 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing User Profiles via Contextual Bandits for Retrieval-Augmented LLM Personalization
Jan 17, 2026Large Language Models (LLMs) excel at general-purpose tasks, yet adapting their responses to individual users remains challenging. Retrieval augmentation provides a lightweight alternative to fine-tuning by conditioning LLMs on user history records, and existing approaches typically select these records based on semantic relevance. We argue that relevance serves as an unreliable proxy for utility: a record may be semantically similar to a query yet fail to improve generation quality or even degrade it due to redundancy or conflicting information. To bridge this gap, we propose PURPLE, a contextual bandit framework that oPtimizes UseR Profiles for Llm pErsonalization. In contrast to a greedy selection of the most relevant records, PURPLE treats profile construction as a set generation process and utilizes a Plackett-Luce ranking model to capture complex inter-record dependencies. By training with dense feedback provided by the likelihood of the reference response, our method aligns retrieval directly with generation quality. Extensive experiments on nine personalization tasks demonstrate that PURPLE consistently outperforms strong heuristic and retrieval-augmented baselines in both effectiveness and efficiency, establishing a principled and scalable solution for optimizing user profiles.
Audio Prototypical Network For Controllable Music Recommendation
Jul 31, 2025Traditional recommendation systems represent user preferences in dense representations obtained through black-box encoder models. While these models often provide strong recommendation performance, they lack interpretability for users, leaving users unable to understand or control the system's modeling of their preferences. This limitation is especially challenging in music recommendation, where user preferences are highly personal and often evolve based on nuanced qualities like mood, genre, tempo, or instrumentation. In this paper, we propose an audio prototypical network for controllable music recommendation. This network expresses user preferences in terms of prototypes representative of semantically meaningful features pertaining to musical qualities. We show that the model obtains competitive recommendation performance compared to popular baseline models while also providing interpretable and controllable user profiles.
Timing is important: Risk-aware Fund Allocation based on Time-Series Forecasting
May 30, 2025Fund allocation has been an increasingly important problem in the financial domain. In reality, we aim to allocate the funds to buy certain assets within a certain future period. Naive solutions such as prediction-only or Predict-then-Optimize approaches suffer from goal mismatch. Additionally, the introduction of the SOTA time series forecasting model inevitably introduces additional uncertainty in the predicted result. To solve both problems mentioned above, we introduce a Risk-aware Time-Series Predict-and-Allocate (RTS-PnO) framework, which holds no prior assumption on the forecasting models. Such a framework contains three features: (i) end-to-end training with objective alignment measurement, (ii) adaptive forecasting uncertainty calibration, and (iii) agnostic towards forecasting models. The evaluation of RTS-PnO is conducted over both online and offline experiments. For offline experiments, eight datasets from three categories of financial applications are used: Currency, Stock, and Cryptos. RTS-PnO consistently outperforms other competitive baselines. The online experiment is conducted on the Cross-Border Payment business at FiT, Tencent, and an 8.4\% decrease in regret is witnessed when compared with the product-line approach. The code for the offline experiment is available at https://github.com/fuyuanlyu/RTS-PnO.
Counterfactual Multi-player Bandits for Explainable Recommendation Diversification
May 27, 2025Existing recommender systems tend to prioritize items closely aligned with users' historical interactions, inevitably trapping users in the dilemma of ``filter bubble''. Recent efforts are dedicated to improving the diversity of recommendations. However, they mainly suffer from two major issues: 1) a lack of explainability, making it difficult for the system designers to understand how diverse recommendations are generated, and 2) limitations to specific metrics, with difficulty in enhancing non-differentiable diversity metrics. To this end, we propose a \textbf{C}ounterfactual \textbf{M}ulti-player \textbf{B}andits (CMB) method to deliver explainable recommendation diversification across a wide range of diversity metrics. Leveraging a counterfactual framework, our method identifies the factors influencing diversity outcomes. Meanwhile, we adopt the multi-player bandits to optimize the counterfactual optimization objective, making it adaptable to both differentiable and non-differentiable diversity metrics. Extensive experiments conducted on three real-world datasets demonstrate the applicability, effectiveness, and explainability of the proposed CMB.
