 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCENet: Context Enhancement Network for Medical Image Segmentation
May 23, 2025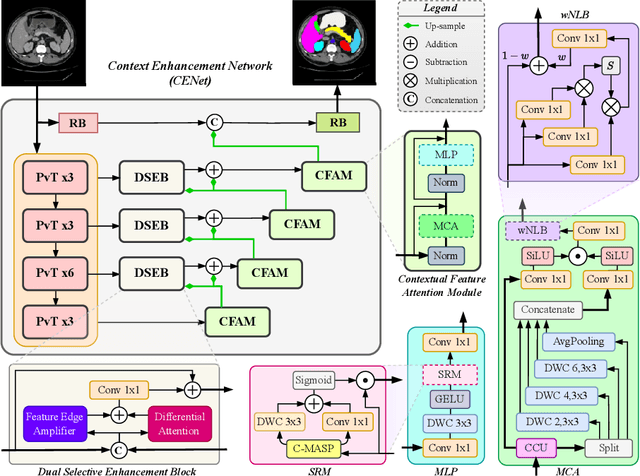
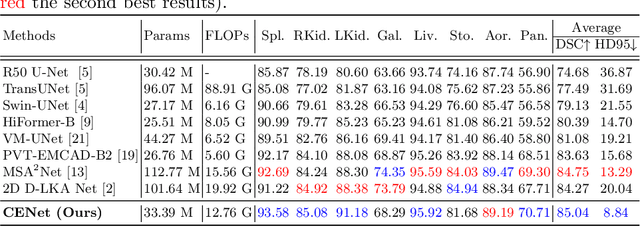
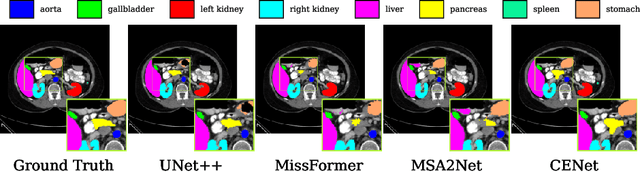
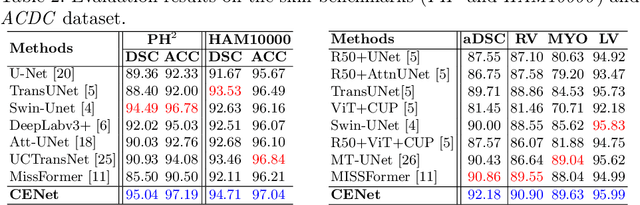
Medical image segmentation, particularly in multi-domain scenarios, requires precise preservation of anatomical structures across diverse representations. While deep learning has advanced this field, existing models often struggle with accurate boundary representation, variability in organ morphology, and information loss during downsampling, limiting their accuracy and robustness. To address these challenges, we propose the Context Enhancement Network (CENet), a novel segmentation framework featuring two key innovations. First, the Dual Selective Enhancement Block (DSEB) integrated into skip connections enhances boundary details and improves the detection of smaller organs in a context-aware manner. Second, the Context Feature Attention Module (CFAM) in the decoder employs a multi-scale design to maintain spatial integrity, reduce feature redundancy, and mitigate overly enhanced representations. Extensive evaluations on both radiology and dermoscopic datasets demonstrate that CENet outperforms state-of-the-art (SOTA) methods in multi-organ segmentation and boundary detail preservation, offering a robust and accurate solution for complex medical image analysis tasks. The code is publicly available at https://github.com/xmindflow/cenet.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Single-Layer Learnable Activation for Implicit Neural Representation (SL$^{2}$A-INR)
Sep 18, 2024



Implicit Neural Representation (INR), leveraging a neural network to transform coordinate input into corresponding attributes, has recently driven significant advances in several vision-related domains. However, the performance of INR is heavily influenced by the choice of the nonlinear activation function used in its multilayer perceptron (MLP) architecture. Multiple nonlinearities have been investigated; yet, current INRs face limitations in capturing high-frequency components, diverse signal types, and handling inverse problems. We have identified that these problems can be greatly alleviated by introducing a paradigm shift in INRs. We find that an architecture with learnable activations in initial layers can represent fine details in the underlying signals. Specifically, we propose SL$^{2}$A-INR, a hybrid network for INR with a single-layer learnable activation function, prompting the effectiveness of traditional ReLU-based MLPs. Our method performs superior across diverse tasks, including image representation, 3D shape reconstructions, inpainting, single image super-resolution, CT reconstruction, and novel view synthesis. Through comprehensive experiments, SL$^{2}$A-INR sets new benchmarks in accuracy, quality, and convergence rates for INR.
MSA$^2$Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation
Aug 03, 2024Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSA$^2$Net, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSA$^2$Net outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at https://github.com/xmindflow/MSA-2Net.
MSA2Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation
Jul 31, 2024Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSA2Net, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSA2Net outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at https://github.com/xmindflow/MSA-2Net.
Computation-Efficient Era: A Comprehensive Survey of State Space Models in Medical Image Analysis
Jun 05, 2024



