 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMOS-OCTA: Vessel-Aware Multi-Axis Orthogonal Supervision for Inpainting Motion-Corrupted OCT Angiography Volumes
Feb 01, 2026Handheld Optical Coherence Tomography Angiography (OCTA) enables noninvasive retinal imaging in uncooperative or pediatric subjects, but is highly susceptible to motion artifacts that severely degrade volumetric image quality. Sudden motion during 3D acquisition can lead to unsampled retinal regions across entire B-scans (cross-sectional slices), resulting in blank bands in en face projections. We propose VAMOS-OCTA, a deep learning framework for inpainting motion-corrupted B-scans using vessel-aware multi-axis supervision. We employ a 2.5D U-Net architecture that takes a stack of neighboring B-scans as input to reconstruct a corrupted center B-scan, guided by a novel Vessel-Aware Multi-Axis Orthogonal Supervision (VAMOS) loss. This loss combines vessel-weighted intensity reconstruction with axial and lateral projection consistency, encouraging vascular continuity in native B-scans and across orthogonal planes. Unlike prior work that focuses primarily on restoring the en face MIP, VAMOS-OCTA jointly enhances both cross-sectional B-scan sharpness and volumetric projection accuracy, even under severe motion corruptions. We trained our model on both synthetic and real-world corrupted volumes and evaluated its performance using both perceptual quality and pixel-wise accuracy metrics. VAMOS-OCTA consistently outperforms prior methods, producing reconstructions with sharp capillaries, restored vessel continuity, and clean en face projections. These results demonstrate that multi-axis supervision offers a powerful constraint for restoring motion-degraded 3D OCTA data. Our source code is available at https://github.com/MedICL-VU/VAMOS-OCTA.
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Mar 28, 2024



Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our \href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}\footnote{\url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
Unlocking Fine-Grained Details with Wavelet-based High-Frequency Enhancement in Transformers
Sep 12, 2023Medical image segmentation is a critical task that plays a vital role in diagnosis, treatment planning, and disease monitoring. Accurate segmentation of anatomical structures and abnormalities from medical images can aid in the early detection and treatment of various diseases. In this paper, we address the local feature deficiency of the Transformer model by carefully re-designing the self-attention map to produce accurate dense prediction in medical images. To this end, we first apply the wavelet transformation to decompose the input feature map into low-frequency (LF) and high-frequency (HF) subbands. The LF segment is associated with coarse-grained features while the HF components preserve fine-grained features such as texture and edge information. Next, we reformulate the self-attention operation using the efficient Transformer to perform both spatial and context attention on top of the frequency representation. Furthermore, to intensify the importance of the boundary information, we impose an additional attention map by creating a Gaussian pyramid on top of the HF components. Moreover, we propose a multi-scale context enhancement block within skip connections to adaptively model inter-scale dependencies to overcome the semantic gap among stages of the encoder and decoder modules. Throughout comprehensive experiments, we demonstrate the effectiveness of our strategy on multi-organ and skin lesion segmentation benchmarks. The implementation code will be available upon acceptance. \href{https://github.com/mindflow-institue/WaveFormer}{GitHub}.
