 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDAE: Dual Attention Mechanism in a Hierarchical Transformer for Efficient Medical Image Segmentation
Sep 03, 2024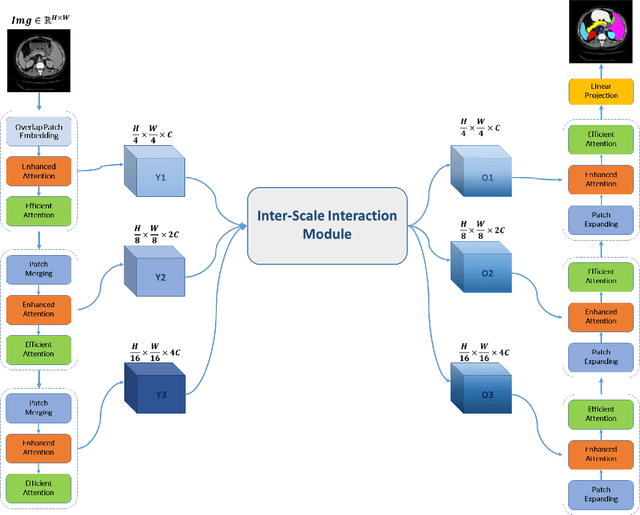
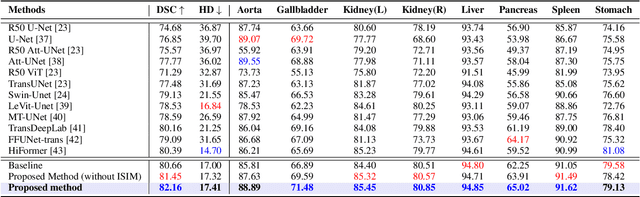

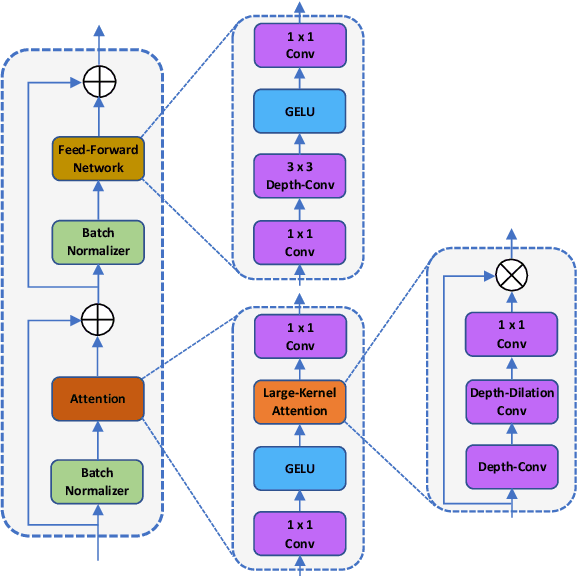
In healthcare, medical image segmentation is crucial for accurate disease diagnosis and the development of effective treatment strategies. Early detection can significantly aid in managing diseases and potentially prevent their progression. Machine learning, particularly deep convolutional neural networks, has emerged as a promising approach to addressing segmentation challenges. Traditional methods like U-Net use encoding blocks for local representation modeling and decoding blocks to uncover semantic relationships. However, these models often struggle with multi-scale objects exhibiting significant variations in texture and shape, and they frequently fail to capture long-range dependencies in the input data. Transformers designed for sequence-to-sequence predictions have been proposed as alternatives, utilizing global self-attention mechanisms. Yet, they can sometimes lack precise localization due to insufficient granular details. To overcome these limitations, we introduce TransDAE: a novel approach that reimagines the self-attention mechanism to include both spatial and channel-wise associations across the entire feature space, while maintaining computational efficiency. Additionally, TransDAE enhances the skip connection pathway with an inter-scale interaction module, promoting feature reuse and improving localization accuracy. Remarkably, TransDAE outperforms existing state-of-the-art methods on the Synaps multi-organ dataset, even without relying on pre-trained weights.
Computation-Efficient Era: A Comprehensive Survey of State Space Models in Medical Image Analysis
Jun 05, 2024



