 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCENet: Context Enhancement Network for Medical Image Segmentation
May 23, 2025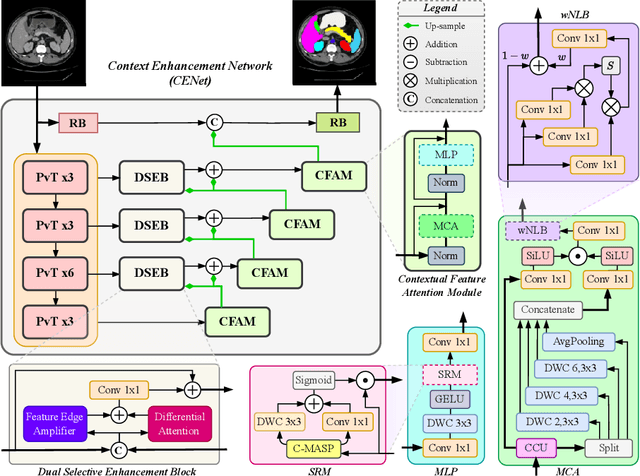
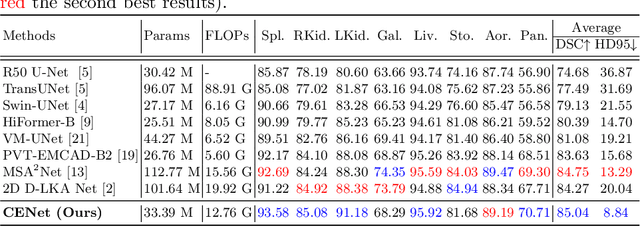
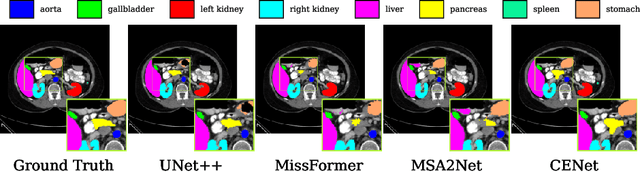
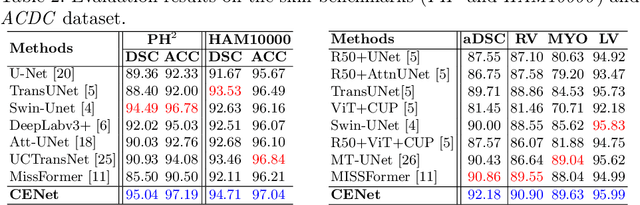
Medical image segmentation, particularly in multi-domain scenarios, requires precise preservation of anatomical structures across diverse representations. While deep learning has advanced this field, existing models often struggle with accurate boundary representation, variability in organ morphology, and information loss during downsampling, limiting their accuracy and robustness. To address these challenges, we propose the Context Enhancement Network (CENet), a novel segmentation framework featuring two key innovations. First, the Dual Selective Enhancement Block (DSEB) integrated into skip connections enhances boundary details and improves the detection of smaller organs in a context-aware manner. Second, the Context Feature Attention Module (CFAM) in the decoder employs a multi-scale design to maintain spatial integrity, reduce feature redundancy, and mitigate overly enhanced representations. Extensive evaluations on both radiology and dermoscopic datasets demonstrate that CENet outperforms state-of-the-art (SOTA) methods in multi-organ segmentation and boundary detail preservation, offering a robust and accurate solution for complex medical image analysis tasks. The code is publicly available at https://github.com/xmindflow/cenet.
MSA$^2$Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation
Aug 03, 2024Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSA$^2$Net, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSA$^2$Net outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at https://github.com/xmindflow/MSA-2Net.
MSA2Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation
Jul 31, 2024Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSA2Net, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSA2Net outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at https://github.com/xmindflow/MSA-2Net.
Computation-Efficient Era: A Comprehensive Survey of State Space Models in Medical Image Analysis
Jun 05, 2024



Sequence modeling plays a vital role across various domains, with recurrent neural networks being historically the predominant method of performing these tasks. However, the emergence of transformers has altered this paradigm due to their superior performance. Built upon these advances, transformers have conjoined CNNs as two leading foundational models for learning visual representations. However, transformers are hindered by the $\mathcal{O}(N^2)$ complexity of their attention mechanisms, while CNNs lack global receptive fields and dynamic weight allocation. State Space Models (SSMs), specifically the \textit{\textbf{Mamba}} model with selection mechanisms and hardware-aware architecture, have garnered immense interest lately in sequential modeling and visual representation learning, challenging the dominance of transformers by providing infinite context lengths and offering substantial efficiency maintaining linear complexity in the input sequence. Capitalizing on the advances in computer vision, medical imaging has heralded a new epoch with Mamba models. Intending to help researchers navigate the surge, this survey seeks to offer an encyclopedic review of Mamba models in medical imaging. Specifically, we start with a comprehensive theoretical review forming the basis of SSMs, including Mamba architecture and its alternatives for sequence modeling paradigms in this context. Next, we offer a structured classification of Mamba models in the medical field and introduce a diverse categorization scheme based on their application, imaging modalities, and targeted organs. Finally, we summarize key challenges, discuss different future research directions of the SSMs in the medical domain, and propose several directions to fulfill the demands of this field. In addition, we have compiled the studies discussed in this paper along with their open-source implementations on our GitHub repository.
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Mar 28, 2024



Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our \href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}\footnote{\url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.