 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Model and Document Representation for On-Device Retrieval-Augmented Generation
Apr 15, 2026Traditional Retrieval-Augmented Generation (RAG) approaches generally assume that retrieval and generation occur on powerful servers removed from the end user. While this reduces local hardware constraints, it introduces significant drawbacks: privacy concerns regarding data access, recurring maintenance and storage costs, increased latency, and the necessity of an internet connection. On-device RAG addresses these challenges by executing the entire pipeline locally, making it ideal for querying sensitive personal information such as financial documents, contact details, and medical history. However, on-device deployment necessitates a delicate balance between limited memory and disk space. Specifically, the context size provided to the generative model must be restricted to manage KV cache and attention memory usage, while the size of stored embeddings must be minimized to preserve disk space. In this work, we propose a unified model that compresses the RAG context and utilizes the same representations for retrieval. This approach minimizes disk utilization compared to using separate representations, while significantly reducing the context size required for generation. With an average of 1/10 of the context, our model matches the performance of a traditional RAG reader without increasing storage requirements compared to a multi-vector retrieval model. This approach represents the first model to unify retrieval and context compression using a shared model and representation. We believe this work will inspire further consolidation of distinct models to optimize on-device performance.
Density-based User Representation through Gaussian Process Regression for Multi-interest Personalized Retrieval
Nov 15, 2023Accurate modeling of the diverse and dynamic interests of users remains a significant challenge in the design of personalized recommender systems. Existing user modeling methods, like single-point and multi-point representations, have limitations w.r.t. accuracy, diversity, computational cost, and adaptability. To overcome these deficiencies, we introduce density-based user representations (DURs), a novel model that leverages Gaussian process regression for effective multi-interest recommendation and retrieval. Our approach, GPR4DUR, exploits DURs to capture user interest variability without manual tuning, incorporates uncertainty-awareness, and scales well to large numbers of users. Experiments using real-world offline datasets confirm the adaptability and efficiency of GPR4DUR, while online experiments with simulated users demonstrate its ability to address the exploration-exploitation trade-off by effectively utilizing model uncertainty.
Ever Evolving Evaluator (EV3): Towards Flexible and Reliable Meta-Optimization for Knowledge Distillation
Oct 29, 2023
We introduce EV3, a novel meta-optimization framework designed to efficiently train scalable machine learning models through an intuitive explore-assess-adapt protocol. In each iteration of EV3, we explore various model parameter updates, assess them using pertinent evaluation methods, and adapt the model based on the optimal updates and previous progress history. EV3 offers substantial flexibility without imposing stringent constraints like differentiability on the key objectives relevant to the tasks of interest. Moreover, this protocol welcomes updates with biased gradients and allows for the use of a diversity of losses and optimizers. Additionally, in scenarios with multiple objectives, it can be used to dynamically prioritize tasks. With inspiration drawn from evolutionary algorithms, meta-learning, and neural architecture search, we investigate an application of EV3 to knowledge distillation. Our experimental results illustrate EV3's capability to safely explore model spaces, while hinting at its potential applicability across numerous domains due to its inherent flexibility and adaptability.
Overcoming Prior Misspecification in Online Learning to Rank
Jan 26, 2023The recent literature on online learning to rank (LTR) has established the utility of prior knowledge to Bayesian ranking bandit algorithms. However, a major limitation of existing work is the requirement for the prior used by the algorithm to match the true prior. In this paper, we propose and analyze adaptive algorithms that address this issue and additionally extend these results to the linear and generalized linear models. We also consider scalar relevance feedback on top of click feedback. Moreover, we demonstrate the efficacy of our algorithms using both synthetic and real-world experiments.
