 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEEKABOO: Hiding parts of an image for unsupervised object localization
Jul 24, 2024
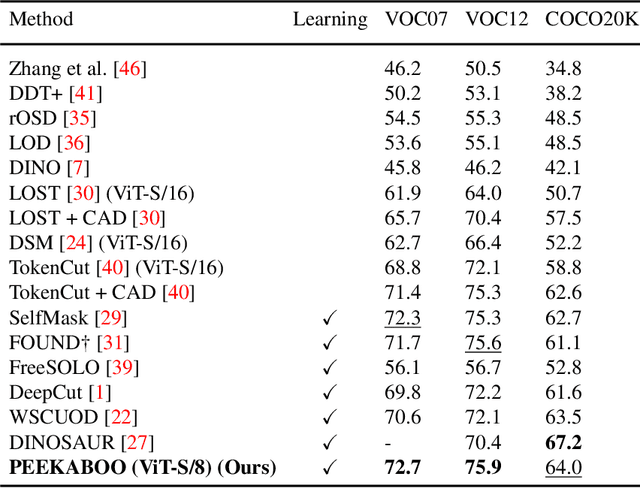
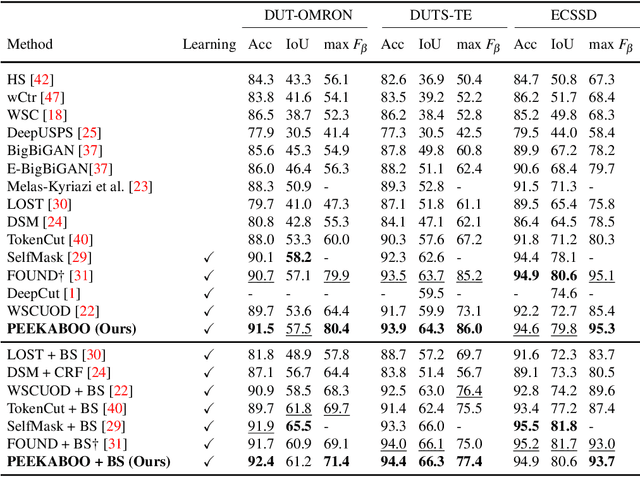

Localizing objects in an unsupervised manner poses significant challenges due to the absence of key visual information such as the appearance, type and number of objects, as well as the lack of labeled object classes typically available in supervised settings. While recent approaches to unsupervised object localization have demonstrated significant progress by leveraging self-supervised visual representations, they often require computationally intensive training processes, resulting in high resource demands in terms of computation, learnable parameters, and data. They also lack explicit modeling of visual context, potentially limiting their accuracy in object localization. To tackle these challenges, we propose a single-stage learning framework, dubbed PEEKABOO, for unsupervised object localization by learning context-based representations at both the pixel- and shape-level of the localized objects through image masking. The key idea is to selectively hide parts of an image and leverage the remaining image information to infer the location of objects without explicit supervision. The experimental results, both quantitative and qualitative, across various benchmark datasets, demonstrate the simplicity, effectiveness and competitive performance of our approach compared to state-of-the-art methods in both single object discovery and unsupervised salient object detection tasks. Code and pre-trained models are available at: https://github.com/hasibzunair/peekaboo
RSUD20K: A Dataset for Road Scene Understanding In Autonomous Driving
Jan 14, 2024



Road scene understanding is crucial in autonomous driving, enabling machines to perceive the visual environment. However, recent object detectors tailored for learning on datasets collected from certain geographical locations struggle to generalize across different locations. In this paper, we present RSUD20K, a new dataset for road scene understanding, comprised of over 20K high-resolution images from the driving perspective on Bangladesh roads, and includes 130K bounding box annotations for 13 objects. This challenging dataset encompasses diverse road scenes, narrow streets and highways, featuring objects from different viewpoints and scenes from crowded environments with densely cluttered objects and various weather conditions. Our work significantly improves upon previous efforts, providing detailed annotations and increased object complexity. We thoroughly examine the dataset, benchmarking various state-of-the-art object detectors and exploring large vision models as image annotators.
Learning to recognize occluded and small objects with partial inputs
Oct 27, 2023



