 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining 3D Computed Tomography Classifiers with Counterfactuals
Feb 11, 2025


Counterfactual explanations in medical imaging are critical for understanding the predictions made by deep learning models. We extend the Latent Shift counterfactual generation method from 2D applications to 3D computed tomography (CT) scans. We address the challenges associated with 3D data, such as limited training samples and high memory demands, by implementing a slice-based approach. This method leverages a 2D encoder trained on CT slices, which are subsequently combined to maintain 3D context. We demonstrate this technique on two models for clinical phenotype prediction and lung segmentation. Our approach is both memory-efficient and effective for generating interpretable counterfactuals in high-resolution 3D medical imaging.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Jan 22, 2024



Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
Identifying Spurious Correlations using Counterfactual Alignment
Dec 01, 2023



Models driven by spurious correlations often yield poor generalization performance. We propose the counterfactual alignment method to detect and explore spurious correlations of black box classifiers. Counterfactual images generated with respect to one classifier can be input into other classifiers to see if they also induce changes in the outputs of these classifiers. The relationship between these responses can be quantified and used to identify specific instances where a spurious correlation exists as well as compute aggregate statistics over a dataset. Our work demonstrates the ability to detect spurious correlations in face attribute classifiers. This is validated by observing intuitive trends in a face attribute classifier as well as fabricating spurious correlations and detecting their presence, both visually and quantitatively. Further, utilizing the CF alignment method, we demonstrate that we can rectify spurious correlations identified in classifiers.
The Effect of Counterfactuals on Reading Chest X-rays
Apr 02, 2023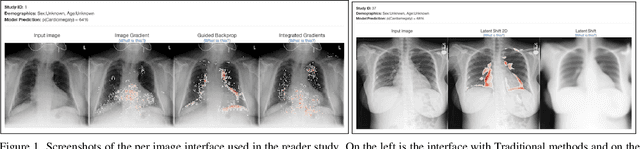
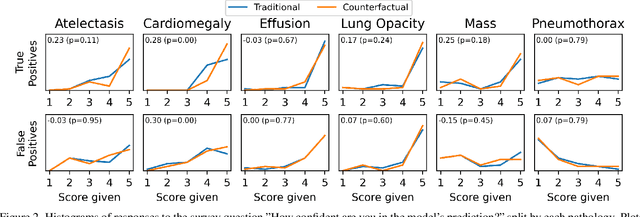
This study evaluates the effect of counterfactual explanations on the interpretation of chest X-rays. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to rate their confidence that the model's prediction is correct using a 5 point scale. Half of the predictions are false positives. Each prediction is explained twice, once using traditional attribution methods and once with a counterfactual explanation. The overall results indicate that counterfactual explanations allow a radiologist to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). We observe the specific prediction tasks of Mass and Atelectasis appear to benefit the most compared to other tasks.
Medical Image Segmentation Review: The success of U-Net
Nov 27, 2022



