 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering
Apr 02, 2026We introduce STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration), a structured reinforcement learning framework for video question answering. While group-based policy optimization methods have shown promise in large multimodal models, they often suffer from low reward variance when responses exhibit similar correctness, leading to weak or unstable advantage estimates. STRIVE addresses this limitation by constructing multiple spatiotemporal variants of each input video and performing joint normalization across both textual generations and visual variants. By expanding group comparisons beyond linguistic diversity to structured visual perturbations, STRIVE enriches reward signals and promotes more stable and informative policy updates. To ensure exploration remains semantically grounded, we introduce an importance-aware sampling mechanism that prioritizes frames most relevant to the input question while preserving temporal coverage. This design encourages robust reasoning across complementary visual perspectives rather than overfitting to a single spatiotemporal configuration. Experiments on six challenging video reasoning benchmarks including VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest demonstrate consistent improvements over strong reinforcement learning baselines across multiple large multimodal models. Our results highlight the role of structured spatiotemporal exploration as a principled mechanism for stabilizing multimodal reinforcement learning and improving video reasoning performance.
DocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025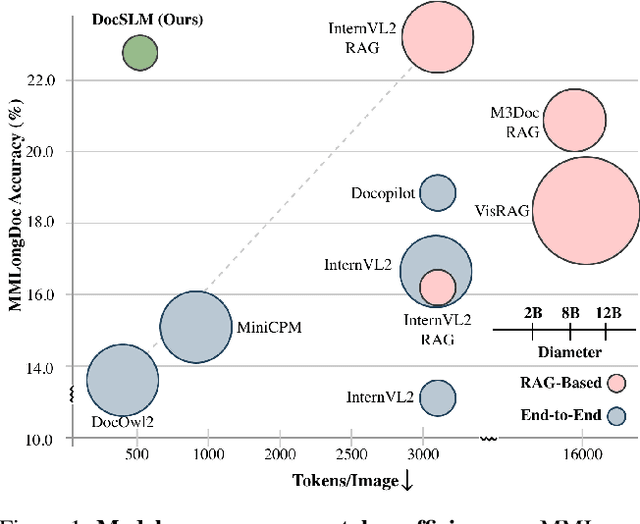

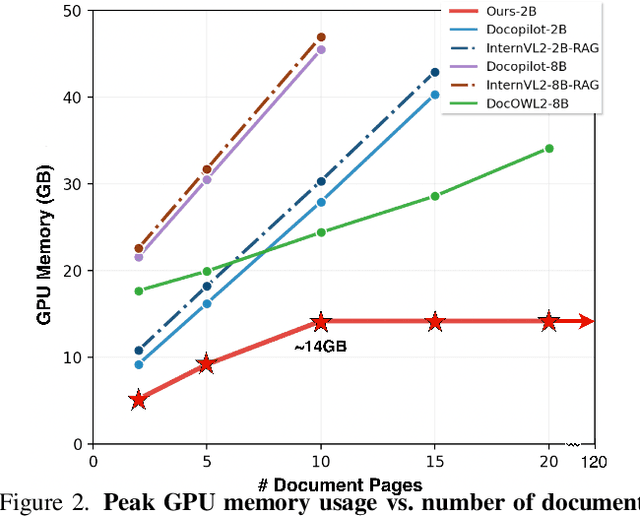
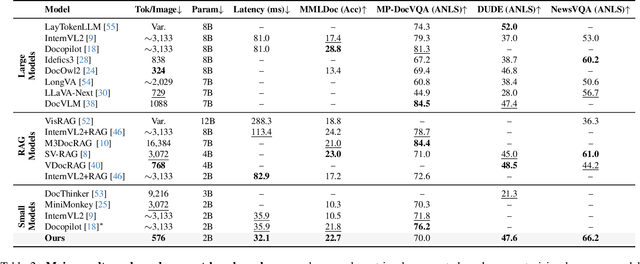
Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
Enhancing Temporal Understanding in Video-LLMs through Stacked Temporal Attention in Vision Encoders
Oct 29, 2025Despite significant advances in Multimodal Large Language Models (MLLMs), understanding complex temporal dynamics in videos remains a major challenge. Our experiments show that current Video Large Language Model (Video-LLM) architectures have critical limitations in temporal understanding, struggling with tasks that require detailed comprehension of action sequences and temporal progression. In this work, we propose a Video-LLM architecture that introduces stacked temporal attention modules directly within the vision encoder. This design incorporates a temporal attention in vision encoder, enabling the model to better capture the progression of actions and the relationships between frames before passing visual tokens to the LLM. Our results show that this approach significantly improves temporal reasoning and outperforms existing models in video question answering tasks, specifically in action recognition. We improve on benchmarks including VITATECS, MVBench, and Video-MME by up to +5.5%. By enhancing the vision encoder with temporal structure, we address a critical gap in video understanding for Video-LLMs. Project page and code are available at: https://alirasekh.github.io/STAVEQ2/.