Recognizing multiple objects in an image is challenging due to occlusions, and becomes even more so when the objects are small. While promising, existing multi-label image recognition models do not explicitly learn context-based representations, and hence struggle to correctly recognize small and occluded objects. Intuitively, recognizing occluded objects requires knowledge of partial input, and hence context. Motivated by this intuition, we propose Masked Supervised Learning (MSL), a single-stage, model-agnostic learning paradigm for multi-label image recognition. The key idea is to learn context-based representations using a masked branch and to model label co-occurrence using label consistency. Experimental results demonstrate the simplicity, applicability and more importantly the competitive performance of MSL against previous state-of-the-art methods on standard multi-label image recognition benchmarks. In addition, we show that MSL is robust to random masking and demonstrate its effectiveness in recognizing non-masked objects. Code and pretrained models are available on GitHub.
CosSIF: Cosine similarity-based image filtering to overcome low inter-class variation in synthetic medical image datasets
Jul 25, 2023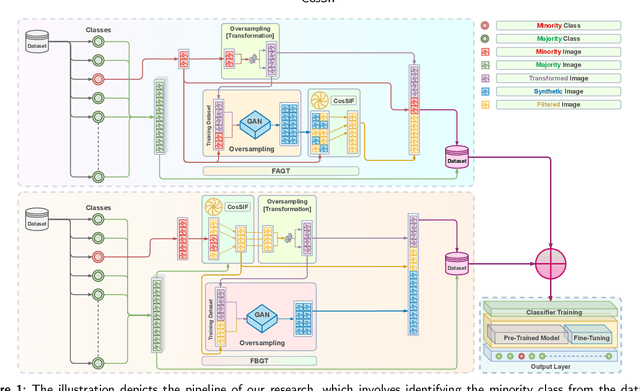

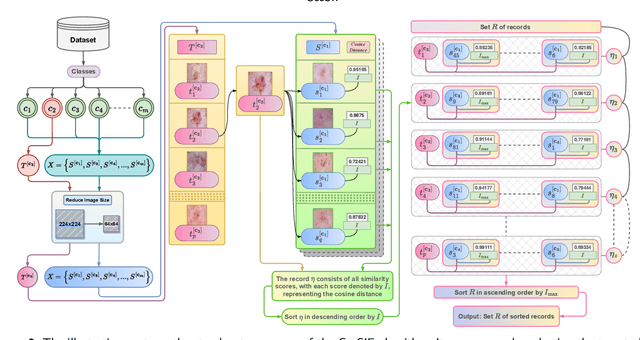

Crafting effective deep learning models for medical image analysis is a complex task, particularly in cases where the medical image dataset lacks significant inter-class variation. This challenge is further aggravated when employing such datasets to generate synthetic images using generative adversarial networks (GANs), as the output of GANs heavily relies on the input data. In this research, we propose a novel filtering algorithm called Cosine Similarity-based Image Filtering (CosSIF). We leverage CosSIF to develop two distinct filtering methods: Filtering Before GAN Training (FBGT) and Filtering After GAN Training (FAGT). FBGT involves the removal of real images that exhibit similarities to images of other classes before utilizing them as the training dataset for a GAN. On the other hand, FAGT focuses on eliminating synthetic images with less discriminative features compared to real images used for training the GAN. Experimental results reveal that employing either the FAGT or FBGT method with modern transformer and convolutional-based networks leads to substantial performance gains in various evaluation metrics. FAGT implementation on the ISIC-2016 dataset surpasses the baseline method in terms of sensitivity by 1.59\% and AUC by 1.88\%. Furthermore, for the HAM10000 dataset, applying FABT outperforms the baseline approach in terms of recall by 13.75\%, and with the sole implementation of FAGT, achieves a maximum accuracy of 94.44\%.
Knowledge Distillation approach towards Melanoma Detection
Oct 14, 2022
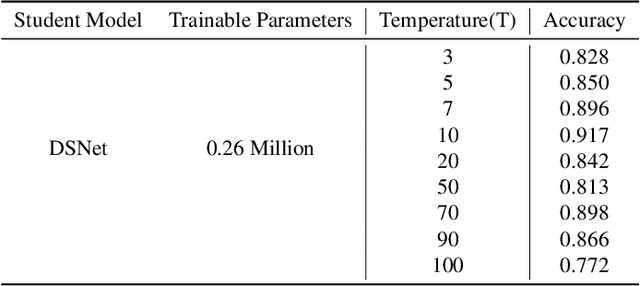