* Accepted in MICCAI 2023 workshop MLMI
Beyond Self-Attention: Deformable Large Kernel Attention for Medical Image Segmentation
Aug 31, 2023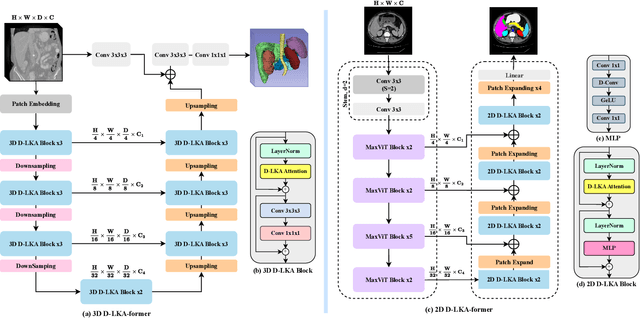
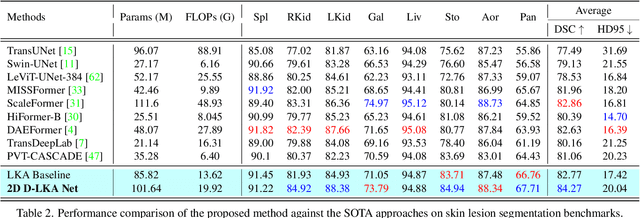
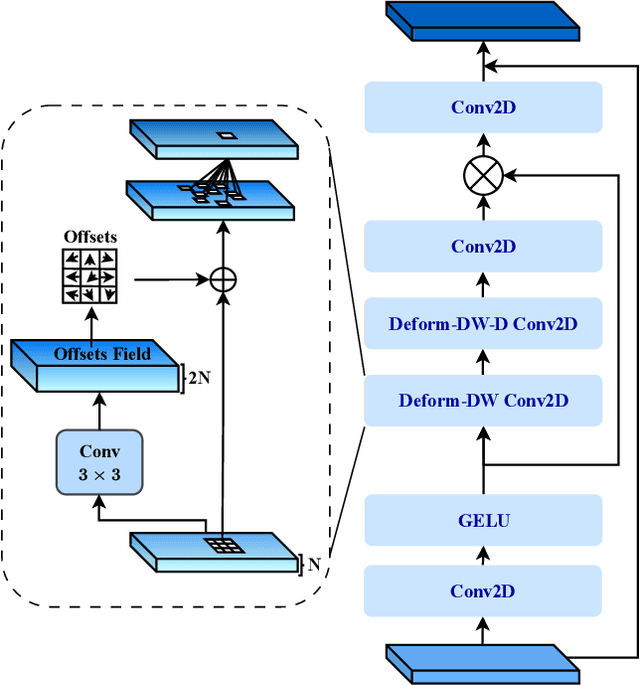

Medical image segmentation has seen significant improvements with transformer models, which excel in grasping far-reaching contexts and global contextual information. However, the increasing computational demands of these models, proportional to the squared token count, limit their depth and resolution capabilities. Most current methods process D volumetric image data slice-by-slice (called pseudo 3D), missing crucial inter-slice information and thus reducing the model's overall performance. To address these challenges, we introduce the concept of \textbf{Deformable Large Kernel Attention (D-LKA Attention)}, a streamlined attention mechanism employing large convolution kernels to fully appreciate volumetric context. This mechanism operates within a receptive field akin to self-attention while sidestepping the computational overhead. Additionally, our proposed attention mechanism benefits from deformable convolutions to flexibly warp the sampling grid, enabling the model to adapt appropriately to diverse data patterns. We designed both 2D and 3D adaptations of the D-LKA Attention, with the latter excelling in cross-depth data understanding. Together, these components shape our novel hierarchical Vision Transformer architecture, the \textit{D-LKA Net}. Evaluations of our model against leading methods on popular medical segmentation datasets (Synapse, NIH Pancreas, and Skin lesion) demonstrate its superior performance. Our code implementation is publicly available at the: https://github.com/mindflow-institue/deformableLKA
Laplacian-Former: Overcoming the Limitations of Vision Transformers in Local Texture Detection
Aug 31, 2023Vision Transformer (ViT) models have demonstrated a breakthrough in a wide range of computer vision tasks. However, compared to the Convolutional Neural Network (CNN) models, it has been observed that the ViT models struggle to capture high-frequency components of images, which can limit their ability to detect local textures and edge information. As abnormalities in human tissue, such as tumors and lesions, may greatly vary in