Understanding 6G through Language Models: A Case Study on LLM-aided Structured Entity Extraction in Telecom Domain
May 20, 2025Knowledge understanding is a foundational part of envisioned 6G networks to advance network intelligence and AI-native network architectures. In this paradigm, information extraction plays a pivotal role in transforming fragmented telecom knowledge into well-structured formats, empowering diverse AI models to better understand network terminologies. This work proposes a novel language model-based information extraction technique, aiming to extract structured entities from the telecom context. The proposed telecom structured entity extraction (TeleSEE) technique applies a token-efficient representation method to predict entity types and attribute keys, aiming to save the number of output tokens and improve prediction accuracy. Meanwhile, TeleSEE involves a hierarchical parallel decoding method, improving the standard encoder-decoder architecture by integrating additional prompting and decoding strategies into entity extraction tasks. In addition, to better evaluate the performance of the proposed technique in the telecom domain, we further designed a dataset named 6GTech, including 2390 sentences and 23747 words from more than 100 6G-related technical publications. Finally, the experiment shows that the proposed TeleSEE method achieves higher accuracy than other baseline techniques, and also presents 5 to 9 times higher sample processing speed.
TEARS: Textual Representations for Scrutable Recommendations
Oct 25, 2024



Traditional recommender systems rely on high-dimensional (latent) embeddings for modeling user-item interactions, often resulting in opaque representations that lack interpretability. Moreover, these systems offer limited control to users over their recommendations. Inspired by recent work, we introduce TExtuAl Representations for Scrutable recommendations (TEARS) to address these challenges. Instead of representing a user's interests through a latent embedding, TEARS encodes them in natural text, providing transparency and allowing users to edit them. To do so, TEARS uses a modern LLM to generate user summaries based on user preferences. We find the summaries capture user preferences uniquely. Using these summaries, we take a hybrid approach where we use an optimal transport procedure to align the summaries' representation with the learned representation of a standard VAE for collaborative filtering. We find this approach can surpass the performance of three popular VAE models while providing user-controllable recommendations. We also analyze the controllability of TEARS through three simulated user tasks to evaluate the effectiveness of a user editing its summary.
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Jul 19, 2024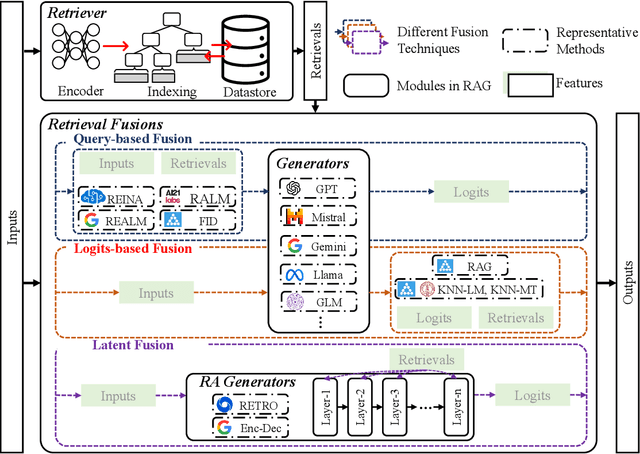