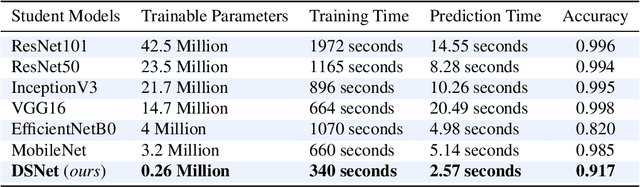
Melanoma is regarded as the most threatening among all skin cancers. There is a pressing need to build systems which can aid in the early detection of melanoma and enable timely treatment to patients. Recent methods are geared towards machine learning based systems where the task is posed as image recognition, tag dermoscopic images of skin lesions as melanoma or non-melanoma. Even though these methods show promising results in terms of accuracy, they are computationally quite expensive to train, that questions the ability of these models to be deployable in a clinical setting or memory constraint devices. To address this issue, we focus on building simple and performant models having few layers, less than ten compared to hundreds. As well as with fewer learnable parameters, 0.26 million (M) compared to 42.5M using knowledge distillation with the goal to detect melanoma from dermoscopic images. First, we train a teacher model using a ResNet-50 to detect melanoma. Using the teacher model, we train the student model known as Distilled Student Network (DSNet) which has around 0.26M parameters using knowledge distillation achieving an accuracy of 91.7%. We compare against ImageNet pre-trained models such MobileNet, VGG-16, Inception-V3, EfficientNet-B0, ResNet-50 and ResNet-101. We find that our approach works well in terms of inference runtime compared to other pre-trained models, 2.57 seconds compared to 14.55 seconds. We find that DSNet (0.26M parameters), which is 15 times smaller, consistently performs better than EfficientNet-B0 (4M parameters) in both melanoma and non-melanoma detection across Precision, Recall and F1 scores
VISTA: Vision Transformer enhanced by U-Net and Image Colorfulness Frame Filtration for Automatic Retail Checkout
Apr 23, 2022


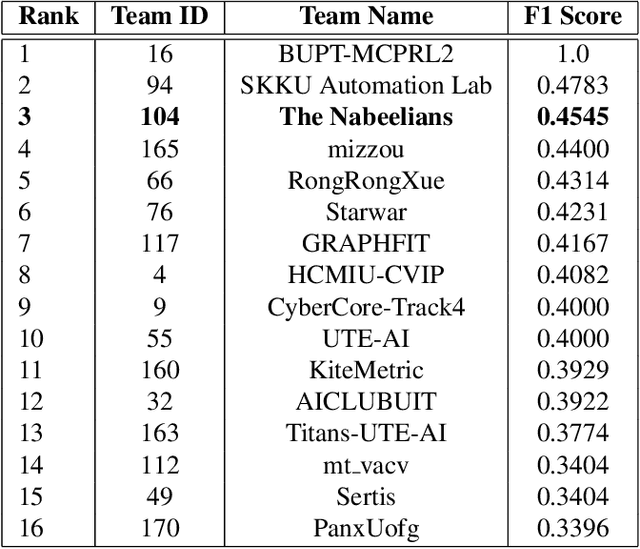
Multi-class product counting and recognition identifies product items from images or videos for automated retail checkout. The task is challenging due to the real-world scenario of occlusions where product items overlap, fast movement in the conveyor belt, large similarity in overall appearance of the items being scanned, novel products, and the negative impact of misidentifying items. Further, there is a domain bias between training and test sets, specifically, the provided training dataset consists of synthetic images and the test set videos consist of foreign objects such as hands and tray. To address these aforementioned issues, we propose to segment and classify individual frames from a video sequence. The segmentation method consists of a unified single product item- and hand-segmentation followed by entropy masking to address the domain bias problem. The multi-class classification method is based on Vision Transformers (ViT). To identify the frames with target objects, we utilize several image processing methods and propose a custom metric to discard frames not having any product items. Combining all these mechanisms, our best system achieves 3rd place in the AI City Challenge 2022 Track 4 with an F1 score of 0.4545. Code will be available at
STAR: Noisy Semi-Supervised Transfer Learning for Visual Classification
Aug 18, 2021
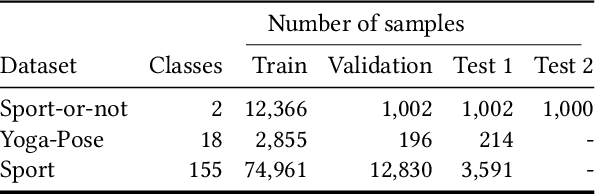