structure, texture, and shape, high-frequency information such as texture is crucial for effective semantic segmentation tasks. To address this limitation in ViT models, we propose a new technique, Laplacian-Former, that enhances the self-attention map by adaptively re-calibrating the frequency information in a Laplacian pyramid. More specifically, our proposed method utilizes a dual attention mechanism via efficient attention and frequency attention while the efficient attention mechanism reduces the complexity of self-attention to linear while producing the same output, selectively intensifying the contribution of shape and texture features. Furthermore, we introduce a novel efficient enhancement multi-scale bridge that effectively transfers spatial information from the encoder to the decoder while preserving the fundamental features. We demonstrate the efficacy of Laplacian-former on multi-organ and skin lesion segmentation tasks with +1.87\% and +0.76\% dice scores compared to SOTA approaches, respectively. Our implementation is publically available at https://github.com/mindflow-institue/Laplacian-Former
Enhancing Medical Image Segmentation with TransCeption: A Multi-Scale Feature Fusion Approach
Jan 25, 2023While CNN-based methods have been the cornerstone of medical image segmentation due to their promising performance and robustness, they suffer from limitations in capturing long-range dependencies. Transformer-based approaches are currently prevailing since they enlarge the reception field to model global contextual correlation. To further extract rich representations, some extensions of the U-Net employ multi-scale feature extraction and fusion modules and obtain improved performance. Inspired by this idea, we propose TransCeption for medical image segmentation, a pure transformer-based U-shape network featured by incorporating the inception-like module into the encoder and adopting a contextual bridge for better feature fusion. The design proposed in this work is based on three core principles: (1) The patch merging module in the encoder is redesigned with ResInception Patch Merging (RIPM). Multi-branch transformer (MB transformer) adopts the same number of branches as the outputs of RIPM. Combining the two modules enables the model to capture a multi-scale representation within a single