Sequence modeling plays a vital role across various domains, with recurrent neural networks being historically the predominant method of performing these tasks. However, the emergence of transformers has altered this paradigm due to their superior performance. Built upon these advances, transformers have conjoined CNNs as two leading foundational models for learning visual representations. However, transformers are hindered by the $\mathcal{O}(N^2)$ complexity of their attention mechanisms, while CNNs lack global receptive fields and dynamic weight allocation. State Space Models (SSMs), specifically the \textit{\textbf{Mamba}} model with selection mechanisms and hardware-aware architecture, have garnered immense interest lately in sequential modeling and visual representation learning, challenging the dominance of transformers by providing infinite context lengths and offering substantial efficiency maintaining linear complexity in the input sequence. Capitalizing on the advances in computer vision, medical imaging has heralded a new epoch with Mamba models. Intending to help researchers navigate the surge, this survey seeks to offer an encyclopedic review of Mamba models in medical imaging. Specifically, we start with a comprehensive theoretical review forming the basis of SSMs, including Mamba architecture and its alternatives for sequence modeling paradigms in this context. Next, we offer a structured classification of Mamba models in the medical field and introduce a diverse categorization scheme based on their application, imaging modalities, and targeted organs. Finally, we summarize key challenges, discuss different future research directions of the SSMs in the medical domain, and propose several directions to fulfill the demands of this field. In addition, we have compiled the studies discussed in this paper along with their open-source implementations on our GitHub repository.
HCA-Net: Hierarchical Context Attention Network for Intervertebral Disc Semantic Labeling
Nov 21, 2023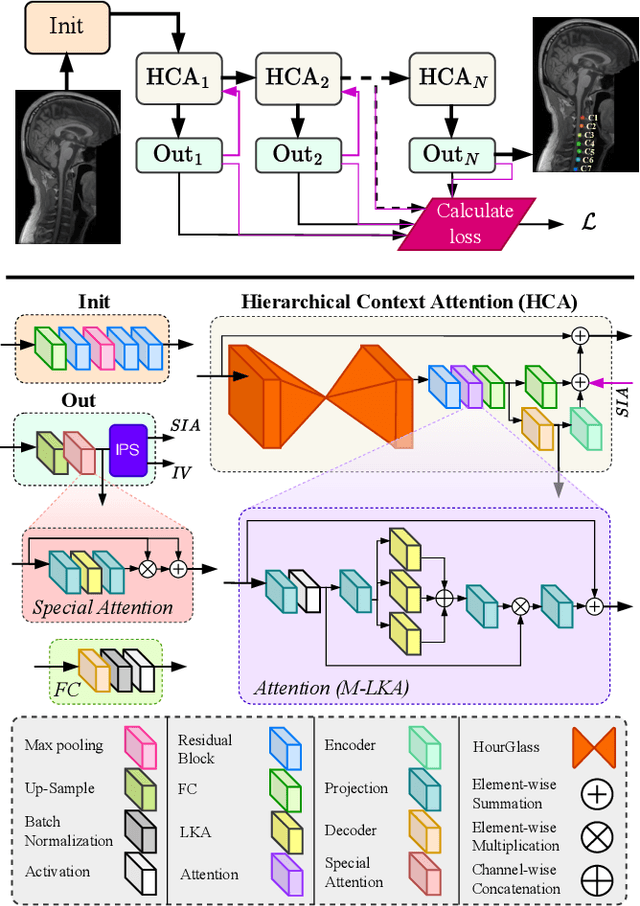