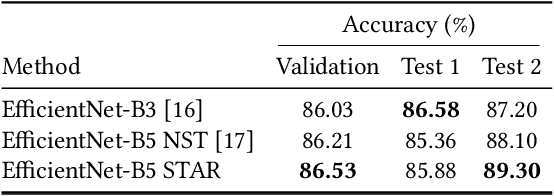
Semi-supervised learning (SSL) has proven to be effective at leveraging large-scale unlabeled data to mitigate the dependency on labeled data in order to learn better models for visual recognition and classification tasks. However, recent SSL methods rely on unlabeled image data at a scale of billions to work well. This becomes infeasible for tasks with relatively fewer unlabeled data in terms of runtime, memory and data acquisition. To address this issue, we propose noisy semi-supervised transfer learning, an efficient SSL approach that integrates transfer learning and self-training with noisy student into a single framework, which is tailored for tasks that can leverage unlabeled image data on a scale of thousands. We evaluate our method on both binary and multi-class classification tasks, where the objective is to identify whether an image displays people practicing sports or the type of sport, as well as to identify the pose from a pool of popular yoga poses. Extensive experiments and ablation studies demonstrate that by leveraging unlabeled data, our proposed framework significantly improves visual classification, especially in multi-class classification settings compared to state-of-the-art methods. Moreover, incorporating transfer learning not only improves classification performance, but also requires 6x less compute time and 5x less memory. We also show that our method boosts robustness of visual classification models, even without specifically optimizing for adversarial robustness.
Sharp U-Net: Depthwise Convolutional Network for Biomedical Image Segmentation
Jul 26, 2021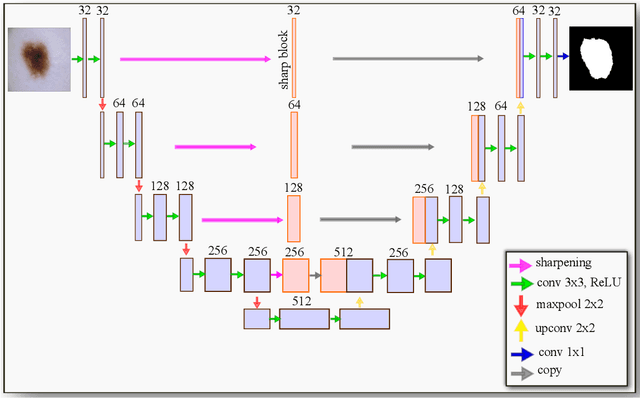
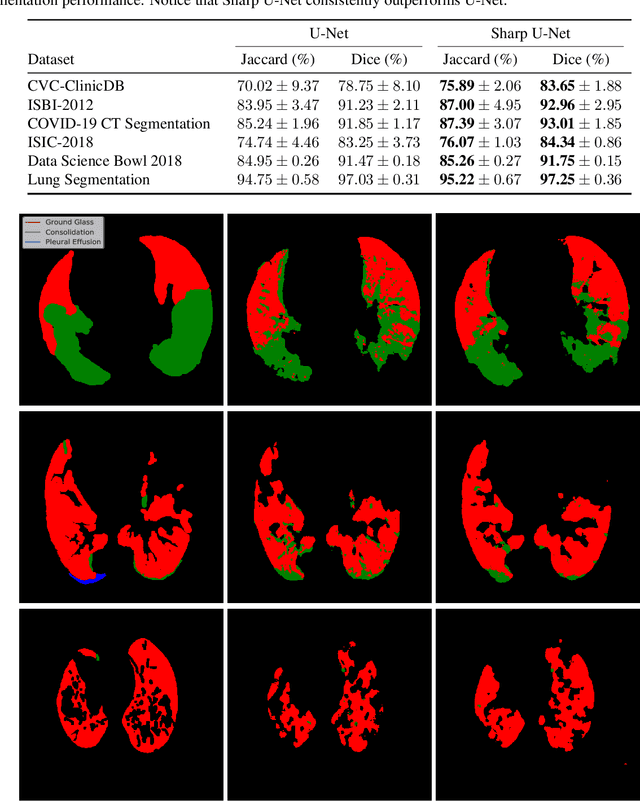
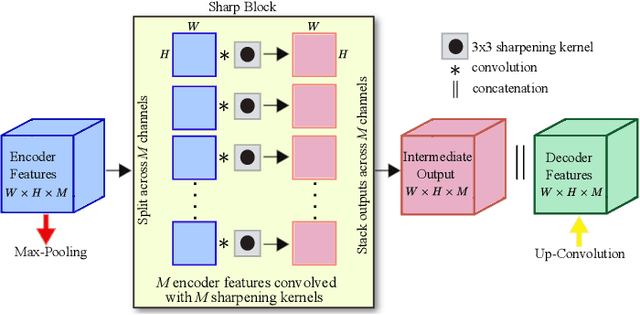

The U-Net architecture, built upon the fully convolutional network, has proven to be effective in biomedical image segmentation. However, U-Net applies skip connections to merge semantically different low- and high-level convolutional features, resulting in not only blurred feature maps, but also over- and under-segmented target regions. To address these limitations, we propose a simple, yet effective end-to-end depthwise encoder-decoder fully convolutional network architecture, called Sharp U-Net, for binary and multi-class biomedical image segmentation. The key rationale of Sharp U-Net is that instead of applying a plain skip connection, a depthwise convolution of the encoder feature map with a sharpening kernel filter is employed prior to merging the encoder and decoder features, thereby producing a sharpened intermediate feature map of the same size as the encoder map. Using this sharpening filter layer, we are able to not only fuse semantically less dissimilar features, but also to smooth out artifacts throughout the network layers during the early stages of training. Our extensive experiments on six datasets show that the proposed Sharp U-Net model consistently outperforms or matches the recent state-of-the-art baselines in both binary and multi-class segmentation tasks, while adding no extra learnable parameters. Furthermore, Sharp U-Net outperforms baselines that have more than three times the number of learnable parameters.
Synthetic COVID-19 Chest X-ray Dataset for Computer-Aided Diagnosis
Jun 17, 2021


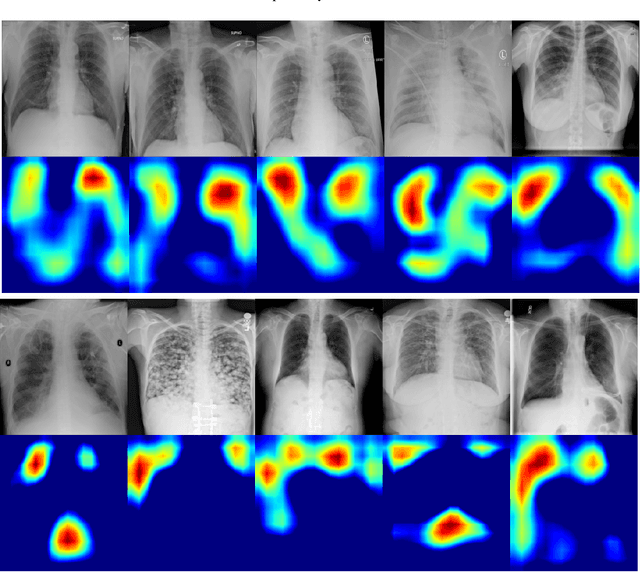
We introduce a new dataset called Synthetic COVID-19 Chest X-ray Dataset for training machine learning models. The dataset consists of 21,295 synthetic COVID-19 chest X-ray images to be used for computer-aided diagnosis. These images, generated via an unsupervised domain adaptation approach, are of high quality. We find that the synthetic images not only improve performance of various deep learning architectures when used as additional training data under heavy imbalance conditions, but also detect the target class with high confidence. We