 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace2Scene: Using Facial Degradation as an Oracle for Diffusion-Based Scene Restoration
Mar 17, 2026Recent advances in image restoration have enabled high-fidelity recovery of faces from degraded inputs using reference-based face restoration models (Ref-FR). However, such methods focus solely on facial regions, neglecting degradation across the full scene, including body and background, which limits practical usability. Meanwhile, full-scene restorers often ignore degradation cues entirely, leading to underdetermined predictions and visual artifacts. In this work, we propose Face2Scene, a two-stage restoration framework that leverages the face as a perceptual oracle to estimate degradation and guide the restoration of the entire image. Given a degraded image and one or more identity references, we first apply a Ref-FR model to reconstruct high-quality facial details. From the restored-degraded face pair, we extract a face-derived degradation code that captures degradation attributes (e.g., noise, blur, compression), which is then transformed into multi-scale degradation-aware tokens. These tokens condition a diffusion model to restore the full scene in a single step, including the body and background. Extensive experiments demonstrate the superior effectiveness of the proposed method compared to state-of-the-art methods.
LIFT: Latent Implicit Functions for Task- and Data-Agnostic Encoding
Mar 19, 2025Implicit Neural Representations (INRs) are proving to be a powerful paradigm in unifying task modeling across diverse data domains, offering key advantages such as memory efficiency and resolution independence. Conventional deep learning models are typically modality-dependent, often requiring custom architectures and objectives for different types of signals. However, existing INR frameworks frequently rely on global latent vectors or exhibit computational inefficiencies that limit their broader applicability. We introduce LIFT, a novel, high-performance framework that addresses these challenges by capturing multiscale information through meta-learning. LIFT leverages multiple parallel localized implicit functions alongside a hierarchical latent generator to produce unified latent representations that span local, intermediate, and global features. This architecture facilitates smooth transitions across local regions, enhancing expressivity while maintaining inference efficiency. Additionally, we introduce ReLIFT, an enhanced variant of LIFT that incorporates residual connections and expressive frequency encodings. With this straightforward approach, ReLIFT effectively addresses the convergence-capacity gap found in comparable methods, providing an efficient yet powerful solution to improve capacity and speed up convergence. Empirical results show that LIFT achieves state-of-the-art (SOTA) performance in generative modeling and classification tasks, with notable reductions in computational costs. Moreover, in single-task settings, the streamlined ReLIFT architecture proves effective in signal representations and inverse problem tasks.
STAF: Sinusoidal Trainable Activation Functions for Implicit Neural Representation
Feb 02, 2025Implicit Neural Representations (INRs) have emerged as a powerful framework for modeling continuous signals. The spectral bias of ReLU-based networks is a well-established limitation, restricting their ability to capture fine-grained details in target signals. While previous works have attempted to mitigate this issue through frequency-based encodings or architectural modifications, these approaches often introduce additional complexity and do not fully address the underlying challenge of learning high-frequency components efficiently. We introduce Sinusoidal Trainable Activation Functions (STAF), designed to directly tackle this limitation by enabling networks to adaptively learn and represent complex signals with higher precision and efficiency. STAF inherently modulates its frequency components, allowing for self-adaptive spectral learning. This capability significantly improves convergence speed and expressivity, making STAF highly effective for both signal representations and inverse problems. Through extensive evaluations, we demonstrate that STAF outperforms state-of-the-art (SOTA) methods in accuracy and reconstruction fidelity with superior Peak Signal-to-Noise Ratio (PSNR). These results establish STAF as a robust solution for overcoming spectral bias and the capacity-convergence gap, making it valuable for computer graphics and related fields. Our codebase is publicly accessible on the https://github.com/AlirezaMorsali/STAF.
SUM: Saliency Unification through Mamba for Visual Attention Modeling
Jun 25, 2024