stage. (2) We construct an Intra-stage Feature Fusion (IFF) module following the MB transformer to enhance the aggregation of feature maps from all the branches and particularly focus on the interaction between the different channels of all the scales. (3) In contrast to a bridge that only contains token-wise self-attention, we propose a Dual Transformer Bridge that also includes channel-wise self-attention to exploit correlations between scales at different stages from a dual perspective. Extensive experiments on multi-organ and skin lesion segmentation tasks present the superior performance of TransCeption compared to previous work. The code is publicly available at \url{https://github.com/mindflow-institue/TransCeption}.
Advances in Medical Image Analysis with Vision Transformers: A Comprehensive Review
Jan 10, 2023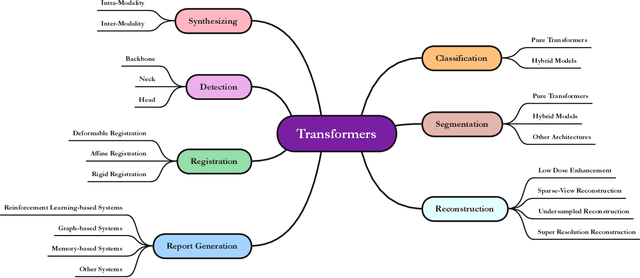
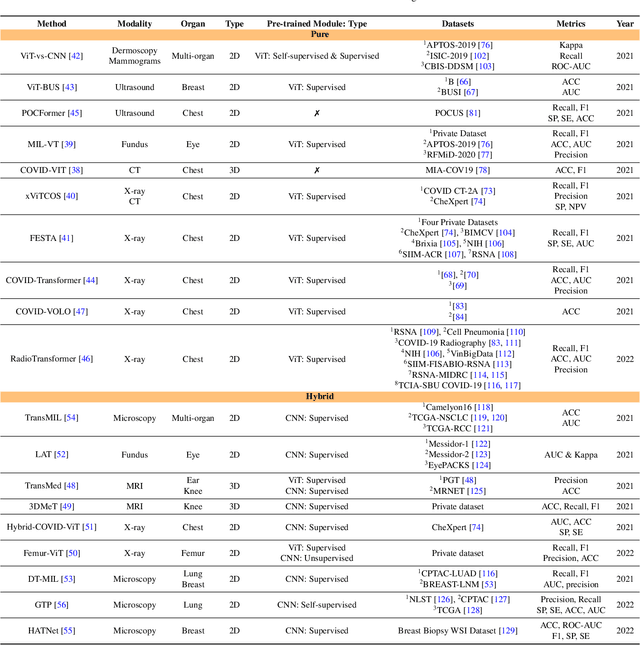
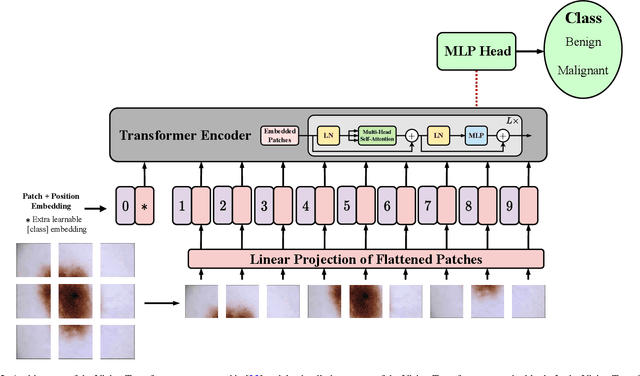
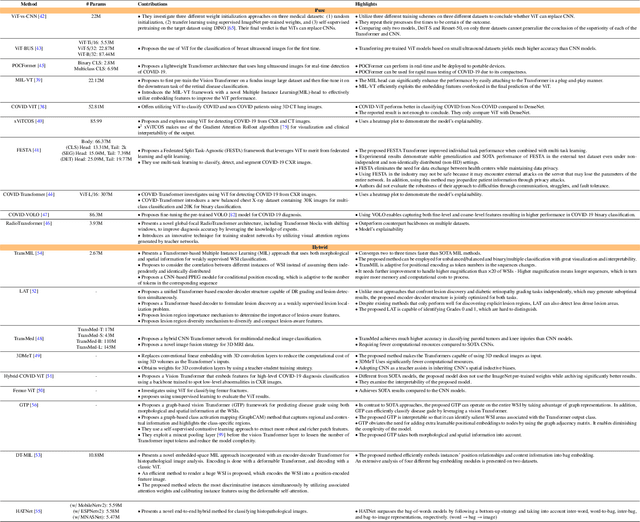
The remarkable performance of the Transformer architecture in natural language processing has recently also triggered broad interest in Computer Vision. Among other merits, Transformers are witnessed as capable of learning long-range dependencies and spatial correlations, which is a clear advantage over convolutional neural networks (CNNs), which have been the de facto standard in Computer Vision problems so far. Thus, Transformers have become an integral part of modern medical image analysis. In this review, we provide an encyclopedic review of the applications of Transformers in medical imaging. Specifically, we present a systematic and thorough review of relevant recent Transformer literature for different medical image analysis tasks, including classification, segmentation, detection, registration, synthesis, and clinical report generation. For each of these applications, we investigate the novelty, strengths and weaknesses of the different proposed strategies and develop taxonomies highlighting key properties and contributions. Further, if applicable, we outline current benchmarks on different datasets. Finally, we summarize key challenges and discuss different future research directions. In addition, we have provided cited papers with their corresponding implementations in https://github.com/mindflow-institue/Awesome-Transformer.
DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
Jan 09, 2023
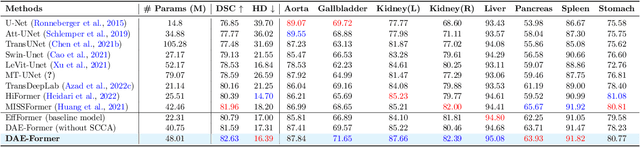
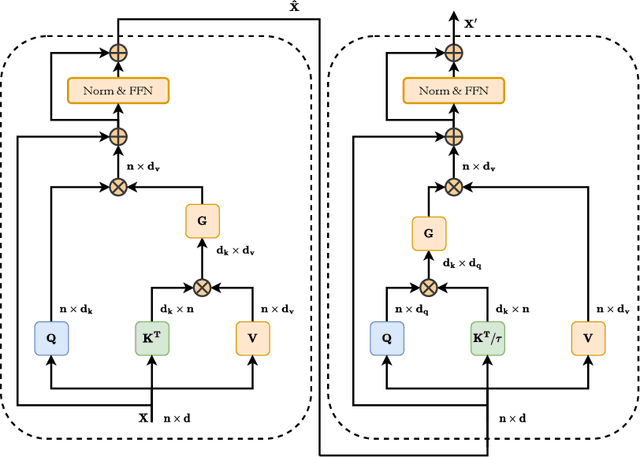

Transformers have recently gained attention in the computer vision domain due to their ability to model long-range dependencies. However, the self-attention mechanism, which is the core part of the Transformer model, usually suffers from quadratic computational complexity with respect to the number of tokens. Many architectures attempt to reduce model complexity by limiting the self-attention mechanism to local regions or by redesigning the tokenization process. In this paper, we propose DAE-Former, a novel method that seeks to provide an alternative perspective by efficiently designing the self-attention mechanism. More specifically, we reformulate the self-attention mechanism to capture both spatial and channel relations across the whole feature dimension while staying computationally efficient. Furthermore, we redesign the skip connection path by including the cross-attention module to ensure the feature reusability and enhance the localization power. Our method outperforms state-of-the-art methods on multi-organ cardiac and skin lesion segmentation datasets without requiring pre-training weights. The code is publicly available at https://github.com/mindflow-institue/DAEFormer.
Medical Image Segmentation Review: The success of U-Net
Nov 27, 2022



Automatic medical image segmentation is a crucial topic in the medical domain and successively a critical counterpart in the computer-aided diagnosis paradigm. U-Net is the most widespread image segmentation architecture due to its flexibility, optimized modular design, and success in all medical image modalities. Over the years, the U-Net model achieved tremendous attention from academic and industrial researchers. Several extensions of this network have been proposed to address the scale and complexity created by medical tasks. Addressing the deficiency of the naive U-Net model is the foremost step for vendors to utilize the proper U-Net variant model for their business. Having a compendium of different variants in one place makes it easier for builders to identify the relevant research. Also, for ML researchers it will help them understand the challenges of the biological tasks that challenge the model. To address this, we discuss the practical aspects of the U-Net model and suggest a taxonomy to categorize each network variant. Moreover, to measure the performance of these strategies in a clinical application, we propose fair evaluations of some unique and famous designs on well-known datasets. We provide a comprehensive implementation library with trained models for future research. In addition, for ease of future studies, we created an online list of U-Net papers with their possible official implementation. All information is gathered in https://github.com/NITR098/Awesome-U-Net repository.