Automatic medical image segmentation is a crucial topic in the medical domain and successively a critical counterpart in the computer-aided diagnosis paradigm. U-Net is the most widespread image segmentation architecture due to its flexibility, optimized modular design, and success in all medical image modalities. Over the years, the U-Net model achieved tremendous attention from academic and industrial researchers. Several extensions of this network have been proposed to address the scale and complexity created by medical tasks. Addressing the deficiency of the naive U-Net model is the foremost step for vendors to utilize the proper U-Net variant model for their business. Having a compendium of different variants in one place makes it easier for builders to identify the relevant research. Also, for ML researchers it will help them understand the challenges of the biological tasks that challenge the model. To address this, we discuss the practical aspects of the U-Net model and suggest a taxonomy to categorize each network variant. Moreover, to measure the performance of these strategies in a clinical application, we propose fair evaluations of some unique and famous designs on well-known datasets. We provide a comprehensive implementation library with trained models for future research. In addition, for ease of future studies, we created an online list of U-Net papers with their possible official implementation. All information is gathered in https://github.com/NITR098/Awesome-U-Net repository.
Multi-Domain Balanced Sampling Improves Out-of-Distribution Generalization of Chest X-ray Pathology Prediction Models
Dec 28, 2021
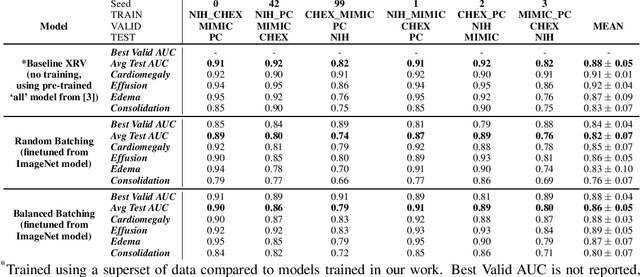
Learning models that generalize under different distribution shifts in medical imaging has been a long-standing research challenge. There have been several proposals for efficient and robust visual representation learning among vision research practitioners, especially in the sensitive and critical biomedical domain. In this paper, we propose an idea for out-of-distribution generalization of chest X-ray pathologies that uses a simple balanced batch sampling technique. We observed that balanced sampling between the multiple training datasets improves the performance over baseline models trained without balancing.
TorchXRayVision: A library of chest X-ray datasets and models
Oct 31, 2021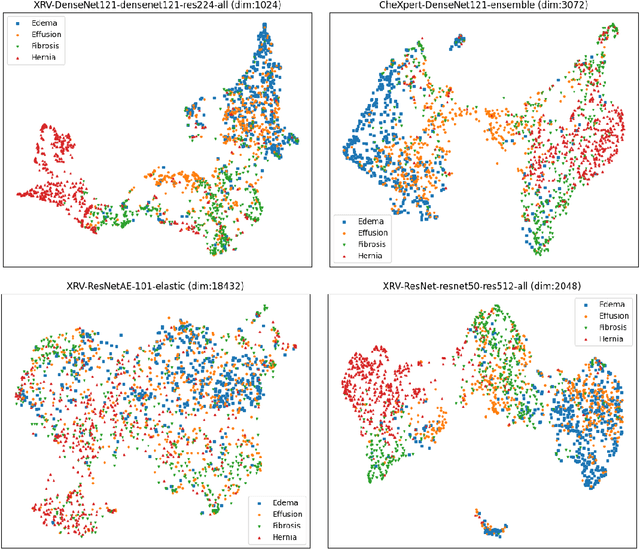
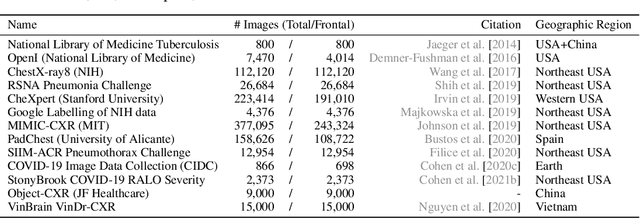
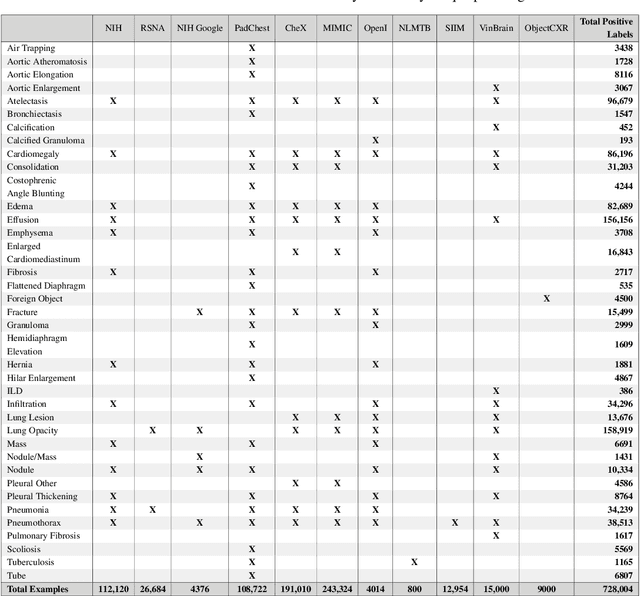
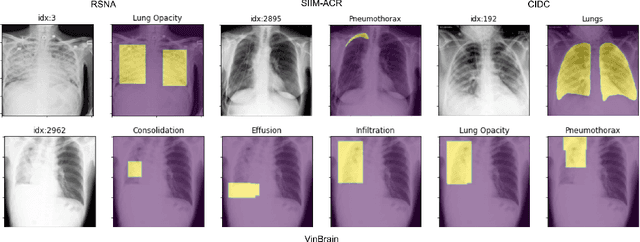
TorchXRayVision is an open source software library for working with chest X-ray datasets and deep learning models. It provides a common interface and common pre-processing chain for a wide set of publicly available chest X-ray datasets. In addition, a number of classification and representation learning models with different architectures, trained on different data combinations, are available through the library to serve as baselines or feature extractors.
Benefits of Linear Conditioning for Segmentation using Metadata
Feb 18, 2021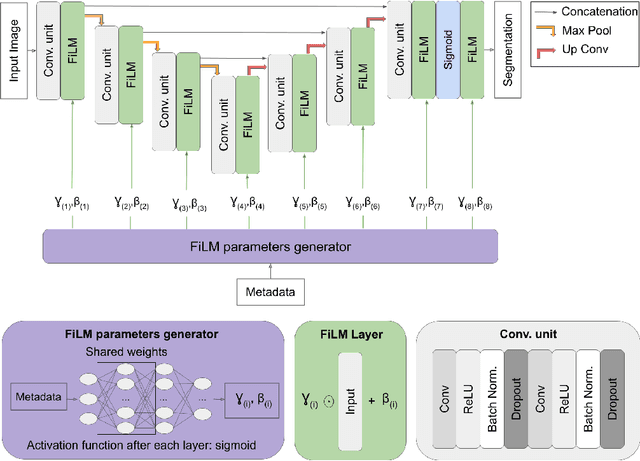

