 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring morphometric drift in lifelong learning segmentation of the spinal cord
May 02, 2025Morphometric measures derived from spinal cord segmentations can serve as diagnostic and prognostic biomarkers in neurological diseases and injuries affecting the spinal cord. While robust, automatic segmentation methods to a wide variety of contrasts and pathologies have been developed over the past few years, whether their predictions are stable as the model is updated using new datasets has not been assessed. This is particularly important for deriving normative values from healthy participants. In this study, we present a spinal cord segmentation model trained on a multisite $(n=75)$ dataset, including 9 different MRI contrasts and several spinal cord pathologies. We also introduce a lifelong learning framework to automatically monitor the morphometric drift as the model is updated using additional datasets. The framework is triggered by an automatic GitHub Actions workflow every time a new model is created, recording the morphometric values derived from the model's predictions over time. As a real-world application of the proposed framework, we employed the spinal cord segmentation model to update a recently-introduced normative database of healthy participants containing commonly used measures of spinal cord morphometry. Results showed that: (i) our model outperforms previous versions and pathology-specific models on challenging lumbar spinal cord cases, achieving an average Dice score of $0.95 \pm 0.03$; (ii) the automatic workflow for monitoring morphometric drift provides a quick feedback loop for developing future segmentation models; and (iii) the scaling factor required to update the database of morphometric measures is nearly constant among slices across the given vertebral levels, showing minimum drift between the current and previous versions of the model monitored by the framework. The model is freely available in Spinal Cord Toolbox v7.0.
Rootlets-based registration to the spinal cord PAM50 template
Apr 30, 2025

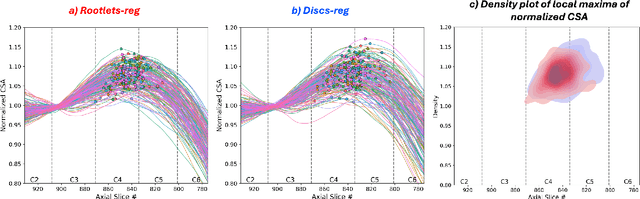

Spinal cord functional MRI studies require precise localization of spinal levels for reliable voxelwise group analyses. Traditional template-based registration of the spinal cord uses intervertebral discs for alignment. However, substantial anatomical variability across individuals exists between vertebral and spinal levels. This study proposes a novel registration approach that leverages spinal nerve rootlets to improve alignment accuracy and reproducibility across individuals. We developed a registration method leveraging dorsal cervical rootlets segmentation and aligning them non-linearly with the PAM50 spinal cord template. Validation was performed on a multi-subject, multi-site dataset (n=267, 44 sites) and a multi-subject dataset with various neck positions (n=10, 3 sessions). We further validated the method on task-based functional MRI (n=23) to compare group-level activation maps using rootlet-based registration to traditional disc-based methods. Rootlet-based registration showed superior alignment across individuals compared to the traditional disc-based method. Notably, rootlet positions were more stable across neck positions. Group-level analysis of task-based functional MRI using rootlet-based increased Z scores and activation cluster size compared to disc-based registration (number of active voxels from 3292 to 7978). Rootlet-based registration enhances both inter- and intra-subject anatomical alignment and yields better spatial normalization for group-level fMRI analyses. Our findings highlight the potential of rootlet-based registration to improve the precision and reliability of spinal cord neuroimaging group analysis.
Unpaired Modality Translation for Pseudo Labeling of Histology Images
Dec 03, 2024The segmentation of histological images is critical for various biomedical applications, yet the lack of annotated data presents a significant challenge. We propose a microscopy pseudo labeling pipeline utilizing unsupervised image translation to address this issue. Our method generates pseudo labels by translating between labeled and unlabeled domains without requiring prior annotation in the target domain. We evaluate two pseudo labeling strategies across three image domains increasingly dissimilar from the labeled data, demonstrating their effectiveness. Notably, our method achieves a mean Dice score of $0.736 \pm 0.005$ on a SEM dataset using the tutoring path, which involves training a segmentation model on synthetic data created by translating the labeled dataset (TEM) to the target modality (SEM). This approach aims to accelerate the annotation process by providing high-quality pseudo labels as a starting point for manual refinement.
