 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaLLM: Compress LLMs with Low-Rank Deltas between Shared Weights
Jan 30, 2025We introduce DeltaLLM, a new post-training compression technique to reduce the memory footprint of LLMs. We propose an alternative way of structuring LLMs with weight sharing between layers in subsequent Transformer blocks, along with additional low-rank difference matrices between them. For training, we adopt the progressing module replacement method and show that the lightweight training of the low-rank modules with approximately 30M-40M tokens is sufficient to achieve performance on par with LLMs of comparable sizes trained from scratch. We release the resultant models, DeltaLLAMA and DeltaPHI, with a 12% parameter reduction, retaining 90% of the performance of the base Llama and Phi models on common knowledge and reasoning benchmarks. Our method also outperforms compression techniques JointDrop, LaCo, ShortGPT and SliceGPT with the same number of parameters removed. For example, DeltaPhi 2.9B with a 24% reduction achieves similar average zero-shot accuracies as recovery fine-tuned SlicedPhi 3.3B with a 12% reduction, despite being approximately 400M parameters smaller with no fine-tuning applied. This work provides new insights into LLM architecture design and compression methods when storage space is critical.
KBLaM: Knowledge Base augmented Language Model
Oct 14, 2024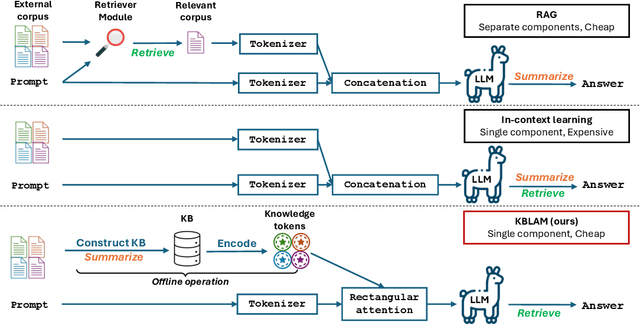
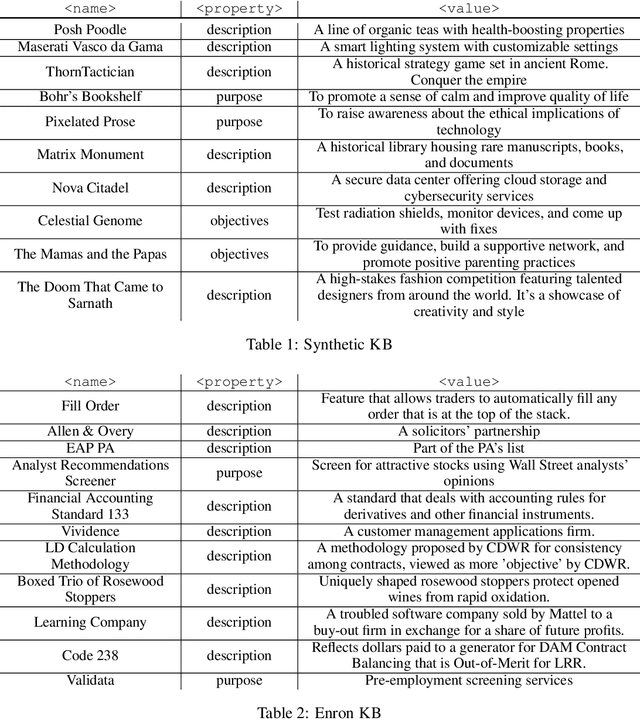
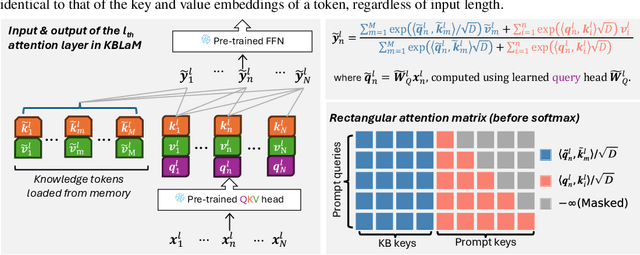
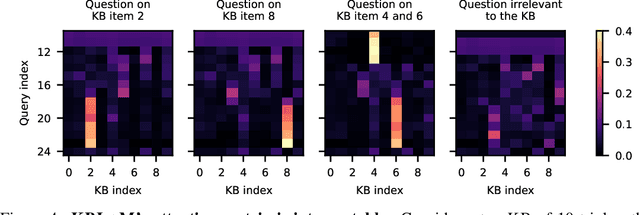
In this paper, we propose Knowledge Base augmented Language Model (KBLaM), a new method for augmenting Large Language Models (LLMs) with external knowledge. KBLaM works with a knowledge base (KB) constructed from a corpus of documents, transforming each piece of knowledge in the KB into continuous key-value vector pairs via pre-trained sentence encoders with linear adapters and integrating them into pre-trained LLMs via a specialized rectangular attention mechanism. Unlike Retrieval-Augmented Generation, KBLaM eliminates external retrieval modules, and unlike in-context learning, its computational overhead scales linearly with KB size rather than quadratically. Our approach enables integrating a large KB of more than 10K triples into an 8B pre-trained LLM of only 8K context window on one single A100 80GB GPU and allows for dynamic updates without model fine-tuning or retraining. Experiments demonstrate KBLaM's effectiveness in various tasks, including question-answering and open-ended reasoning, while providing interpretable insights into its use of the augmented knowledge.
Team MTS @ AutoMin 2021: An Overview of Existing Summarization Approaches and Comparison to Unsupervised Summarization Techniques
Oct 04, 2024Remote communication through video or audio conferences has become more popular than ever because of the worldwide pandemic. These events, therefore, have provoked the development of systems for automatic minuting of spoken language leading to AutoMin 2021 challenge. The following paper illustrates the results of the research that team MTS has carried out while participating in the Automatic Minutes challenge. In particular, in this paper we analyze existing approaches to text and speech summarization, propose an unsupervised summarization technique based on clustering and provide a pipeline that includes an adapted automatic speech recognition block able to run on real-life recordings. The proposed unsupervised technique outperforms pre-trained summarization models on the automatic minuting task with Rouge 1, Rouge 2 and Rouge L values of 0.21, 0.02 and 0.2 on the dev set, with Rouge 1, Rouge 2, Rouge L, Adequacy, Grammatical correctness and Fluency values of 0.180, 0.035, 0.098, 1.857, 2.304, 1.911 on the test set accordingly
Structured Entity Extraction Using Large Language Models
Feb 06, 2024

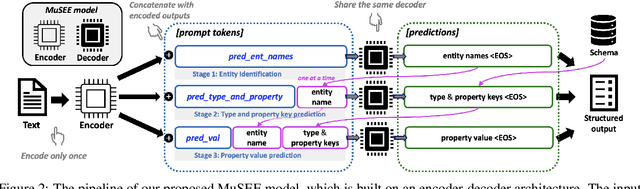

Recent advances in machine learning have significantly impacted the field of information extraction, with Large Language Models (LLMs) playing a pivotal role in extracting structured information from unstructured text. This paper explores the challenges and limitations of current methodologies in structured entity extraction and introduces a novel approach to address these issues. We contribute to the field by first introducing and formalizing the task of Structured Entity Extraction (SEE), followed by proposing Approximate Entity Set OverlaP (AESOP) Metric designed to appropriately assess model performance on this task. Later, we propose a new model that harnesses the power of LLMs for enhanced effectiveness and efficiency through decomposing the entire extraction task into multiple stages. Quantitative evaluation and human side-by-side evaluation confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.