep learning based Bengali Optical Character Recognition (OCR) in the past decade, the absence of large Document Layout Analysis (DLA) datasets has hindered the application of OCR in document transcription, e.g., transcribing historical documents and newspapers. Moreover, rule-based DLA systems that are currently being employed in practice are not robust to domain variations and out-of-distribution layouts. To this end, we present the first multidomain large Bengali Document Layout Analysis Dataset: BaDLAD. This dataset contains 33,695 human annotated document samples from six domains - i) books and magazines, ii) public domain govt. documents, iii) liberation war documents, iv) newspapers, v) historical newspapers, and vi) property deeds, with 710K polygon annotations for four unit types: text-box, paragraph, image, and table. Through preliminary experiments benchmarking the performance of existing state-of-the-art deep learning architectures for English DLA, we demonstrate the efficacy of our dataset in training deep learning based Bengali document digitization models.
VISTA: Vision Transformer enhanced by U-Net and Image Colorfulness Frame Filtration for Automatic Retail Checkout
Apr 23, 2022


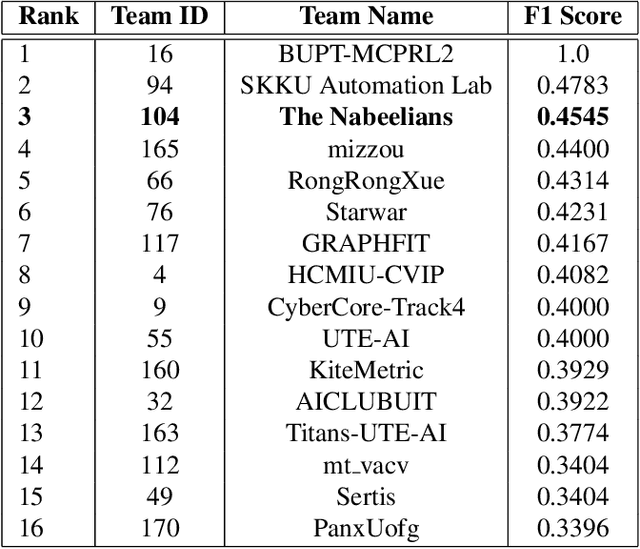
Multi-class product counting and recognition identifies product items from images or videos for automated retail checkout. The task is challenging due to the real-world scenario of occlusions where product items overlap, fast movement in the conveyor belt, large similarity in overall appearance of the items being scanned, novel products, and the negative impact of misidentifying items. Further, there is a domain bias between training and test sets, specifically, the provided training dataset consists of synthetic images and the test set videos consist of foreign objects such as hands and tray. To address these aforementioned issues, we propose to segment and classify individual frames from a video sequence. The segmentation method consists of a unified single product item- and hand-segmentation followed by entropy masking to address the domain bias problem. The multi-class classification method is based on Vision Transformers (ViT). To identify the frames with target objects, we utilize several image processing methods and propose a custom metric to discard frames not having any product items. Combining all these mechanisms, our best system achieves 3rd place in the AI City Challenge 2022 Track 4 with an F1 score of 0.4545. Code will be available at
TEAM-Atreides at SemEval-2022 Task 11: On leveraging data augmentation and ensemble to recognize complex Named Entities in Bangla
Apr 21, 2022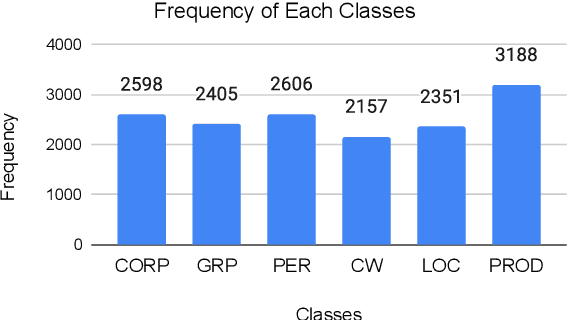

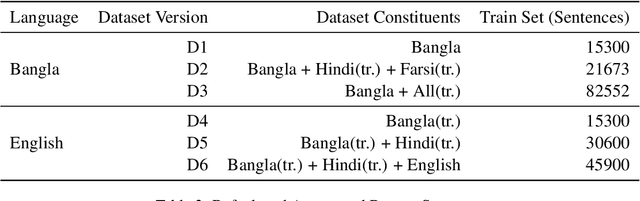
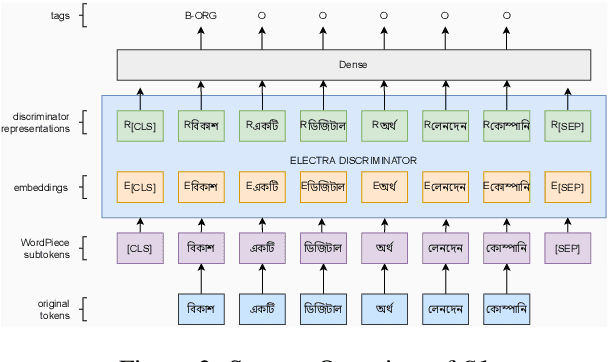
Many areas, such as the biological and healthcare domain, artistic works, and organization names, have nested, overlapping, discontinuous entity mentions that may even be syntactically or semantically ambiguous in practice. Traditional sequence tagging algorithms are unable to recognize these complex mentions because they may violate the assumptions upon which sequence tagging schemes are founded. In this paper, we describe our contribution to SemEval 2022 Task 11 on identifying such complex Named Entities. We have leveraged the ensemble of multiple ELECTRA-based models that were exclusively pretrained on the Bangla language with the performance of ELECTRA-based models pretrained on English to achieve competitive performance on the Track-11. Besides providing a system description, we will also present the outcomes of our experiments on architectural decisions, dataset augmentations, and post-competition findings.