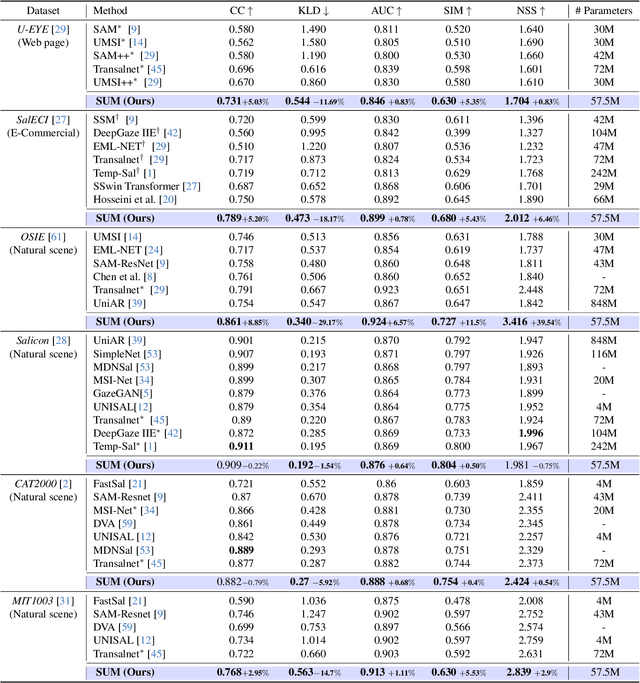

Visual attention modeling, important for interpreting and prioritizing visual stimuli, plays a significant role in applications such as marketing, multimedia, and robotics. Traditional saliency prediction models, especially those based on Convolutional Neural Networks (CNNs) or Transformers, achieve notable success by leveraging large-scale annotated datasets. However, the current state-of-the-art (SOTA) models that use Transformers are computationally expensive. Additionally, separate models are often required for each image type, lacking a unified approach. In this paper, we propose Saliency Unification through Mamba (SUM), a novel approach that integrates the efficient long-range dependency modeling of Mamba with U-Net to provide a unified model for diverse image types. Using a novel Conditional Visual State Space (C-VSS) block, SUM dynamically adapts to various image types, including natural scenes, web pages, and commercial imagery, ensuring universal applicability across different data types. Our comprehensive evaluations across five benchmarks demonstrate that SUM seamlessly adapts to different visual characteristics and consistently outperforms existing models. These results position SUM as a versatile and powerful tool for advancing visual attention modeling, offering a robust solution universally applicable across different types of visual content.
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Mar 28, 2024



Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our \href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}\footnote{\url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
FuseNet: Self-Supervised Dual-Path Network for Medical Image Segmentation
Nov 22, 2023Semantic segmentation, a crucial task in computer vision, often relies on labor-intensive and costly annotated datasets for training. In response to this challenge, we introduce FuseNet, a dual-stream framework for self-supervised semantic segmentation that eliminates the need for manual annotation. FuseNet leverages the shared semantic dependencies between the original and augmented images to create a clustering space, effectively assigning pixels to semantically related clusters, and ultimately generating the segmentation map. Additionally, FuseNet incorporates a cross-modal fusion technique that extends the principles of CLIP by replacing textual data with augmented images. This approach enables the model to learn complex visual representations, enhancing robustness against variations similar to CLIP's text invariance. To further improve edge alignment and spatial consistency between neighboring pixels, we introduce an edge refinement loss. This loss function considers edge information to enhance spatial coherence, facilitating the grouping of nearby pixels with similar visual features. Extensive experiments on skin lesion and lung segmentation datasets demonstrate the effectiveness of our method. \href{https://github.com/xmindflow/FuseNet}{Codebase.}
INCODE: Implicit Neural Conditioning with Prior Knowledge Embeddings
Oct 28, 2023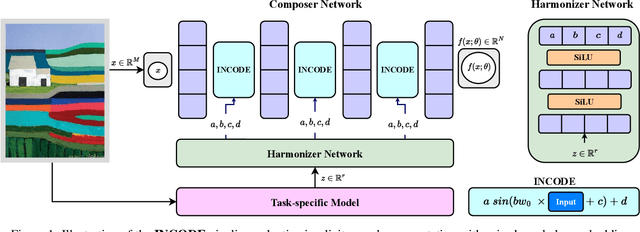
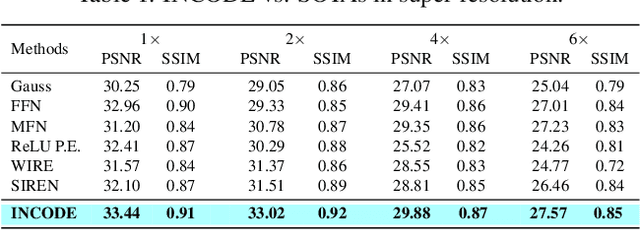
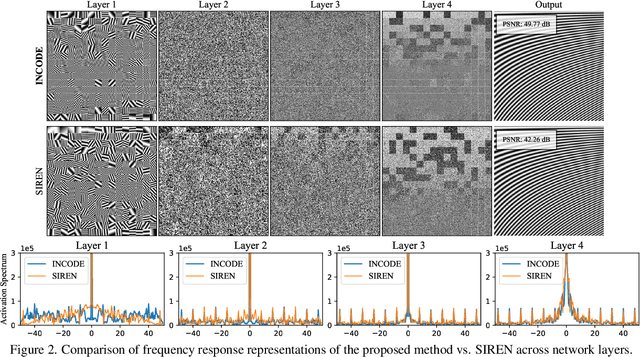