IMO$^3$: Interactive Multi-Objective Off-Policy Optimization
Jan 25, 2022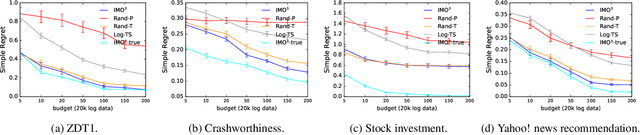
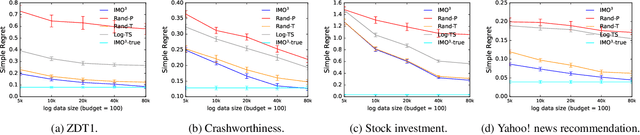
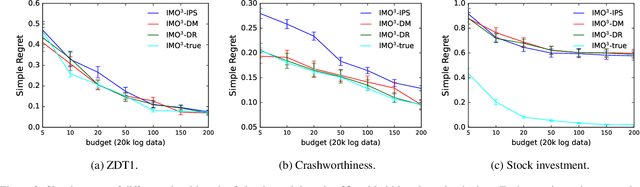
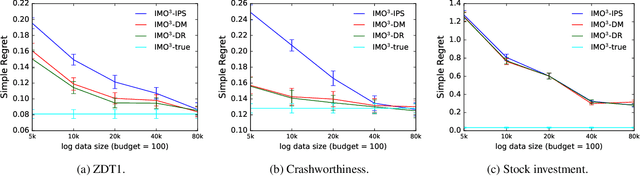
Most real-world optimization problems have multiple objectives. A system designer needs to find a policy that trades off these objectives to reach a desired operating point. This problem has been studied extensively in the setting of known objective functions. We consider a more practical but challenging setting of unknown objective functions. In industry, this problem is mostly approached with online A/B testing, which is often costly and inefficient. As an alternative, we propose interactive multi-objective off-policy optimization (IMO$^3$). The key idea in our approach is to interact with a system designer using policies evaluated in an off-policy fashion to uncover which policy maximizes her unknown utility function. We theoretically show that IMO$^3$ identifies a near-optimal policy with high probability, depending on the amount of feedback from the designer and training data for off-policy estimation. We demonstrate its effectiveness empirically on multiple multi-objective optimization problems.
CORe: Capitalizing On Rewards in Bandit Exploration
Mar 07, 2021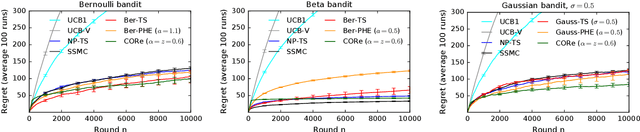
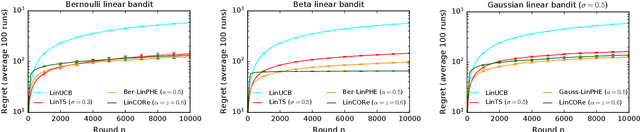
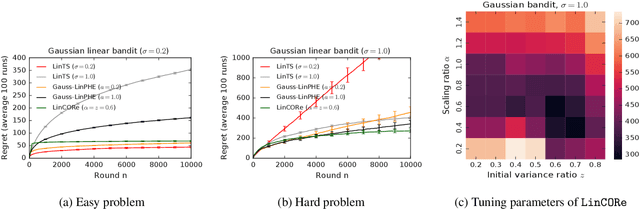

We propose a bandit algorithm that explores purely by randomizing its past observations. In particular, the sufficient optimism in the mean reward estimates is achieved by exploiting the variance in the past observed rewards. We name the algorithm Capitalizing On Rewards (CORe). The algorithm is general and can be easily applied to different bandit settings. The main benefit of CORe is that its exploration is fully data-dependent. It does not rely on any external noise and adapts to different problems without parameter tuning. We derive a $\tilde O(d\sqrt{n\log K})$ gap-free bound on the $n$-round regret of CORe in a stochastic linear bandit, where $d$ is the number of features and $K$ is the number of arms. Extensive empirical evaluation on multiple synthetic and real-world problems demonstrates the effectiveness of CORe.