Multilingual Routing in Mixture-of-Experts
Oct 06, 2025Mixture-of-Experts (MoE) architectures have become the key to scaling modern LLMs, yet little is understood about how their sparse routing dynamics respond to multilingual data. In this work, we analyze expert routing patterns using parallel multilingual datasets and present highly interpretable layer-wise phenomena. We find that MoE models route tokens in language-specific ways in the early and late decoder layers but exhibit significant cross-lingual routing alignment in middle layers, mirroring parameter-sharing trends observed in dense LLMs. In particular, we reveal a clear, strong correlation between a model's performance in a given language and how similarly its tokens are routed to English in these layers. Extending beyond correlation, we explore inference-time interventions that induce higher cross-lingual routing alignment. We introduce a method that steers the router by promoting middle-layer task experts frequently activated in English, and it successfully increases multilingual performance. These 1-2% gains are remarkably consistent across two evaluation tasks, three models, and 15+ languages, especially given that these simple interventions override routers of extensively trained, state-of-the-art LLMs. In comparison, interventions outside of the middle layers or targeting multilingual-specialized experts only yield performance degradation. Altogether, we present numerous findings that explain how MoEs process non-English text and demonstrate that generalization is limited by the model's ability to leverage language-universal experts in all languages.
Steering MoE LLMs via Expert (De)Activation
Sep 11, 2025



Mixture-of-Experts (MoE) in Large Language Models (LLMs) routes each token through a subset of specialized Feed-Forward Networks (FFN), known as experts. We present SteerMoE, a framework for steering MoE models by detecting and controlling behavior-linked experts. Our detection method identifies experts with distinct activation patterns across paired inputs exhibiting contrasting behaviors. By selectively (de)activating such experts during inference, we control behaviors like faithfulness and safety without retraining or modifying weights. Across 11 benchmarks and 6 LLMs, our steering raises safety by up to +20% and faithfulness by +27%. In adversarial attack mode, it drops safety by -41% alone, and -100% when combined with existing jailbreak methods, bypassing all safety guardrails and exposing a new dimension of alignment faking hidden within experts.
Collapse of Dense Retrievers: Short, Early, and Literal Biases Outranking Factual Evidence
Mar 06, 2025



Dense retrieval models are commonly used in Information Retrieval (IR) applications, such as Retrieval-Augmented Generation (RAG). Since they often serve as the first step in these systems, their robustness is critical to avoid failures. In this work, by repurposing a relation extraction dataset (e.g. Re-DocRED), we design controlled experiments to quantify the impact of heuristic biases, such as favoring shorter documents, in retrievers like Dragon+ and Contriever. Our findings reveal significant vulnerabilities: retrievers often rely on superficial patterns like over-prioritizing document beginnings, shorter documents, repeated entities, and literal matches. Additionally, they tend to overlook whether the document contains the query's answer, lacking deep semantic understanding. Notably, when multiple biases combine, models exhibit catastrophic performance degradation, selecting the answer-containing document in less than 3% of cases over a biased document without the answer. Furthermore, we show that these biases have direct consequences for downstream applications like RAG, where retrieval-preferred documents can mislead LLMs, resulting in a 34% performance drop than not providing any documents at all.