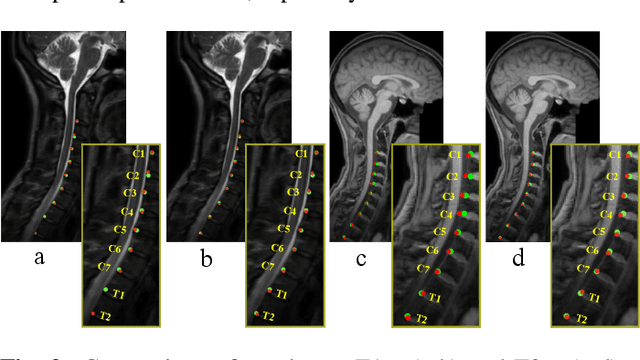
Accurate and automated segmentation of intervertebral discs (IVDs) in medical images is crucial for assessing spine-related disorders, such as osteoporosis, vertebral fractures, or IVD herniation. We present HCA-Net, a novel contextual attention network architecture for semantic labeling of IVDs, with a special focus on exploiting prior geometric information. Our approach excels at processing features across different scales and effectively consolidating them to capture the intricate spatial relationships within the spinal cord. To achieve this, HCA-Net models IVD labeling as a pose estimation problem, aiming to minimize the discrepancy between each predicted IVD location and its corresponding actual joint location. In addition, we introduce a skeletal loss term to reinforce the model's geometric dependence on the spine. This loss function is designed to constrain the model's predictions to a range that matches the general structure of the human vertebral skeleton. As a result, the network learns to reduce the occurrence of false predictions and adaptively improves the accuracy of IVD location estimation. Through extensive experimental evaluation on multi-center spine datasets, our approach consistently outperforms previous state-of-the-art methods on both MRI T1w and T2w modalities. The codebase is accessible to the public on \href{https://github.com/xmindflow/HCA-Net}{GitHub}.
Foundational Models in Medical Imaging: A Comprehensive Survey and Future Vision
Oct 28, 2023



Foundation models, large-scale, pre-trained deep-learning models adapted to a wide range of downstream tasks have gained significant interest lately in various deep-learning problems undergoing a paradigm shift with the rise of these models. Trained on large-scale dataset to bridge the gap between different modalities, foundation models facilitate contextual reasoning, generalization, and prompt capabilities at test time. The predictions of these models can be adjusted for new tasks by augmenting the model input with task-specific hints called prompts without requiring extensive labeled data and retraining. Capitalizing on the advances in computer vision, medical imaging has also marked a growing interest in these models. To assist researchers in navigating this direction, this survey intends to provide a comprehensive overview of foundation models in the domain of medical imaging. Specifically, we initiate our exploration by providing an exposition of the fundamental concepts forming the basis of foundation models. Subsequently, we offer a methodical taxonomy of foundation models within the medical domain, proposing a classification system primarily structured around training strategies, while also incorporating additional facets such as application domains, imaging modalities, specific organs of interest, and the algorithms integral to these models. Furthermore, we emphasize the practical use case of some selected approaches and then discuss the opportunities, applications, and future directions of these large-scale pre-trained models, for analyzing medical images. In the same vein, we address the prevailing challenges and research pathways associated with foundational models in medical imaging. These encompass the areas of interpretability, data management, computational requirements, and the nuanced issue of contextual comprehension.
Implicit Neural Representation in Medical Imaging: A Comparative Survey
Jul 30, 2023



Implicit neural representations (INRs) have gained prominence as a powerful paradigm in scene reconstruction and computer graphics, demonstrating remarkable results. By utilizing neural networks to parameterize data through implicit continuous functions, INRs offer several benefits. Recognizing the potential of INRs beyond these domains, this survey aims to provide a comprehensive overview of INR models in the field of medical imaging. In medical settings, numerous challenging and ill-posed problems exist, making INRs an attractive solution. The survey explores the application of INRs in various medical imaging tasks, such as image reconstruction, segmentation, registration, novel view synthesis, and compression. It discusses the advantages and limitations of INRs, highlighting their resolution-agnostic nature, memory efficiency, ability to avoid locality biases, and differentiability, enabling adaptation to different tasks. Furthermore, the survey addresses the challenges and considerations specific to medical imaging data, such as data availability, computational complexity, and dynamic clinical scene analysis. It also identifies future research directions and opportunities, including integration with multi-modal imaging, real-time and interactive systems, and domain adaptation for clinical decision support. To facilitate further exploration and implementation of INRs in medical image analysis, we have provided a compilation of cited studies along with their available open-source implementations on \href{https://github.com/mindflow-institue/Awesome-Implicit-Neural-Representations-in-Medical-imaging}. Finally, we aim to consistently incorporate the most recent and relevant papers regularly.