Separate and Attend in Personal Email Search
Nov 21, 2019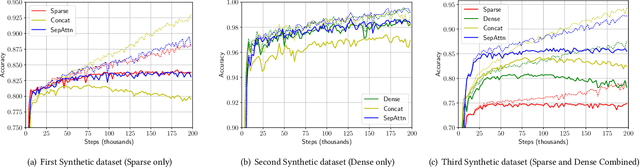

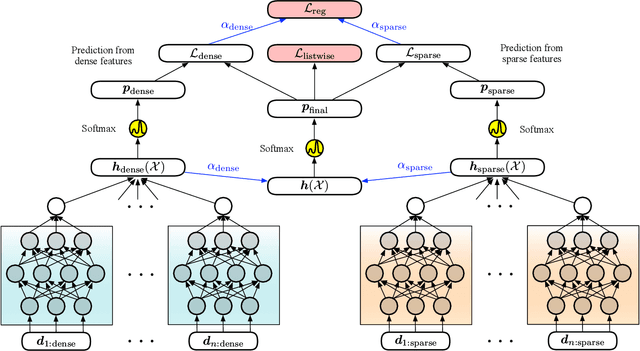
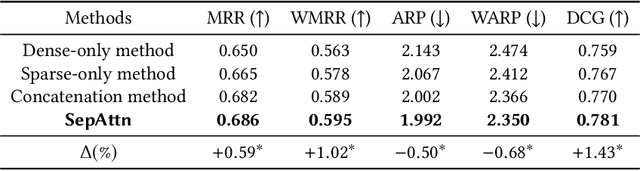
In personal email search, user queries often impose different requirements on different aspects of the retrieved emails. For example, the query "my recent flight to the US" requires emails to be ranked based on both textual contents and recency of the email documents, while other queries such as "medical history" do not impose any constraints on the recency of the email. Recent deep learning-to-rank models for personal email search often directly concatenate dense numerical features (e.g., document age) with embedded sparse features (e.g., n-gram embeddings). In this paper, we first show with a set of experiments on synthetic datasets that direct concatenation of dense and sparse features does not lead to the optimal search performance of deep neural ranking models. To effectively incorporate both sparse and dense email features into personal email search ranking, we propose a novel neural model, SepAttn. SepAttn first builds two separate neural models to learn from sparse and dense features respectively, and then applies an attention mechanism at the prediction level to derive the final prediction from these two models. We conduct a comprehensive set of experiments on a large-scale email search dataset, and demonstrate that our SepAttn model consistently improves the search quality over the baseline models.
Domain Adaptation for Enterprise Email Search
Jun 19, 2019


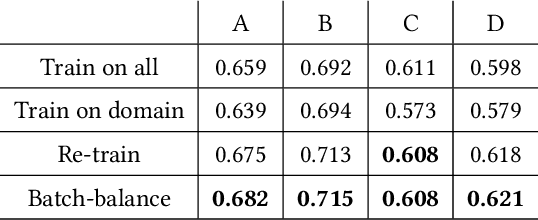
In the enterprise email search setting, the same search engine often powers multiple enterprises from various industries: technology, education, manufacturing, etc. However, using the same global ranking model across different enterprises may result in suboptimal search quality, due to the corpora differences and distinct information needs. On the other hand, training an individual ranking model for each enterprise may be infeasible, especially for smaller institutions with limited data. To address this data challenge, in this paper we propose a domain adaptation approach that fine-tunes the global model to each individual enterprise. In particular, we propose a novel application of the Maximum Mean Discrepancy (MMD) approach to information retrieval, which attempts to bridge the gap between the global data distribution and the data distribution for a given individual enterprise. We conduct a comprehensive set of experiments on a large-scale email search engine, and demonstrate that the MMD approach consistently improves the search quality for multiple individual domains, both in comparison to the global ranking model, as well as several competitive domain adaptation baselines including adversarial learning methods.
* Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval