 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Unsupervised and Supervised Autoencoders for Nuclei Classification in Clear Cell Renal Cell Carcinoma Images
Apr 04, 2025This study explores the application of supervised and unsupervised autoencoders (AEs) to automate nuclei classification in clear cell renal cell carcinoma (ccRCC) images, a diagnostic task traditionally reliant on subjective visual grading by pathologists. We evaluate various AE architectures, including standard AEs, contractive AEs (CAEs), and discriminative AEs (DAEs), as well as a classifier-based discriminative AE (CDAE), optimized using the hyperparameter tuning tool Optuna. Bhattacharyya distance is selected from several metrics to assess class separability in the latent space, revealing challenges in distinguishing adjacent grades using unsupervised models. CDAE, integrating a supervised classifier branch, demonstrated superior performance in both latent space separation and classification accuracy. Given that CDAE-CNN achieved notable improvements in classification metrics, affirming the value of supervised learning for class-specific feature extraction, F1 score was incorporated into the tuning process to optimize classification performance. Results show significant improvements in identifying aggressive ccRCC grades by leveraging the classification capability of AE through latent clustering followed by fine-grained classification. Our model outperforms the current state of the art, CHR-Network, across all evaluated metrics. These findings suggest that integrating a classifier branch in AEs, combined with neural architecture search and contrastive learning, enhances grading automation in ccRCC pathology, particularly in detecting aggressive tumor grades, and may improve diagnostic accuracy.
Enhancing Lidar-based Object Detection in Adverse Weather using Offset Sequences in Time
Jan 17, 2024Automated vehicles require an accurate perception of their surroundings for safe and efficient driving. Lidar-based object detection is a widely used method for environment perception, but its performance is significantly affected by adverse weather conditions such as rain and fog. In this work, we investigate various strategies for enhancing the robustness of lidar-based object detection by processing sequential data samples generated by lidar sensors. Our approaches leverage temporal information to improve a lidar object detection model, without the need for additional filtering or pre-processing steps. We compare $10$ different neural network architectures that process point cloud sequences including a novel augmentation strategy introducing a temporal offset between frames of a sequence during training and evaluate the effectiveness of all strategies on lidar point clouds under adverse weather conditions through experiments. Our research provides a comprehensive study of effective methods for mitigating the effects of adverse weather on the reliability of lidar-based object detection using sequential data that are evaluated using public datasets such as nuScenes, Dense, and the Canadian Adverse Driving Conditions Dataset. Our findings demonstrate that our novel method, involving temporal offset augmentation through randomized frame skipping in sequences, enhances object detection accuracy compared to both the baseline model (Pillar-based Object Detection) and no augmentation.
Unlocking Fine-Grained Details with Wavelet-based High-Frequency Enhancement in Transformers
Sep 12, 2023Medical image segmentation is a critical task that plays a vital role in diagnosis, treatment planning, and disease monitoring. Accurate segmentation of anatomical structures and abnormalities from medical images can aid in the early detection and treatment of various diseases. In this paper, we address the local feature deficiency of the Transformer model by carefully re-designing the self-attention map to produce accurate dense prediction in medical images. To this end, we first apply the wavelet transformation to decompose the input feature map into low-frequency (LF) and high-frequency (HF) subbands. The LF segment is associated with coarse-grained features while the HF components preserve fine-grained features such as texture and edge information. Next, we reformulate the self-attention operation using the efficient Transformer to perform both spatial and context attention on top of the frequency representation. Furthermore, to intensify the importance of the boundary information, we impose an additional attention map by creating a Gaussian pyramid on top of the HF components. Moreover, we propose a multi-scale context enhancement block within skip connections to adaptively model inter-scale dependencies to overcome the semantic gap among stages of the encoder and decoder modules. Throughout comprehensive experiments, we demonstrate the effectiveness of our strategy on multi-organ and skin lesion segmentation benchmarks. The implementation code will be available upon acceptance. \href{https://github.com/mindflow-institue/WaveFormer}{GitHub}.
