 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation-Efficient Era: A Comprehensive Survey of State Space Models in Medical Image Analysis
Jun 05, 2024



Sequence modeling plays a vital role across various domains, with recurrent neural networks being historically the predominant method of performing these tasks. However, the emergence of transformers has altered this paradigm due to their superior performance. Built upon these advances, transformers have conjoined CNNs as two leading foundational models for learning visual representations. However, transformers are hindered by the $\mathcal{O}(N^2)$ complexity of their attention mechanisms, while CNNs lack global receptive fields and dynamic weight allocation. State Space Models (SSMs), specifically the \textit{\textbf{Mamba}} model with selection mechanisms and hardware-aware architecture, have garnered immense interest lately in sequential modeling and visual representation learning, challenging the dominance of transformers by providing infinite context lengths and offering substantial efficiency maintaining linear complexity in the input sequence. Capitalizing on the advances in computer vision, medical imaging has heralded a new epoch with Mamba models. Intending to help researchers navigate the surge, this survey seeks to offer an encyclopedic review of Mamba models in medical imaging. Specifically, we start with a comprehensive theoretical review forming the basis of SSMs, including Mamba architecture and its alternatives for sequence modeling paradigms in this context. Next, we offer a structured classification of Mamba models in the medical field and introduce a diverse categorization scheme based on their application, imaging modalities, and targeted organs. Finally, we summarize key challenges, discuss different future research directions of the SSMs in the medical domain, and propose several directions to fulfill the demands of this field. In addition, we have compiled the studies discussed in this paper along with their open-source implementations on our GitHub repository.
Iranian License Plate Recognition Using a Reliable Deep Learning Approach
May 03, 2023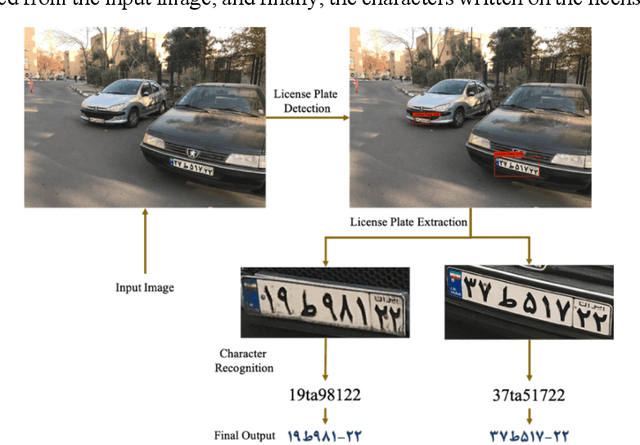
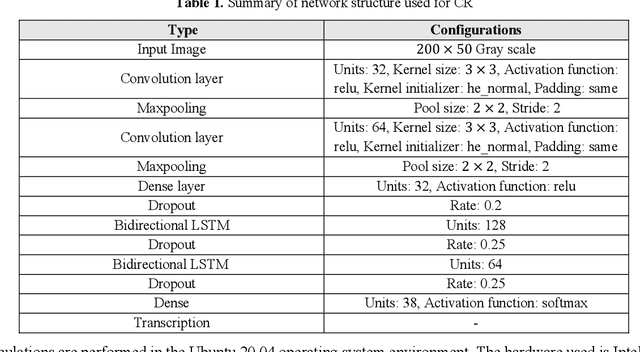

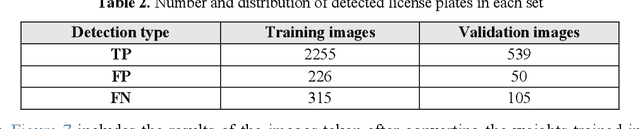
The issue of Automatic License Plate Recognition (ALPR) has been one of the most challenging issues in recent years. Weather conditions, camera angle of view, lighting conditions, different characters written on license plates, and many other factors are among the challenges for the issue of ALPR. Given the advances that have been made in recent years in the field of deep neural networks, some types of neural networks and models based on them can be used to perform the task of Iranian license plate recognition. In the proposed method presented in this paper, the license plate recognition is done in two steps. The first step is to detect the rectangles of the license plates from the input image. In the second step, these license plates are cropped from the image and their characters are recognized. For the first step, 3065 images including license plates and for the second step, 3364 images including characters of license plates have been prepared and considered as the desired datasets. In the first step, license plates are detected using the YOLOv4-tiny model, which is based on Convolutional Neural Network (CNN). In the next step, the characters of these license plates are recognized using Convolutional Recurrent Neural Network (CRNN), and Connectionist Temporal Classification (CTC). In the second step, there is no need to segment and label the characters separately, only one string of numbers and letters is enough for the labels.
Wearing face mask detection using deep learning through COVID-19 pandemic
Apr 28, 2023



During the COVID-19 pandemic, wearing a face mask has been known to be an effective way to prevent the spread of COVID-19. In lots of monitoring tasks, humans have been replaced with computers thanks to the outstanding performance of the deep learning models. Monitoring the wearing of a face mask is another task that can be done by deep learning models with acceptable accuracy. The main challenge of this task is the limited amount of data because of the quarantine. In this paper, we did an investigation on the capability of three state-of-the-art object detection neural networks on face mask detection for real-time applications. As mentioned, here are three models used, Single Shot Detector (SSD), two versions of You Only Look Once (YOLO) i.e., YOLOv4-tiny, and YOLOv4-tiny-3l from which the best was selected. In the proposed method, according to the performance of different models, the best model that can be suitable for use in real-world and mobile device applications in comparison to other recent studies was the YOLOv4-tiny model, with 85.31% and 50.66 for mean Average Precision (mAP) and Frames Per Second (FPS), respectively. These acceptable values were achieved using two datasets with only 1531 images in three separate classes.