DeltaLLM: Compress LLMs with Low-Rank Deltas between Shared Weights
Jan 30, 2025We introduce DeltaLLM, a new post-training compression technique to reduce the memory footprint of LLMs. We propose an alternative way of structuring LLMs with weight sharing between layers in subsequent Transformer blocks, along with additional low-rank difference matrices between them. For training, we adopt the progressing module replacement method and show that the lightweight training of the low-rank modules with approximately 30M-40M tokens is sufficient to achieve performance on par with LLMs of comparable sizes trained from scratch. We release the resultant models, DeltaLLAMA and DeltaPHI, with a 12% parameter reduction, retaining 90% of the performance of the base Llama and Phi models on common knowledge and reasoning benchmarks. Our method also outperforms compression techniques JointDrop, LaCo, ShortGPT and SliceGPT with the same number of parameters removed. For example, DeltaPhi 2.9B with a 24% reduction achieves similar average zero-shot accuracies as recovery fine-tuned SlicedPhi 3.3B with a 12% reduction, despite being approximately 400M parameters smaller with no fine-tuning applied. This work provides new insights into LLM architecture design and compression methods when storage space is critical.
MRAG-Bench: Vision-Centric Evaluation for Retrieval-Augmented Multimodal Models
Oct 10, 2024Existing multimodal retrieval benchmarks primarily focus on evaluating whether models can retrieve and utilize external textual knowledge for question answering. However, there are scenarios where retrieving visual information is either more beneficial or easier to access than textual data. In this paper, we introduce a multimodal retrieval-augmented generation benchmark, MRAG-Bench, in which we systematically identify and categorize scenarios where visually augmented knowledge is better than textual knowledge, for instance, more images from varying viewpoints. MRAG-Bench consists of 16,130 images and 1,353 human-annotated multiple-choice questions across 9 distinct scenarios. With MRAG-Bench, we conduct an evaluation of 10 open-source and 4 proprietary large vision-language models (LVLMs). Our results show that all LVLMs exhibit greater improvements when augmented with images compared to textual knowledge, confirming that MRAG-Bench is vision-centric. Additionally, we conduct extensive analysis with MRAG-Bench, which offers valuable insights into retrieval-augmented LVLMs. Notably, the top-performing model, GPT-4o, faces challenges in effectively leveraging retrieved knowledge, achieving only a 5.82% improvement with ground-truth information, in contrast to a 33.16% improvement observed in human participants. These findings highlight the importance of MRAG-Bench in encouraging the community to enhance LVLMs' ability to utilize retrieved visual knowledge more effectively.
Evaluating Human Alignment and Model Faithfulness of LLM Rationale
Jun 28, 2024



We study how well large language models (LLMs) explain their generations with rationales -- a set of tokens extracted from the input texts that reflect the decision process of LLMs. We examine LLM rationales extracted with two methods: 1) attribution-based methods that use attention or gradients to locate important tokens, and 2) prompting-based methods that guide LLMs to extract rationales using prompts. Through extensive experiments, we show that prompting-based rationales align better with human-annotated rationales than attribution-based rationales, and demonstrate reasonable alignment with humans even when model performance is poor. We additionally find that the faithfulness limitations of prompting-based methods, which are identified in previous work, may be linked to their collapsed predictions. By fine-tuning these models on the corresponding datasets, both prompting and attribution methods demonstrate improved faithfulness. Our study sheds light on more rigorous and fair evaluations of LLM rationales, especially for prompting-based ones.
Occlusion Handling in 3D Human Pose Estimation with Perturbed Positional Encoding
May 27, 2024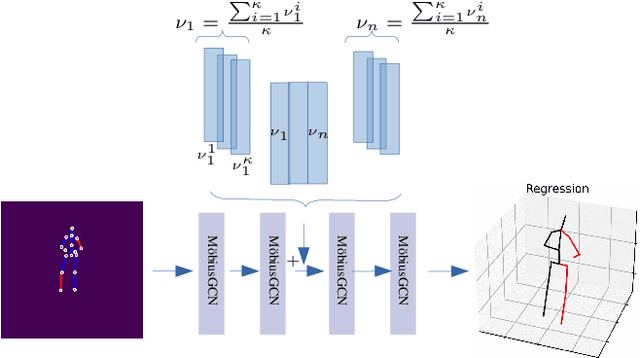
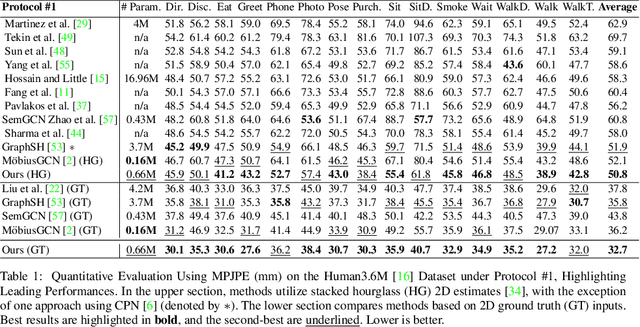
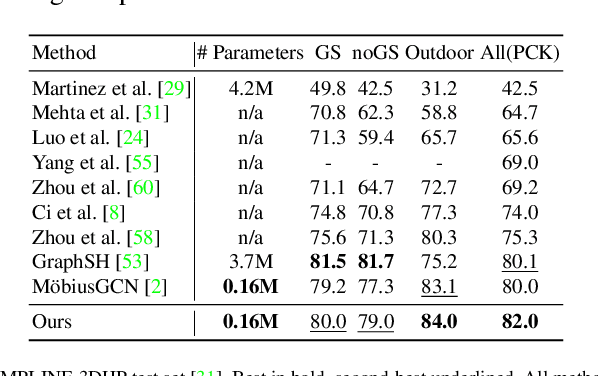
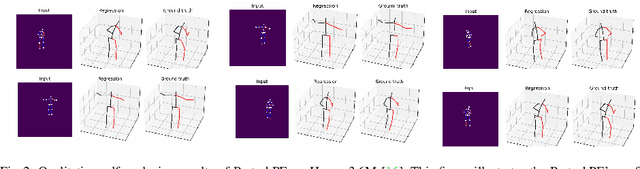
Understanding human behavior fundamentally relies on accurate 3D human pose estimation. Graph Convolutional Networks (GCNs) have recently shown promising advancements, delivering state-of-the-art performance with rather lightweight architectures. In the context of graph-structured data, leveraging the eigenvectors of the graph Laplacian matrix for positional encoding is effective. Yet, the approach does not specify how to handle scenarios where edges in the input graph are missing. To this end, we propose a novel positional encoding technique, PerturbPE, that extracts consistent and regular components from the eigenbasis. Our method involves applying multiple perturbations and taking their average to extract the consistent and regular component from the eigenbasis. PerturbPE leverages the Rayleigh-Schrodinger Perturbation Theorem (RSPT) for calculating the perturbed eigenvectors. Employing this labeling technique enhances the robustness and generalizability of the model. Our results support our theoretical findings, e.g. our experimental analysis observed a performance enhancement of up to $12\%$ on the Human3.6M dataset in instances where occlusion resulted in the absence of one edge. Furthermore, our novel approach significantly enhances performance in scenarios where two edges are missing, setting a new benchmark for state-of-the-art.