 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVi: Training-free Text-conditioned Multi-Object Video Generation
May 29, 2025Recent advances in diffusion-based text-to-video (T2V) models have demonstrated remarkable progress, but these models still face challenges in generating videos with multiple objects. Most models struggle with accurately capturing complex object interactions, often treating some objects as static background elements and limiting their movement. In addition, they often fail to generate multiple distinct objects as specified in the prompt, resulting in incorrect generations or mixed features across objects. In this paper, we present a novel training-free approach for multi-object video generation that leverages the open world knowledge of diffusion models and large language models (LLMs). We use an LLM as the ``director'' of object trajectories, and apply the trajectories through noise re-initialization to achieve precise control of realistic movements. We further refine the generation process by manipulating the attention mechanism to better capture object-specific features and motion patterns, and prevent cross-object feature interference. Extensive experiments validate the effectiveness of our training free approach in significantly enhancing the multi-object generation capabilities of existing video diffusion models, resulting in 42% absolute improvement in motion dynamics and object generation accuracy, while also maintaining high fidelity and motion smoothness.
Training Free Stylized Abstraction
May 28, 2025Stylized abstraction synthesizes visually exaggerated yet semantically faithful representations of subjects, balancing recognizability with perceptual distortion. Unlike image-to-image translation, which prioritizes structural fidelity, stylized abstraction demands selective retention of identity cues while embracing stylistic divergence, especially challenging for out-of-distribution individuals. We propose a training-free framework that generates stylized abstractions from a single image using inference-time scaling in vision-language models (VLLMs) to extract identity-relevant features, and a novel cross-domain rectified flow inversion strategy that reconstructs structure based on style-dependent priors. Our method adapts structural restoration dynamically through style-aware temporal scheduling, enabling high-fidelity reconstructions that honor both subject and style. It supports multi-round abstraction-aware generation without fine-tuning. To evaluate this task, we introduce StyleBench, a GPT-based human-aligned metric suited for abstract styles where pixel-level similarity fails. Experiments across diverse abstraction (e.g., LEGO, knitted dolls, South Park) show strong generalization to unseen identities and styles in a fully open-source setup.
Frame by Familiar Frame: Understanding Replication in Video Diffusion Models
Mar 28, 2024Building on the momentum of image generation diffusion models, there is an increasing interest in video-based diffusion models. However, video generation poses greater challenges due to its higher-dimensional nature, the scarcity of training data, and the complex spatiotemporal relationships involved. Image generation models, due to their extensive data requirements, have already strained computational resources to their limits. There have been instances of these models reproducing elements from the training samples, leading to concerns and even legal disputes over sample replication. Video diffusion models, which operate with even more constrained datasets and are tasked with generating both spatial and temporal content, may be more prone to replicating samples from their training sets. Compounding the issue, these models are often evaluated using metrics that inadvertently reward replication. In our paper, we present a systematic investigation into the phenomenon of sample replication in video diffusion models. We scrutinize various recent diffusion models for video synthesis, assessing their tendency to replicate spatial and temporal content in both unconditional and conditional generation scenarios. Our study identifies strategies that are less likely to lead to replication. Furthermore, we propose new evaluation strategies that take replication into account, offering a more accurate measure of a model's ability to generate the original content.
Ambiguous Medical Image Segmentation using Diffusion Models
Apr 10, 2023



Collective insights from a group of experts have always proven to outperform an individual's best diagnostic for clinical tasks. For the task of medical image segmentation, existing research on AI-based alternatives focuses more on developing models that can imitate the best individual rather than harnessing the power of expert groups. In this paper, we introduce a single diffusion model-based approach that produces multiple plausible outputs by learning a distribution over group insights. Our proposed model generates a distribution of segmentation masks by leveraging the inherent stochastic sampling process of diffusion using only minimal additional learning. We demonstrate on three different medical image modalities- CT, ultrasound, and MRI that our model is capable of producing several possible variants while capturing the frequencies of their occurrences. Comprehensive results show that our proposed approach outperforms existing state-of-the-art ambiguous segmentation networks in terms of accuracy while preserving naturally occurring variation. We also propose a new metric to evaluate the diversity as well as the accuracy of segmentation predictions that aligns with the interest of clinical practice of collective insights.
Orientation-guided Graph Convolutional Network for Bone Surface Segmentation
Jun 16, 2022
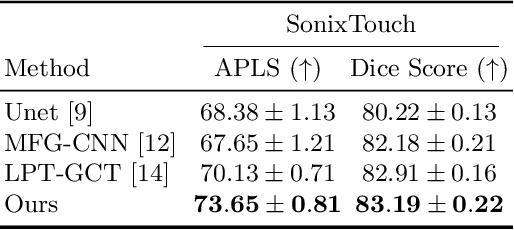
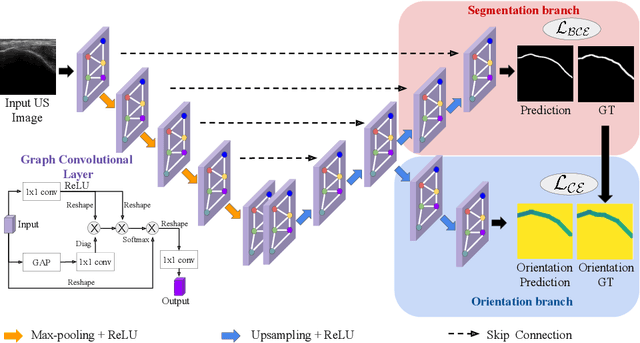
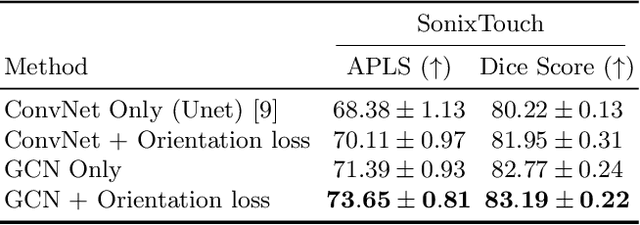
Due to imaging artifacts and low signal-to-noise ratio in ultrasound images, automatic bone surface segmentation networks often produce fragmented predictions that can hinder the success of ultrasound-guided computer-assisted surgical procedures. Existing pixel-wise predictions often fail to capture the accurate topology of bone tissues due to a lack of supervision to enforce connectivity. In this work, we propose an orientation-guided graph convolutional network to improve connectivity while segmenting the bone surface. We also propose an additional supervision on the orientation of the bone surface to further impose connectivity. We validated our approach on 1042 vivo US scans of femur, knee, spine, and distal radius. Our approach improves over the state-of-the-art methods by 5.01% in connectivity metric.
Simultaneous Bone and Shadow Segmentation Network using Task Correspondence Consistency
Jun 16, 2022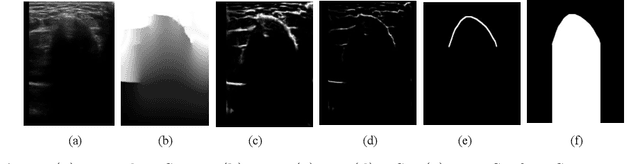
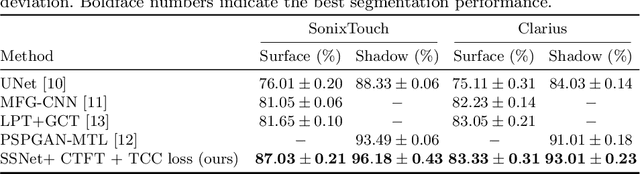
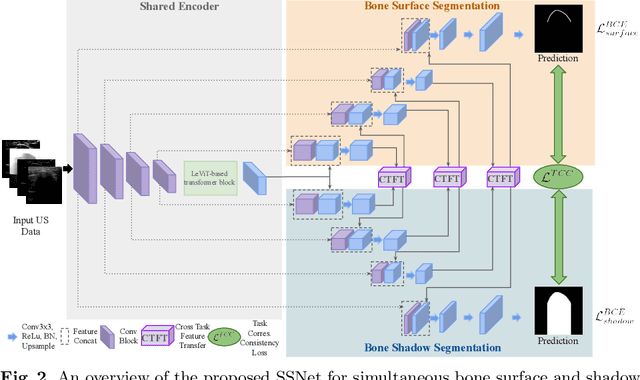

Segmenting both bone surface and the corresponding acoustic shadow are fundamental tasks in ultrasound (US) guided orthopedic procedures. However, these tasks are challenging due to minimal and blurred bone surface response in US images, cross-machine discrepancy, imaging artifacts, and low signal-to-noise ratio. Notably, bone shadows are caused by a significant acoustic impedance mismatch between the soft tissue and bone surfaces. To leverage this mutual information between these highly related tasks, we propose a single end-to-end network with a shared transformer-based encoder and task independent decoders for simultaneous bone and shadow segmentation. To share complementary features, we propose a cross task feature transfer block which learns to transfer meaningful features from decoder of shadow segmentation to that of bone segmentation and vice-versa. We also introduce a correspondence consistency loss which makes sure that network utilizes the inter-dependency between the bone surface and its corresponding shadow to refine the segmentation. Validation against expert annotations shows that the method outperforms the previous state-of-the-art for both bone surface and shadow segmentation.