Multi-Domain Data Aggregation for Axon and Myelin Segmentation in Histology Images
Sep 17, 2024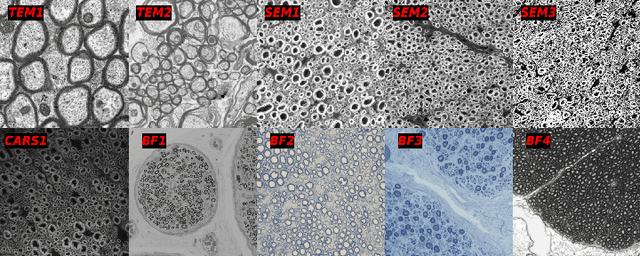
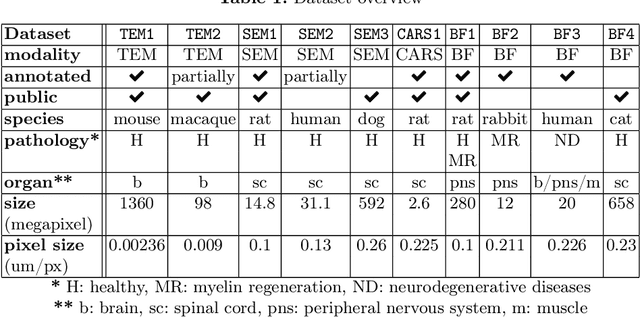

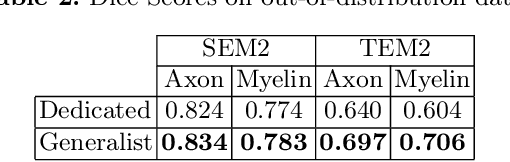
Quantifying axon and myelin properties (e.g., axon diameter, myelin thickness, g-ratio) in histology images can provide useful information about microstructural changes caused by neurodegenerative diseases. Automatic tissue segmentation is an important tool for these datasets, as a single stained section can contain up to thousands of axons. Advances in deep learning have made this task quick and reliable with minimal overhead, but a deep learning model trained by one research group will hardly ever be usable by other groups due to differences in their histology training data. This is partly due to subject diversity (different body parts, species, genetics, pathologies) and also to the range of modern microscopy imaging techniques resulting in a wide variability of image features (i.e., contrast, resolution). There is a pressing need to make AI accessible to neuroscience researchers to facilitate and accelerate their workflow, but publicly available models are scarce and poorly maintained. Our approach is to aggregate data from multiple imaging modalities (bright field, electron microscopy, Raman spectroscopy) and species (mouse, rat, rabbit, human), to create an open-source, durable tool for axon and myelin segmentation. Our generalist model makes it easier for researchers to process their data and can be fine-tuned for better performance on specific domains. We study the benefits of different aggregation schemes. This multi-domain segmentation model performs better than single-modality dedicated learners (p=0.03077), generalizes better on out-of-distribution data and is easier to use and maintain. Importantly, we package the segmentation tool into a well-maintained open-source software ecosystem (see https://github.com/axondeepseg/axondeepseg).
SCIsegV2: A Universal Tool for Segmentation of Intramedullary Lesions in Spinal Cord Injury
Jul 24, 2024Spinal cord injury (SCI) is a devastating incidence leading to permanent paralysis and loss of sensory-motor functions potentially resulting in the formation of lesions within the spinal cord. Imaging biomarkers obtained from magnetic resonance imaging (MRI) scans can predict the functional recovery of individuals with SCI and help choose the optimal treatment strategy. Currently, most studies employ manual quantification of these MRI-derived biomarkers, which is a subjective and tedious task. In this work, we propose (i) a universal tool for the automatic segmentation of intramedullary SCI lesions, dubbed \texttt{SCIsegV2}, and (ii) a method to automatically compute the width of the tissue bridges from the segmented lesion. Tissue bridges represent the spared spinal tissue adjacent to the lesion, which is associated with functional recovery in SCI patients. The tool was trained and validated on a heterogeneous dataset from 7 sites comprising patients from different SCI phases (acute, sub-acute, and chronic) and etiologies (traumatic SCI, ischemic SCI, and degenerative cervical myelopathy). Tissue bridges quantified automatically did not significantly differ from those computed manually, suggesting that the proposed automatic tool can be used to derive relevant MRI biomarkers. \texttt{SCIsegV2} and the automatic tissue bridges computation are open-source and available in Spinal Cord Toolbox (v6.4 and above) via the \texttt{sct\_deepseg -task seg\_sc\_lesion\_t2w\_sci} and \texttt{sct\_analyze\_lesion} functions, respectively.