Diffusion Models for Medical Image Analysis: A Comprehensive Survey
Nov 14, 2022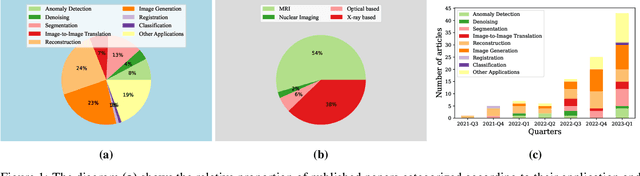
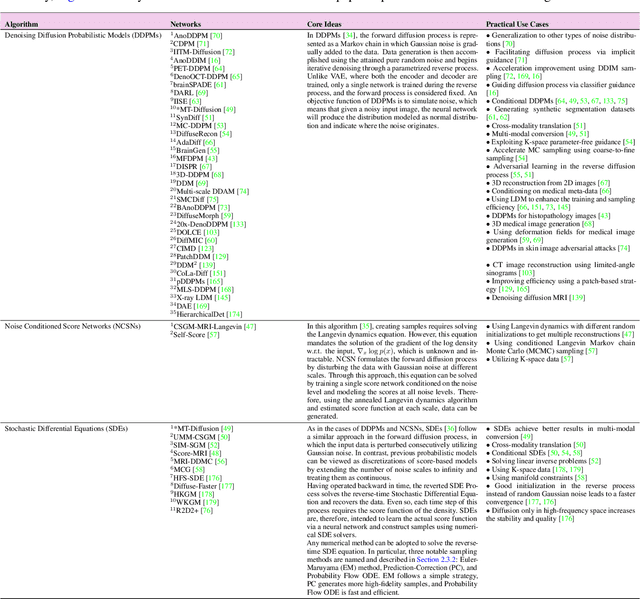
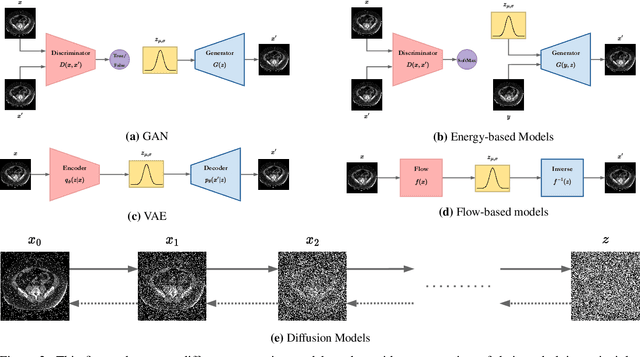
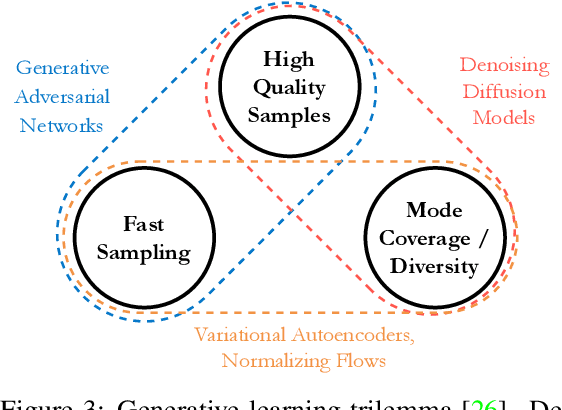
Denoising diffusion models, a class of generative models, have garnered immense interest lately in various deep-learning problems. A diffusion probabilistic model defines a forward diffusion stage where the input data is gradually perturbed over several steps by adding Gaussian noise and then learns to reverse the diffusion process to retrieve the desired noise-free data from noisy data samples. Diffusion models are widely appreciated for their strong mode coverage and quality of the generated samples despite their known computational burdens. Capitalizing on the advances in computer vision, the field of medical imaging has also observed a growing interest in diffusion models. To help the researcher navigate this profusion, this survey intends to provide a comprehensive overview of diffusion models in the discipline of medical image analysis. Specifically, we introduce the solid theoretical foundation and fundamental concepts behind diffusion models and the three generic diffusion modelling frameworks: diffusion probabilistic models, noise-conditioned score networks, and stochastic differential equations. Then, we provide a systematic taxonomy of diffusion models in the medical domain and propose a multi-perspective categorization based on their application, imaging modality, organ of interest, and algorithms. To this end, we cover extensive applications of diffusion models in the medical domain. Furthermore, we emphasize the practical use case of some selected approaches, and then we discuss the limitations of the diffusion models in the medical domain and propose several directions to fulfill the demands of this field. Finally, we gather the overviewed studies with their available open-source implementations at https://github.com/amirhossein-kz/Awesome-Diffusion-Models-in-Medical-Imaging.