Implicit Neural Representations (INRs) have revolutionized signal representation by leveraging neural networks to provide continuous and smooth representations of complex data. However, existing INRs face limitations in capturing fine-grained details, handling noise, and adapting to diverse signal types. To address these challenges, we introduce INCODE, a novel approach that enhances the control of the sinusoidal-based activation function in INRs using deep prior knowledge. INCODE comprises a harmonizer network and a composer network, where the harmonizer network dynamically adjusts key parameters of the activation function. Through a task-specific pre-trained model, INCODE adapts the task-specific parameters to optimize the representation process. Our approach not only excels in representation, but also extends its prowess to tackle complex tasks such as audio, image, and 3D shape reconstructions, as well as intricate challenges such as neural radiance fields (NeRFs), and inverse problems, including denoising, super-resolution, inpainting, and CT reconstruction. Through comprehensive experiments, INCODE demonstrates its superiority in terms of robustness, accuracy, quality, and convergence rate, broadening the scope of signal representation. Please visit the project's website for details on the proposed method and access to the code.
Foundational Models in Medical Imaging: A Comprehensive Survey and Future Vision
Oct 28, 2023



Foundation models, large-scale, pre-trained deep-learning models adapted to a wide range of downstream tasks have gained significant interest lately in various deep-learning problems undergoing a paradigm shift with the rise of these models. Trained on large-scale dataset to bridge the gap between different modalities, foundation models facilitate contextual reasoning, generalization, and prompt capabilities at test time. The predictions of these models can be adjusted for new tasks by augmenting the model input with task-specific hints called prompts without requiring extensive labeled data and retraining. Capitalizing on the advances in computer vision, medical imaging has also marked a growing interest in these models. To assist researchers in navigating this direction, this survey intends to provide a comprehensive overview of foundation models in the domain of medical imaging. Specifically, we initiate our exploration by providing an exposition of the fundamental concepts forming the basis of foundation models. Subsequently, we offer a methodical taxonomy of foundation models within the medical domain, proposing a classification system primarily structured around training strategies, while also incorporating additional facets such as application domains, imaging modalities, specific organs of interest, and the algorithms integral to these models. Furthermore, we emphasize the practical use case of some selected approaches and then discuss the opportunities, applications, and future directions of these large-scale pre-trained models, for analyzing medical images. In the same vein, we address the prevailing challenges and research pathways associated with foundational models in medical imaging. These encompass the areas of interpretability, data management, computational requirements, and the nuanced issue of contextual comprehension.
Unlocking Fine-Grained Details with Wavelet-based High-Frequency Enhancement in Transformers
Sep 12, 2023Medical image segmentation is a critical task that plays a vital role in diagnosis, treatment planning, and disease monitoring. Accurate segmentation of anatomical structures and abnormalities from medical images can aid in the early detection and treatment of various diseases. In this paper, we address the local feature deficiency of the Transformer model by carefully re-designing the self-attention map to produce accurate dense prediction in medical images. To this end, we first apply the wavelet transformation to decompose the input feature map into low-frequency (LF) and high-frequency (HF) subbands. The LF segment is associated with coarse-grained features while the HF components preserve fine-grained features such as texture and edge information. Next, we reformulate the self-attention operation using the efficient Transformer to perform both spatial and context attention on top of the frequency representation. Furthermore, to intensify the importance of the boundary information, we impose an additional attention map by creating a Gaussian pyramid on top of the HF components. Moreover, we propose a multi-scale context enhancement block within skip connections to adaptively model inter-scale dependencies to overcome the semantic gap among stages of the encoder and decoder modules. Throughout comprehensive experiments, we demonstrate the effectiveness of our strategy on multi-organ and skin lesion segmentation benchmarks. The implementation code will be available upon acceptance. \href{https://github.com/mindflow-institue/WaveFormer}{GitHub}.
* Accepted in MICCAI 2023 workshop MLMI
Self-supervised Semantic Segmentation: Consistency over Transformation
Aug 31, 2023Accurate medical image segmentation is of utmost importance for enabling automated clinical decision procedures. However, prevailing supervised deep learning approaches for medical image segmentation encounter significant challenges due to their heavy dependence on extensive labeled training data. To tackle this issue, we propose a novel self-supervised algorithm, \textbf{S$^3$-Net}, which integrates a robust framework based on the proposed Inception Large Kernel Attention (I-LKA) modules. This architectural enhancement makes it possible to comprehensively capture contextual information while preserving local intricacies, thereby enabling precise semantic segmentation. Furthermore, considering that lesions in medical images often exhibit deformations, we leverage deformable convolution as an integral component to effectively capture and delineate lesion deformations for superior object boundary definition. Additionally, our self-supervised strategy emphasizes the acquisition of invariance to affine transformations, which is commonly encountered in medical scenarios. This emphasis on robustness with respect to geometric distortions significantly enhances the model's ability to accurately model and handle such distortions. To enforce spatial consistency and promote the grouping of spatially connected image pixels with similar feature representations, we introduce a spatial consistency loss term. This aids the network in effectively capturing the relationships among neighboring pixels and enhancing the overall segmentation quality. The S$^3$-Net approach iteratively learns pixel-level feature representations for image content clustering in an end-to-end manner. Our experimental results on skin lesion and lung organ segmentation tasks show the superior performance of our method compared to the SOTA approaches. https://github.com/mindflow-institue/SSCT