Automatic Segmentation of the Spinal Cord Nerve Rootlets
Feb 01, 2024Precise identification of spinal nerve rootlets is relevant to delineate spinal levels for the study of functional activity in the spinal cord. The goal of this study was to develop an automatic method for the semantic segmentation of spinal nerve rootlets from T2-weighted magnetic resonance imaging (MRI) scans. Images from two open-access MRI datasets were used to train a 3D multi-class convolutional neural network using an active learning approach to segment C2-C8 dorsal nerve rootlets. Each output class corresponds to a spinal level. The method was tested on 3T T2-weighted images from datasets unseen during training to assess inter-site, inter-session, and inter-resolution variability. The test Dice score was 0.67 +- 0.16 (mean +- standard deviation across rootlets levels), suggesting a good performance. The method also demonstrated low inter-vendor and inter-site variability (coefficient of variation <= 1.41 %), as well as low inter-session variability (coefficient of variation <= 1.30 %) indicating stable predictions across different MRI vendors, sites, and sessions. The proposed methodology is open-source and readily available in the Spinal Cord Toolbox (SCT) v6.2 and higher.
Towards contrast-agnostic soft segmentation of the spinal cord
Oct 23, 2023



Spinal cord segmentation is clinically relevant and is notably used to compute spinal cord cross-sectional area (CSA) for the diagnosis and monitoring of cord compression or neurodegenerative diseases such as multiple sclerosis. While several semi and automatic methods exist, one key limitation remains: the segmentation depends on the MRI contrast, resulting in different CSA across contrasts. This is partly due to the varying appearance of the boundary between the spinal cord and the cerebrospinal fluid that depends on the sequence and acquisition parameters. This contrast-sensitive CSA adds variability in multi-center studies where protocols can vary, reducing the sensitivity to detect subtle atrophies. Moreover, existing methods enhance the CSA variability by training one model per contrast, while also producing binary masks that do not account for partial volume effects. In this work, we present a deep learning-based method that produces soft segmentations of the spinal cord. Using the Spine Generic Public Database of healthy participants ($\text{n}=267$; $\text{contrasts}=6$), we first generated participant-wise soft ground truth (GT) by averaging the binary segmentations across all 6 contrasts. These soft GT, along with a regression-based loss function, were then used to train a UNet model for spinal cord segmentation. We evaluated our model against state-of-the-art methods and performed ablation studies involving different GT mask types, loss functions, and contrast-specific models. Our results show that using the soft average segmentations along with a regression loss function reduces CSA variability ($p < 0.05$, Wilcoxon signed-rank test). The proposed spinal cord segmentation model generalizes better than the state-of-the-art contrast-specific methods amongst unseen datasets, vendors, contrasts, and pathologies (compression, lesions), while accounting for partial volume effects.
Enhancing Medical Image Segmentation with TransCeption: A Multi-Scale Feature Fusion Approach
Jan 25, 2023While CNN-based methods have been the cornerstone of medical image segmentation due to their promising performance and robustness, they suffer from limitations in capturing long-range dependencies. Transformer-based approaches are currently prevailing since they enlarge the reception field to model global contextual correlation. To further extract rich representations, some extensions of the U-Net employ multi-scale feature extraction and fusion modules and obtain improved performance. Inspired by this idea, we propose TransCeption for medical image segmentation, a pure transformer-based U-shape network featured by incorporating the inception-like module into the encoder and adopting a contextual bridge for better feature fusion. The design proposed in this work is based on three core principles: (1) The patch merging module in the encoder is redesigned with ResInception Patch Merging (RIPM). Multi-branch transformer (MB transformer) adopts the same number of branches as the outputs of RIPM. Combining the two modules enables the model to capture a multi-scale representation within a single stage. (2) We construct an Intra-stage Feature Fusion (IFF) module following the MB transformer to enhance the aggregation of feature maps from all the branches and particularly focus on the interaction between the different channels of all the scales. (3) In contrast to a bridge that only contains token-wise self-attention, we propose a Dual Transformer Bridge that also includes channel-wise self-attention to exploit correlations between scales at different stages from a dual perspective. Extensive experiments on multi-organ and skin lesion segmentation tasks present the superior performance of TransCeption compared to previous work. The code is publicly available at \url{https://github.com/mindflow-institue/TransCeption}.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Segmentation of Multiple Sclerosis Lesions across Hospitals: Learn Continually or Train from Scratch?