also find that comparable performance can also be achieved when trained only on synthetic images. Further, salient features of the synthetic COVID-19 images indicate that the distribution is significantly different from Non-COVID-19 classes, enabling a proper decision boundary. We hope the availability of such high fidelity chest X-ray images of COVID-19 will encourage advances in the development of diagnostic and/or management tools.
ViPTT-Net: Video pretraining of spatio-temporal model for tuberculosis type classification from chest CT scans
May 26, 2021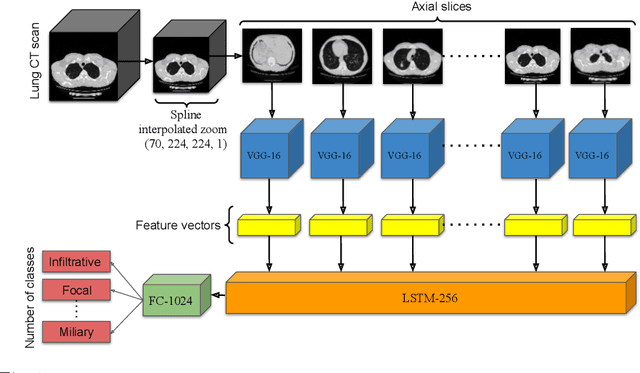
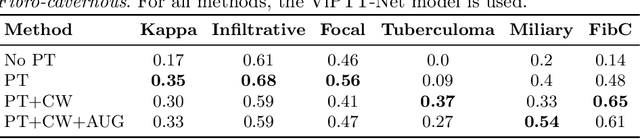
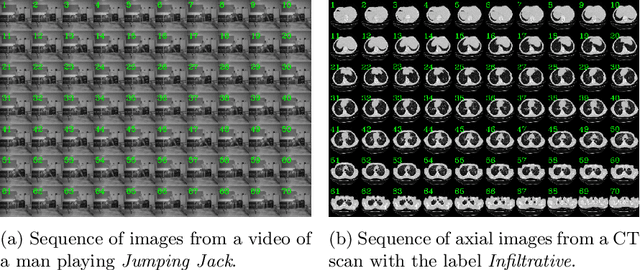

Pretraining has sparked groundswell of interest in deep learning workflows to learn from limited data and improve generalization. While this is common for 2D image classification tasks, its application to 3D medical imaging tasks like chest CT interpretation is limited. We explore the idea of whether pretraining a model on realistic videos could improve performance rather than training the model from scratch, intended for tuberculosis type classification from chest CT scans. To incorporate both spatial and temporal features, we develop a hybrid convolutional neural network (CNN) and recurrent neural network (RNN) model, where the features are extracted from each axial slice of the CT scan by a CNN, these sequence of image features are input to a RNN for classification of the CT scan. Our model termed as ViPTT-Net, was trained on over 1300 video clips with labels of human activities, and then fine-tuned on chest CT scans with labels of tuberculosis type. We find that pretraining the model on videos lead to better representations and significantly improved model validation performance from a kappa score of 0.17 to 0.35, especially for under-represented class samples. Our best method achieved 2nd place in the ImageCLEF 2021 Tuberculosis - TBT classification task with a kappa score of 0.20 on the final test set with only image information (without using clinical meta-data). All codes and models are made available.