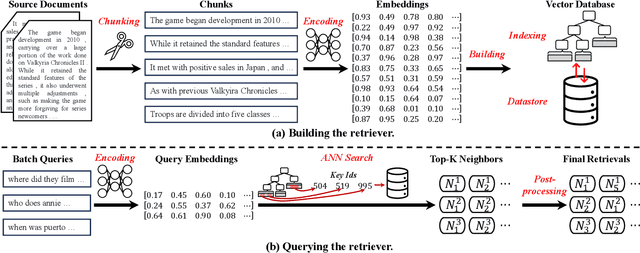
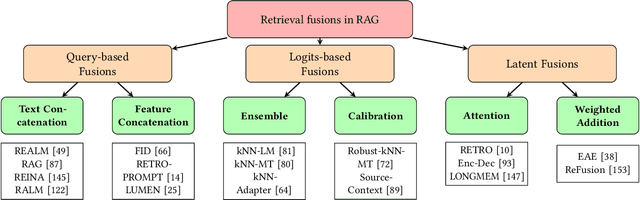
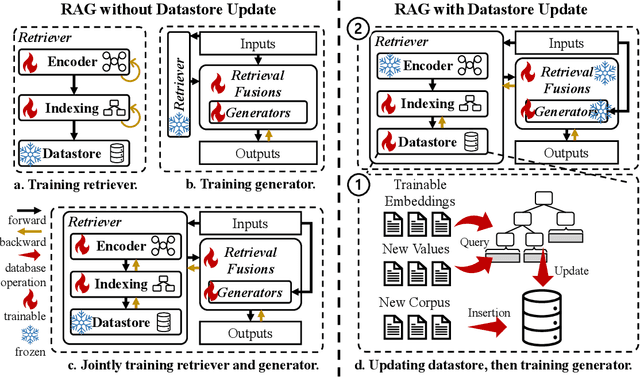
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
Design Editing for Offline Model-based Optimization
May 22, 2024



Offline model-based optimization (MBO) aims to maximize a black-box objective function using only an offline dataset of designs and scores. A prevalent approach involves training a conditional generative model on existing designs and their associated scores, followed by the generation of new designs conditioned on higher target scores. However, these newly generated designs often underperform due to the lack of high-scoring training data. To address this challenge, we introduce a novel method, Design Editing for Offline Model-based Optimization (DEMO), which consists of two phases. In the first phase, termed pseudo-target distribution generation, we apply gradient ascent on the offline dataset using a trained surrogate model, producing a synthetic dataset where the predicted scores serve as new labels. A conditional diffusion model is subsequently trained on this synthetic dataset to capture a pseudo-target distribution, which enhances the accuracy of the conditional diffusion model in generating higher-scoring designs. Nevertheless, the pseudo-target distribution is susceptible to noise stemming from inaccuracies in the surrogate model, consequently predisposing the conditional diffusion model to generate suboptimal designs. We hence propose the second phase, existing design editing, to directly incorporate the high-scoring features from the offline dataset into design generation. In this phase, top designs from the offline dataset are edited by introducing noise, which are subsequently refined using the conditional diffusion model to produce high-scoring designs. Overall, high-scoring designs begin with inheriting high-scoring features from the second phase and are further refined with a more accurate conditional diffusion model in the first phase. Empirical evaluations on 7 offline MBO tasks show that DEMO outperforms various baseline methods.
Large Language Model (LLM) for Telecommunications: A Comprehensive Survey on Principles, Key Techniques, and Opportunities
May 17, 2024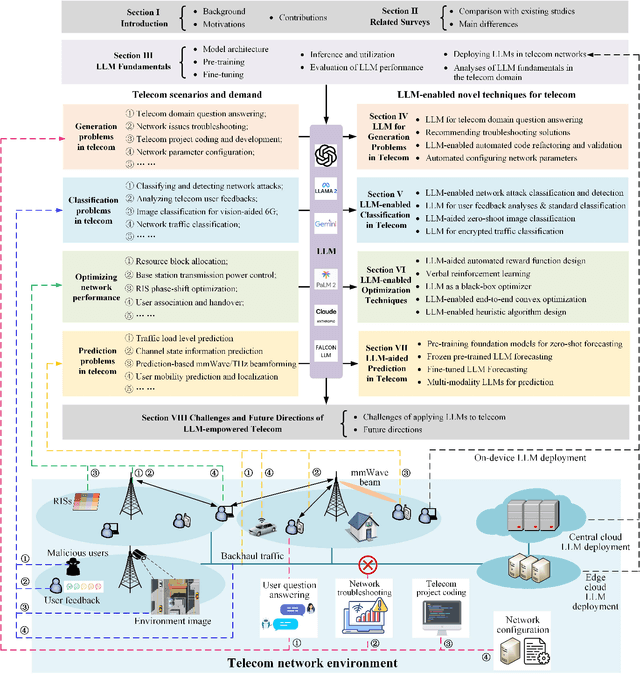
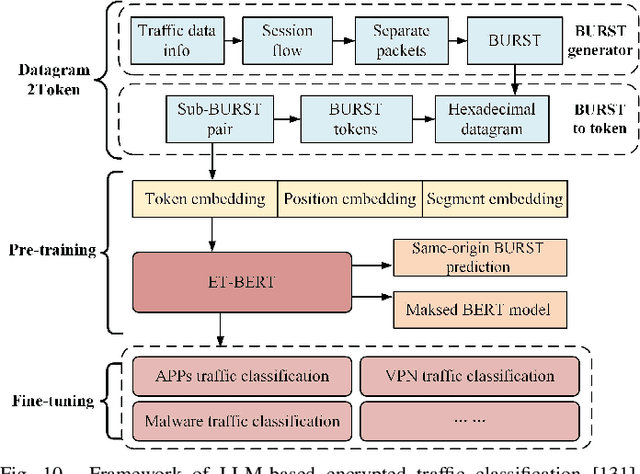
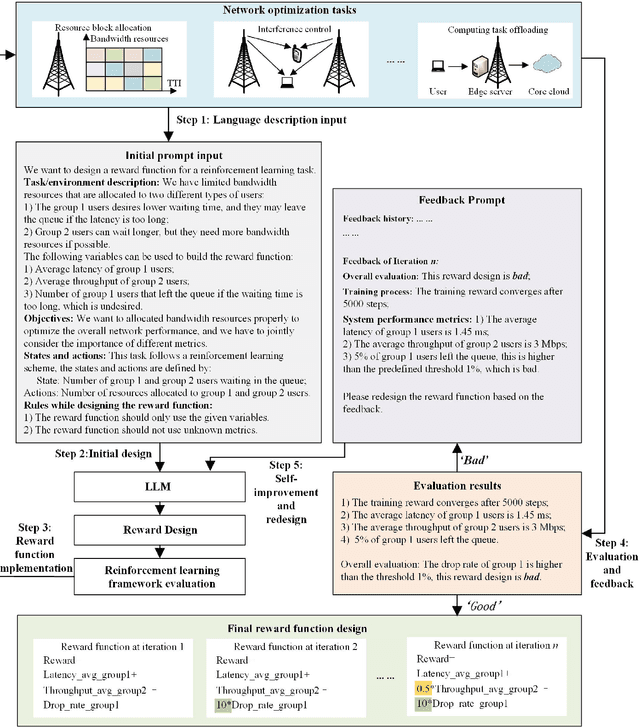
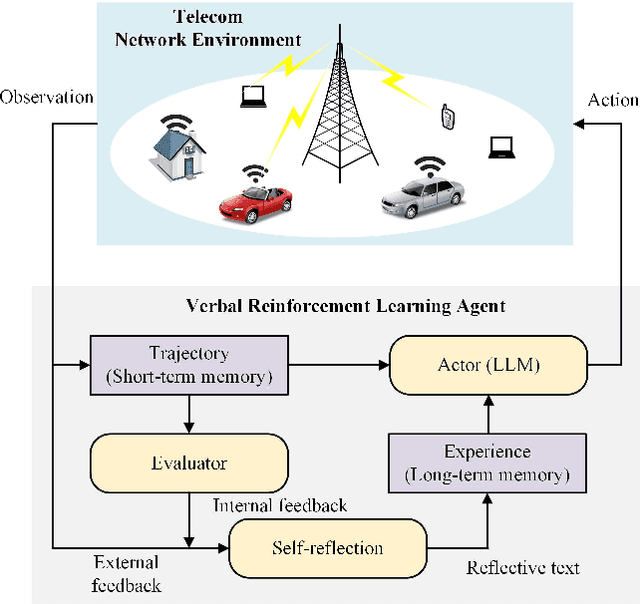