Oct 27, 2022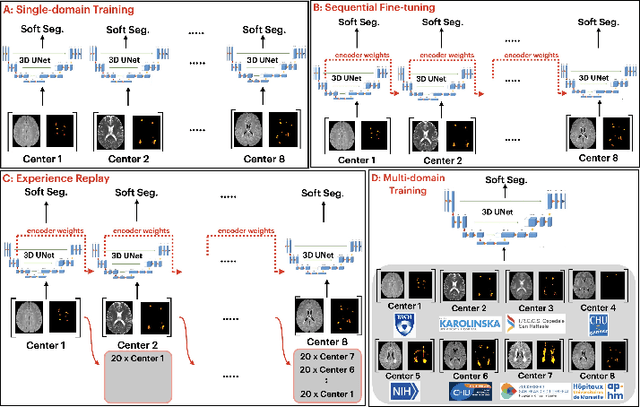
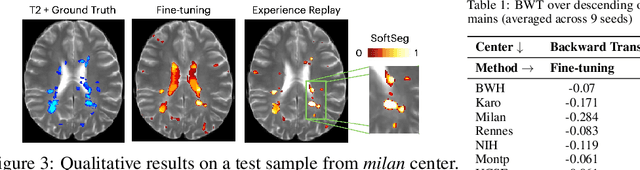
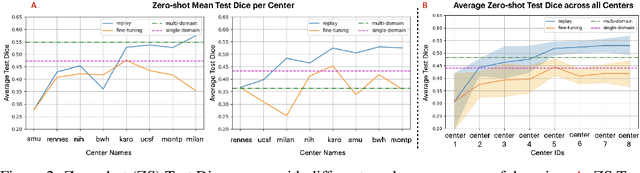
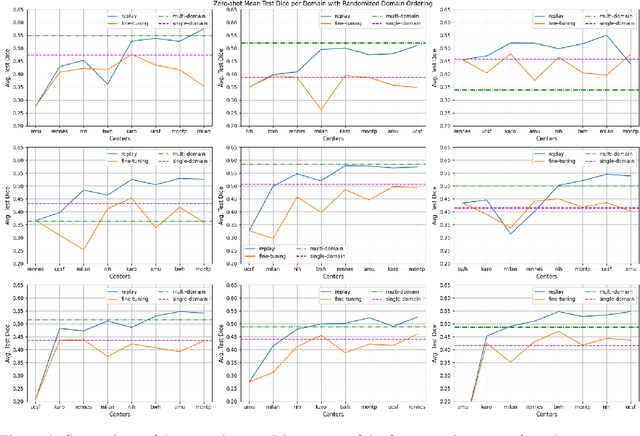
Segmentation of Multiple Sclerosis (MS) lesions is a challenging problem. Several deep-learning-based methods have been proposed in recent years. However, most methods tend to be static, that is, a single model trained on a large, specialized dataset, which does not generalize well. Instead, the model should learn across datasets arriving sequentially from different hospitals by building upon the characteristics of lesions in a continual manner. In this regard, we explore experience replay, a well-known continual learning method, in the context of MS lesion segmentation across multi-contrast data from 8 different hospitals. Our experiments show that replay is able to achieve positive backward transfer and reduce catastrophic forgetting compared to sequential fine-tuning. Furthermore, replay outperforms the multi-domain training, thereby emerging as a promising solution for the segmentation of MS lesions. The code is available at this link: https://github.com/naga-karthik/continual-learning-ms