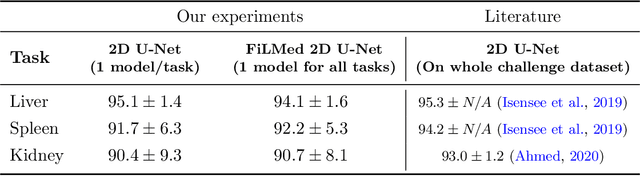

Medical images are often accompanied by metadata describing the image (vendor, acquisition parameters) and the patient (disease type or severity, demographics, genomics). This metadata is usually disregarded by image segmentation methods. In this work, we adapt a linear conditioning method called FiLM (Feature-wise Linear Modulation) for image segmentation tasks. This FiLM adaptation enables integrating metadata into segmentation models for better performance. We observed an average Dice score increase of 5.1% on spinal cord tumor segmentation when incorporating the tumor type with FiLM. The metadata modulates the segmentation process through low-cost affine transformations applied on feature maps which can be included in any neural network's architecture. Additionally, we assess the relevance of segmentation FiLM layers for tackling common challenges in medical imaging: training with limited or unbalanced number of annotated data, multi-class training with missing segmentations, and model adaptation to multiple tasks. Our results demonstrated the following benefits of FiLM for segmentation: FiLMed U-Net was robust to missing labels and reached higher Dice scores with few labels (up to 16.7%) compared to single-task U-Net. The code is open-source and available at www.ivadomed.org.
Gifsplanation via Latent Shift: A Simple Autoencoder Approach to Progressive Exaggeration on Chest X-rays
Feb 18, 2021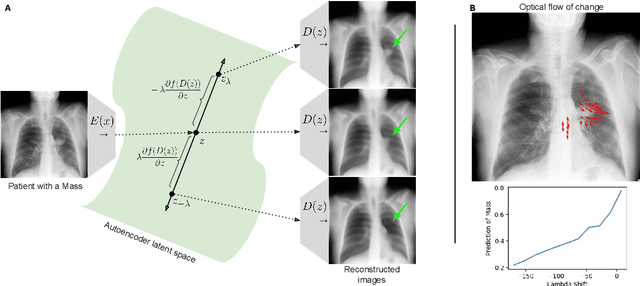

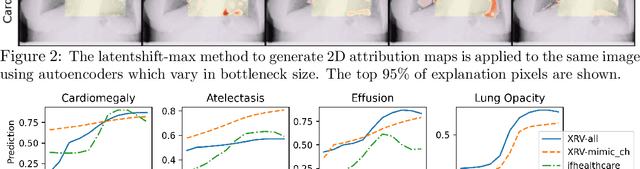

Motivation: Traditional image attribution methods struggle to satisfactorily explain predictions of neural networks. Prediction explanation is important, especially in the medical imaging, for avoiding the unintended consequences of deploying AI systems when false positive predictions can impact patient care. Thus, there is a pressing need to develop improved models for model explainability and introspection. Specific Problem: A new approach is to transform input images to increase or decrease features which cause the prediction. However, current approaches are difficult to implement as they are monolithic or rely on GANs. These hurdles prevent wide adoption. Our approach: Given an arbitrary classifier, we propose a simple autoencoder and gradient update (Latent Shift) that can transform the latent representation of an input image to exaggerate or curtail the features used for prediction. We use this method to study chest X-ray classifiers and evaluate their performance. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to identify which ones are false positives (half are) using traditional attribution maps or our proposed method. Results: We found low overlap with ground truth pathology masks for models with reasonably high accuracy. However, the results from our reader study indicate that these models are generally looking at the correct features. We also found that the Latent Shift explanation allows a user to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 in a 5 point scale with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). Accompanying webpage: https://mlmed.org/gifsplanation Source code: https://github.com/mlmed/gifsplanation