Large language models (LLMs) have received considerable attention recently due to their outstanding comprehension and reasoning capabilities, leading to great progress in many fields. The advancement of LLM techniques also offers promising opportunities to automate many tasks in the telecommunication (telecom) field. After pre-training and fine-tuning, LLMs can perform diverse downstream tasks based on human instructions, paving the way to artificial general intelligence (AGI)-enabled 6G. Given the great potential of LLM technologies, this work aims to provide a comprehensive overview of LLM-enabled telecom networks. In particular, we first present LLM fundamentals, including model architecture, pre-training, fine-tuning, inference and utilization, model evaluation, and telecom deployment. Then, we introduce LLM-enabled key techniques and telecom applications in terms of generation, classification, optimization, and prediction problems. Specifically, the LLM-enabled generation applications include telecom domain knowledge, code, and network configuration generation. After that, the LLM-based classification applications involve network security, text, image, and traffic classification problems. Moreover, multiple LLM-enabled optimization techniques are introduced, such as automated reward function design for reinforcement learning and verbal reinforcement learning. Furthermore, for LLM-aided prediction problems, we discussed time-series prediction models and multi-modality prediction problems for telecom. Finally, we highlight the challenges and identify the future directions of LLM-enabled telecom networks.
Diffusion-based Contrastive Learning for Sequential Recommendation
May 15, 2024



Contrastive learning has been effectively applied to alleviate the data sparsity issue and enhance recommendation performance.The majority of existing methods employ random augmentation to generate augmented views of original sequences. The learning objective then aims to minimize the distance between representations of different views for the same user. However, these random augmentation strategies (e.g., mask or substitution) neglect the semantic consistency of different augmented views for the same user, leading to semantically inconsistent sequences with similar representations. Furthermore, most augmentation methods fail to utilize context information, which is critical for understanding sequence semantics. To address these limitations, we introduce a diffusion-based contrastive learning approach for sequential recommendation. Specifically, given a user sequence, we first select some positions and then leverage context information to guide the generation of alternative items via a guided diffusion model. By repeating this approach, we can get semantically consistent augmented views for the same user, which are used to improve the effectiveness of contrastive learning. To maintain cohesion between the representation spaces of both the diffusion model and the recommendation model, we train the entire framework in an end-to-end fashion with shared item embeddings. Extensive experiments on five benchmark datasets demonstrate the superiority of our proposed method.