* Accepted in MICCAI 2023 workshop MLMI
Advances in Medical Image Analysis with Vision Transformers: A Comprehensive Review
Jan 10, 2023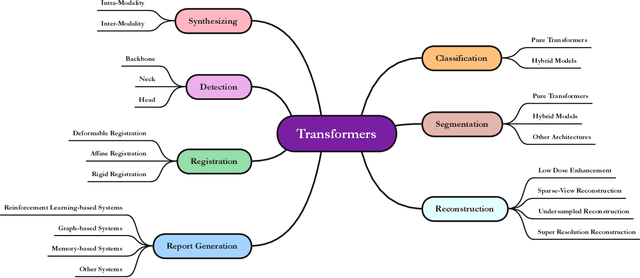
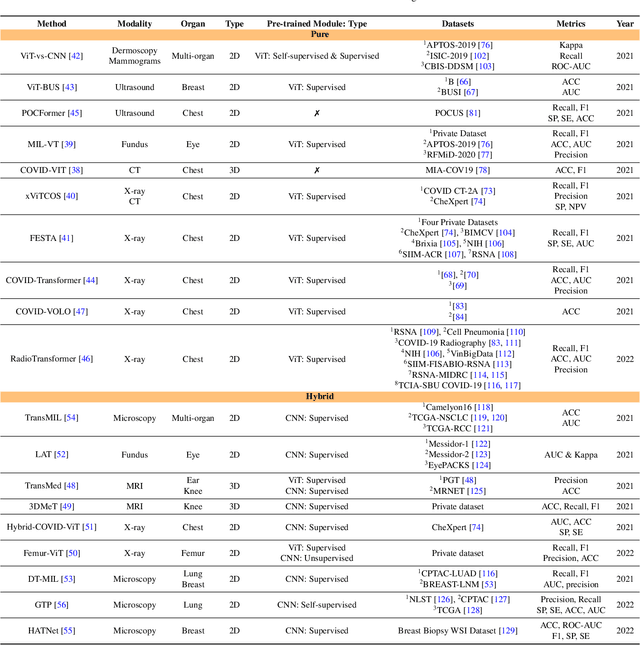
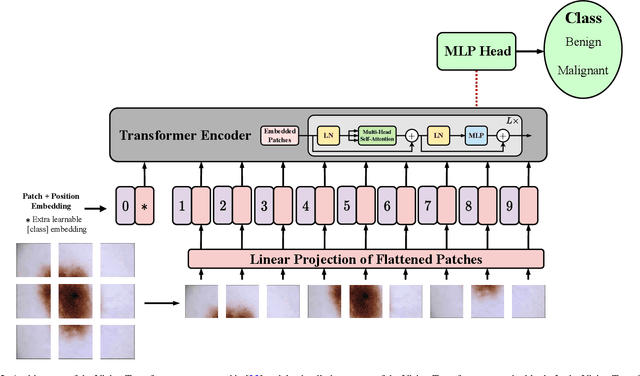
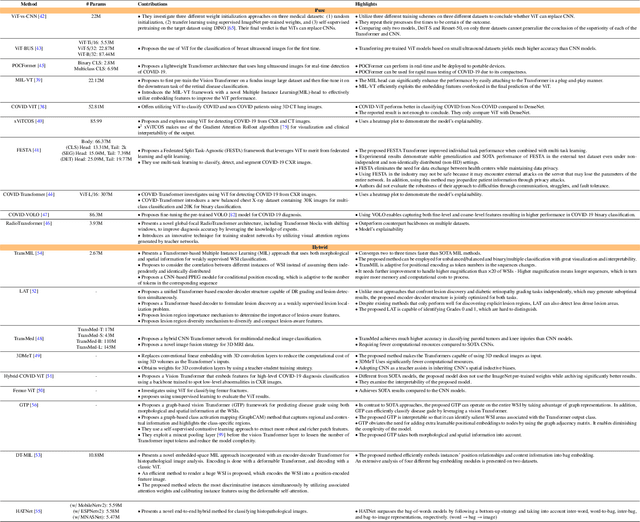
The remarkable performance of the Transformer architecture in natural language processing has recently also triggered broad interest in Computer Vision. Among other merits, Transformers are witnessed as capable of learning long-range dependencies and spatial correlations, which is a clear advantage over convolutional neural networks (CNNs), which have been the de facto standard in Computer Vision problems so far. Thus, Transformers have become an integral part of modern medical image analysis. In this review, we provide an encyclopedic review of the applications of Transformers in medical imaging. Specifically, we present a systematic and thorough review of relevant recent Transformer literature for different medical image analysis tasks, including classification, segmentation, detection, registration, synthesis, and clinical report generation. For each of these applications, we investigate the novelty, strengths and weaknesses of the different proposed strategies and develop taxonomies highlighting key properties and contributions. Further, if applicable, we outline current benchmarks on different datasets. Finally, we summarize key challenges and discuss different future research directions. In addition, we have provided cited papers with their corresponding implementations in https://github.com/mindflow-institue/Awesome-Transformer.