ViPTT-Net: Video pretraining of spatio-temporal model for tuberculosis type classification from chest CT scans
May 26, 2021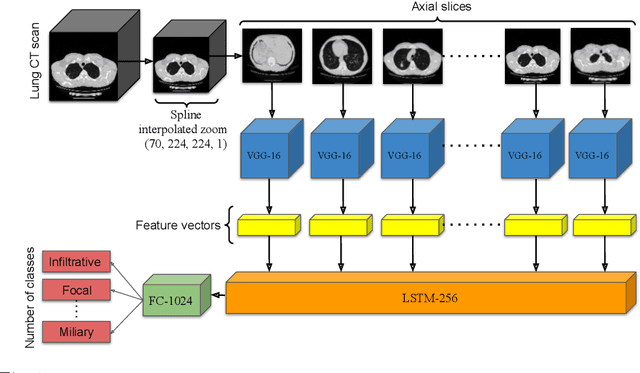
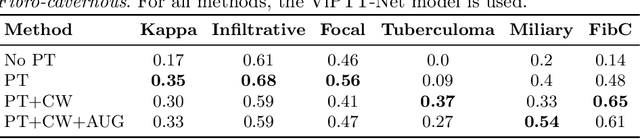
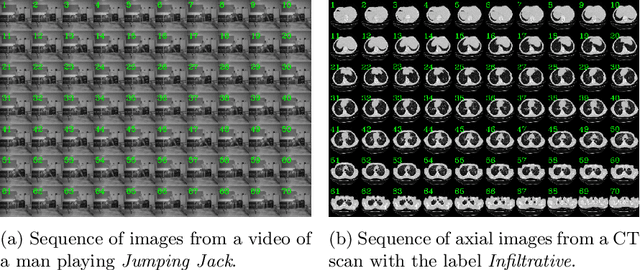

Pretraining has sparked groundswell of interest in deep learning workflows to learn from limited data and improve generalization. While this is common for 2D image classification tasks, its application to 3D medical imaging tasks like chest CT interpretation is limited. We explore the idea of whether pretraining a model on realistic videos could improve performance rather than training the model from scratch, intended for tuberculosis type classification from chest CT scans. To incorporate both spatial and temporal features, we develop a hybrid convolutional neural network (CNN) and recurrent neural network (RNN) model, where the features are extracted from each axial slice of the CT scan by a CNN, these sequence of image features are input to a RNN for classification of the CT scan. Our model termed as ViPTT-Net, was trained on over 1300 video clips with labels of human activities, and then fine-tuned on chest CT scans with labels of tuberculosis type. We find that pretraining the model on videos lead to better representations and significantly improved model validation performance from a kappa score of 0.17 to 0.35, especially for under-represented class samples. Our best method achieved 2nd place in the ImageCLEF 2021 Tuberculosis - TBT classification task with a kappa score of 0.20 on the final test set with only image information (without using clinical meta-data). All codes and models are made available.
Uniformizing Techniques to Process CT scans with 3D CNNs for Tuberculosis Prediction
Jul 26, 2020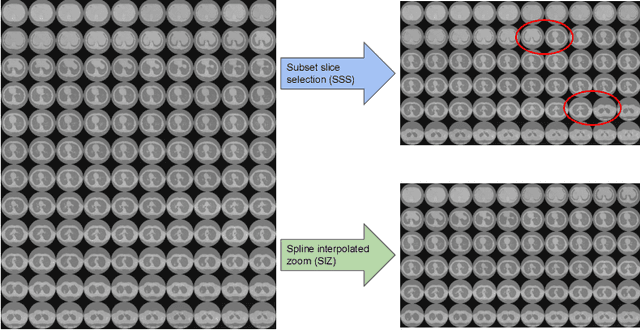



A common approach to medical image analysis on volumetric data uses deep 2D convolutional neural networks (CNNs). This is largely attributed to the challenges imposed by the nature of the 3D data: variable volume size, GPU exhaustion during optimization. However, dealing with the individual slices independently in 2D CNNs deliberately discards the depth information which results in poor performance for the intended task. Therefore, it is important to develop methods that not only overcome the heavy memory and computation requirements but also leverage the 3D information. To this end, we evaluate a set of volume uniformizing methods to address the aforementioned issues. The first method involves sampling information evenly from a subset of the volume. Another method exploits the full geometry of the 3D volume by interpolating over the z-axis. We demonstrate performance improvements using controlled ablation studies as well as put this approach to the test on the ImageCLEF Tuberculosis Severity Assessment 2019 benchmark. We report 73% area under curve (AUC) and binary classification accuracy (ACC) of 67.5% on the test set beating all methods which leveraged only image information (without using clinical meta-data) achieving 5-th position overall. All codes and models are made available at https://github.com/hasibzunair/uniformizing-3D.
Improving Malaria Parasite Detection from Red Blood Cell using Deep Convolutional Neural Networks
Jul 23, 2019
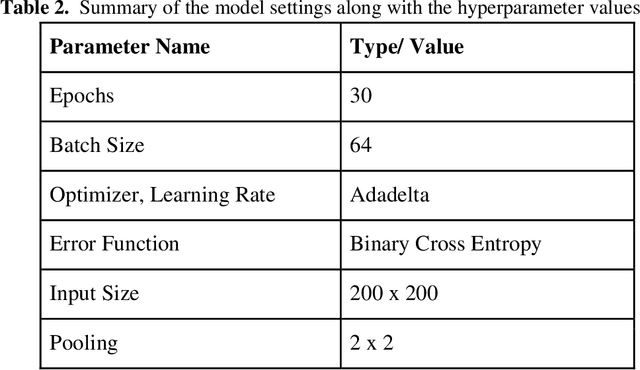
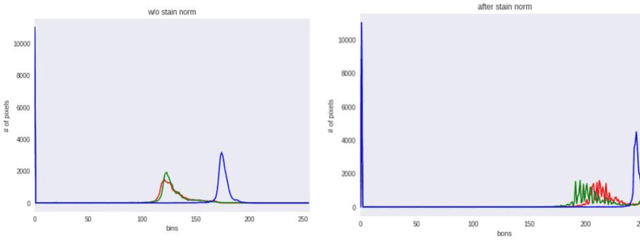
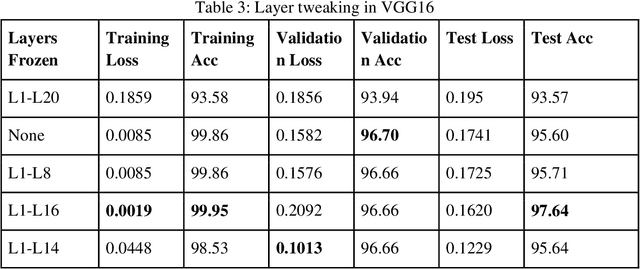
Malaria is a female anopheles mosquito-bite inflicted life-threatening disease which is considered endemic in many parts of the world. This article focuses on improving malaria detection from patches segmented from microscopic images of red blood cell smears by introducing a deep convolutional neural network. Compared to the traditional methods that use tedious hand engineering feature extraction, the proposed method uses deep learning in an end-to-end arrangement that performs both feature extraction and classification directly from the raw segmented patches of the red blood smears. The dataset used in this study was taken from National Institute of Health named NIH Malaria Dataset. The evaluation metric accuracy and loss along with 5-fold cross validation was used to compare and select the best performing architecture. To maximize the performance, existing standard pre-processing techniques from the literature has also been experimented. In addition, several other complex architectures have been implemented and tested to pick the best performing model. A holdout test has also been conducted to verify how well the proposed model generalizes on unseen data. Our best model achieves an accuracy of almost 97.77%.