Sequence modeling plays a vital role across various domains, with recurrent neural networks being historically the predominant method of performing these tasks. However, the emergence of transformers has altered this paradigm due to their superior performance. Built upon these advances, transformers have conjoined CNNs as two leading foundational models for learning visual representations. However, transformers are hindered by the $\mathcal{O}(N^2)$ complexity of their attention mechanisms, while CNNs lack global receptive fields and dynamic weight allocation. State Space Models (SSMs), specifically the \textit{\textbf{Mamba}} model with selection mechanisms and hardware-aware architecture, have garnered immense interest lately in sequential modeling and visual representation learning, challenging the dominance of transformers by providing infinite context lengths and offering substantial efficiency maintaining linear complexity in the input sequence. Capitalizing on the advances in computer vision, medical imaging has heralded a new epoch with Mamba models. Intending to help researchers navigate the surge, this survey seeks to offer an encyclopedic review of Mamba models in medical imaging. Specifically, we start with a comprehensive theoretical review forming the basis of SSMs, including Mamba architecture and its alternatives for sequence modeling paradigms in this context. Next, we offer a structured classification of Mamba models in the medical field and introduce a diverse categorization scheme based on their application, imaging modalities, and targeted organs. Finally, we summarize key challenges, discuss different future research directions of the SSMs in the medical domain, and propose several directions to fulfill the demands of this field. In addition, we have compiled the studies discussed in this paper along with their open-source implementations on our GitHub repository.
LHU-Net: A Light Hybrid U-Net for Cost-Efficient, High-Performance Volumetric Medical Image Segmentation
Apr 07, 2024As a result of the rise of Transformer architectures in medical image analysis, specifically in the domain of medical image segmentation, a multitude of hybrid models have been created that merge the advantages of Convolutional Neural Networks (CNNs) and Transformers. These hybrid models have achieved notable success by significantly improving segmentation accuracy. Yet, this progress often comes at the cost of increased model complexity, both in terms of parameters and computational demand. Moreover, many of these models fail to consider the crucial interplay between spatial and channel features, which could further refine and improve segmentation outcomes. To address this, we introduce LHU-Net, a Light Hybrid U-Net architecture optimized for volumetric medical image segmentation. LHU-Net is meticulously designed to prioritize spatial feature analysis in its initial layers before shifting focus to channel-based features in its deeper layers, ensuring a comprehensive feature extraction process. Rigorous evaluation across five benchmark datasets - Synapse, LA, Pancreas, ACDC, and BRaTS 2018 - underscores LHU-Net's superior performance, showcasing its dual capacity for efficiency and accuracy. Notably, LHU-Net sets new performance benchmarks, such as attaining a Dice score of 92.66 on the ACDC dataset, while simultaneously reducing parameters by 85% and quartering the computational load compared to existing state-of-the-art models. Achieved without any reliance on pre-training, additional data, or model ensemble, LHU-Net's effectiveness is further evidenced by its state-of-the-art performance across all evaluated datasets, utilizing fewer than 11 million parameters. This achievement highlights that balancing computational efficiency with high accuracy in medical image segmentation is feasible. Our implementation of LHU-Net is freely accessible to the research community on GitHub.
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Mar 28, 2024



Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our \href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}\footnote{\url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
Continual Learning in Medical Imaging Analysis: A Comprehensive Review of Recent Advancements and Future Prospects
Dec 28, 2023Medical imaging analysis has witnessed remarkable advancements even surpassing human-level performance in recent years, driven by the rapid development of advanced deep-learning algorithms. However, when the inference dataset slightly differs from what the model has seen during one-time training, the model performance is greatly compromised. The situation requires restarting the training process using both the old and the new data which is computationally costly, does not align with the human learning process, and imposes storage constraints and privacy concerns. Alternatively, continual learning has emerged as a crucial approach for developing unified and sustainable deep models to deal with new classes, tasks, and the drifting nature of data in non-stationary environments for various application areas. Continual learning techniques enable models to adapt and accumulate knowledge over time, which is essential for maintaining performance on evolving datasets and novel tasks. This systematic review paper provides a comprehensive overview of the state-of-the-art in continual learning techniques applied to medical imaging analysis. We present an extensive survey of existing research, covering topics including catastrophic forgetting, data drifts, stability, and plasticity requirements. Further, an in-depth discussion of key components of a continual learning framework such as continual learning scenarios, techniques, evaluation schemes, and metrics is provided. Continual learning techniques encompass various categories, including rehearsal, regularization, architectural, and hybrid strategies. We assess the popularity and applicability of continual learning categories in various medical sub-fields like radiology and histopathology...
Loss Functions in the Era of Semantic Segmentation: A Survey and Outlook
Dec 08, 2023



Semantic image segmentation, the process of classifying each pixel in an image into a particular class, plays an important role in many visual understanding systems. As the predominant criterion for evaluating the performance of statistical models, loss functions are crucial for shaping the development of deep learning-based segmentation algorithms and improving their overall performance. To aid researchers in identifying the optimal loss function for their particular application, this survey provides a comprehensive and unified review of $25$ loss functions utilized in image segmentation. We provide a novel taxonomy and thorough review of how these loss functions are customized and leveraged in image segmentation, with a systematic categorization emphasizing their significant features and applications. Furthermore, to evaluate the efficacy of these methods in real-world scenarios, we propose unbiased evaluations of some distinct and renowned loss functions on established medical and natural image datasets. We conclude this review by identifying current challenges and unveiling future research opportunities. Finally, we have compiled the reviewed studies that have open-source implementations on our GitHub page.