Deep Hashing with Hash Center Update for Efficient Image Retrieval
Jun 11, 2021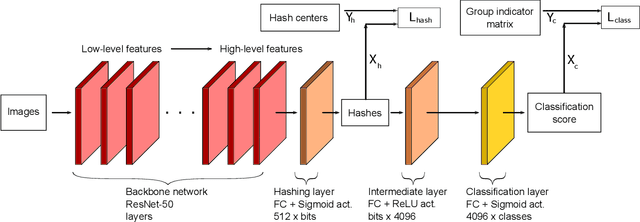
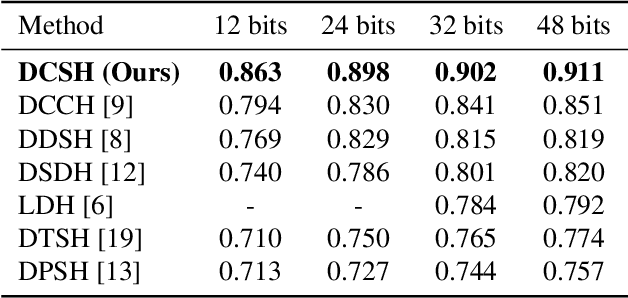
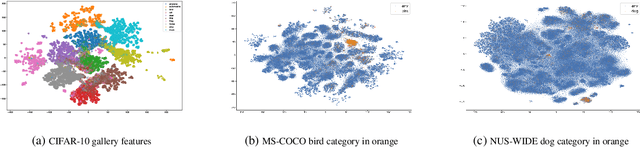
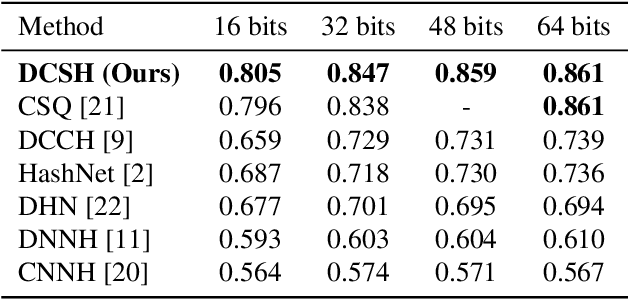
In this paper, we propose an approach for learning binary hash codes for image retrieval. Canonical Correlation Analysis (CCA) is used to design two loss functions for training a neural network such that the correlation between the two views to CCA is maximized. The first loss, maximizes the correlation between the hash centers and learned hash codes. The second loss maximizes the correlation between the class labels and classification scores. A novel weighted mean and thresholding based hash center update scheme is proposed for adapting the hash centers in each epoch. The training loss reaches the theoretical lower bound of the proposed loss functions, showing that the correlation coefficients are maximized during training and substantiating the formation of an efficient feature space for image retrieval. The measured mean average precision shows that the proposed approach outperforms other state-of-the-art approaches in both single-labeled and multi-labeled image datasets.
Optimized Feature Space Learning for Generating Efficient Binary Codes for Image Retrieval
Jan 30, 2020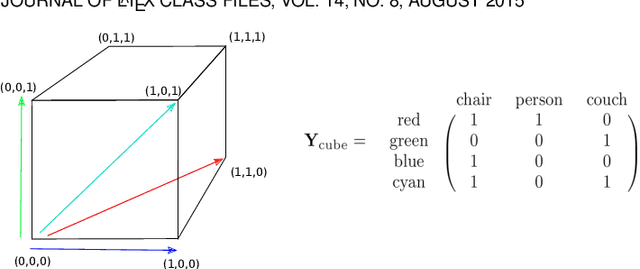

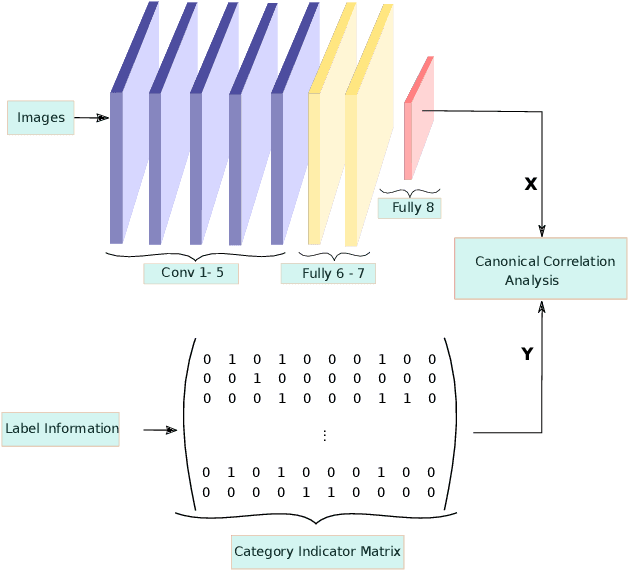
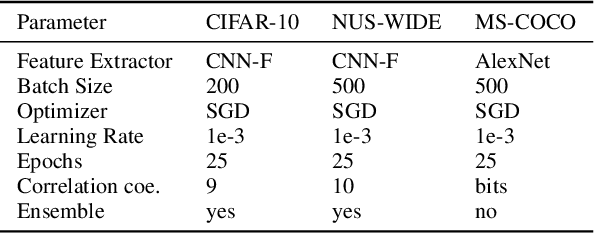
In this paper we propose an approach for learning low dimensional optimized feature space with minimum intra-class variance and maximum inter-class variance. We address the problem of high-dimensionality of feature vectors extracted from neural networks by taking care of the global statistics of feature space. Classical approach of Linear Discriminant Analysis (LDA) is generally used for generating an optimized low dimensional feature space for single-labeled images. Since, image retrieval involves both multi-labeled and single-labeled images, we utilize the equivalence between LDA and Canonical Correlation Analysis (CCA) to generate an optimized feature space for single-labeled images and use CCA to generate an optimized feature space for multi-labeled images. Our approach correlates the projections of feature vectors with label vectors in our CCA based network architecture. The neural network minimize a loss function which maximizes the correlation coefficients. We binarize our generated feature vectors with the popular Iterative Quantization (ITQ) approach and also propose an ensemble network to generate binary codes of desired bit length for image retrieval. Our measurement of mean average precision shows competitive results on other state-of-the-art single-labeled and multi-labeled image retrieval datasets.