 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Enterprise Email Search
Jun 19, 2019


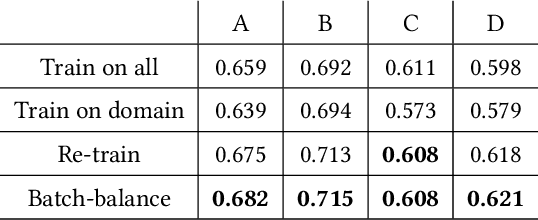
In the enterprise email search setting, the same search engine often powers multiple enterprises from various industries: technology, education, manufacturing, etc. However, using the same global ranking model across different enterprises may result in suboptimal search quality, due to the corpora differences and distinct information needs. On the other hand, training an individual ranking model for each enterprise may be infeasible, especially for smaller institutions with limited data. To address this data challenge, in this paper we propose a domain adaptation approach that fine-tunes the global model to each individual enterprise. In particular, we propose a novel application of the Maximum Mean Discrepancy (MMD) approach to information retrieval, which attempts to bridge the gap between the global data distribution and the data distribution for a given individual enterprise. We conduct a comprehensive set of experiments on a large-scale email search engine, and demonstrate that the MMD approach consistently improves the search quality for multiple individual domains, both in comparison to the global ranking model, as well as several competitive domain adaptation baselines including adversarial learning methods.
* Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval
Computer Vision with a Single (Robust) Classifier
Jun 06, 2019



We show that the basic classification framework alone can be used to tackle some of the most challenging computer vision tasks. In contrast to other state-of-the-art approaches, the toolkit we develop is rather minimal: it uses a single, off-the-shelf classifier for all these tasks. The crux of our approach is that we train this classifier to be adversarially robust. It turns out that adversarial robustness is precisely what we need to directly manipulate salient features of the input. Overall, our findings demonstrate the utility of robustness in the broader machine learning context. Code and models for our experiments can be found at https://git.io/robust-apps.
Learning Perceptually-Aligned Representations via Adversarial Robustness
Jun 03, 2019


Many applications of machine learning require models that are human-aligned, i.e., that make decisions based on human-meaningful information about the input. We identify the pervasive brittleness of deep networks' learned representations as a fundamental barrier to attaining this goal. We then re-cast robust optimization as a tool for enforcing human priors on the features learned by deep neural networks. The resulting robust feature representations turn out to be significantly more aligned with human perception. We leverage these representations to perform input interpolation, feature manipulation, and sensitivity mapping, without any post-processing or human intervention after model training. Our code and models for reproducing these results is available at https://git.io/robust-reps.
Adversarial Examples Are Not Bugs, They Are Features
May 07, 2019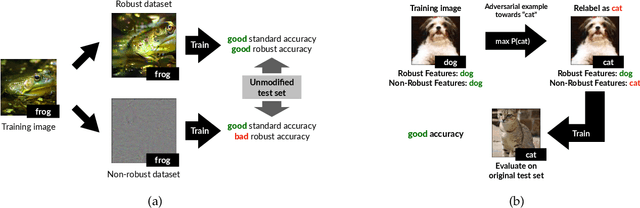

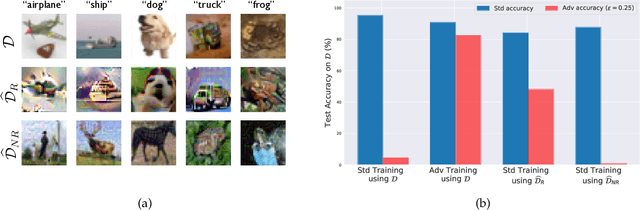

Adversarial examples have attracted significant attention in machine learning, but the reasons for their existence and pervasiveness remain unclear. We demonstrate that adversarial examples can be directly attributed to the presence of non-robust features: features derived from patterns in the data distribution that are highly predictive, yet brittle and incomprehensible to humans. After capturing these features within a theoretical framework, we establish their widespread existence in standard datasets. Finally, we present a simple setting where we can rigorously tie the phenomena we observe in practice to a misalignment between the (human-specified) notion of robustness and the inherent geometry of the data.
Spectral Signatures in Backdoor Attacks
Nov 01, 2018



A recent line of work has uncovered a new form of data poisoning: so-called \emph{backdoor} attacks. These attacks are particularly dangerous because they do not affect a network's behavior on typical, benign data. Rather, the network only deviates from its expected output when triggered by a perturbation planted by an adversary. In this paper, we identify a new property of all known backdoor attacks, which we call \emph{spectral signatures}. This property allows us to utilize tools from robust statistics to thwart the attacks. We demonstrate the efficacy of these signatures in detecting and removing poisoned examples on real image sets and state of the art neural network architectures. We believe that understanding spectral signatures is a crucial first step towards designing ML systems secure against such backdoor attacks
A Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations
Feb 13, 2018
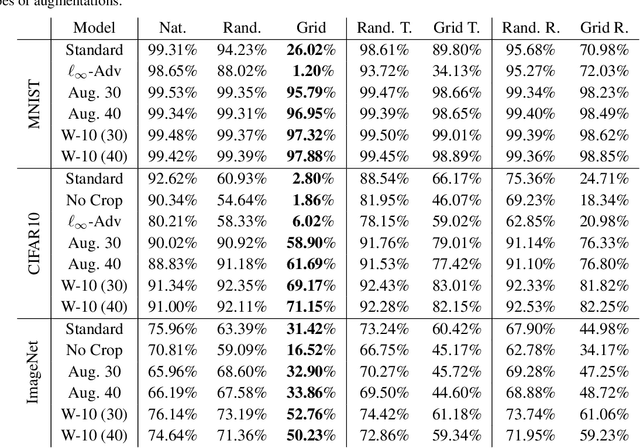
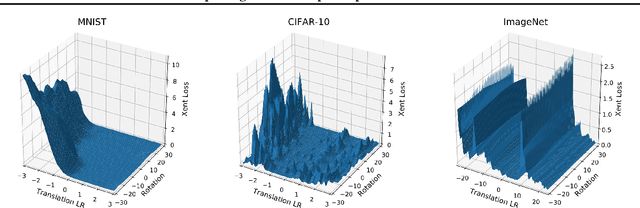
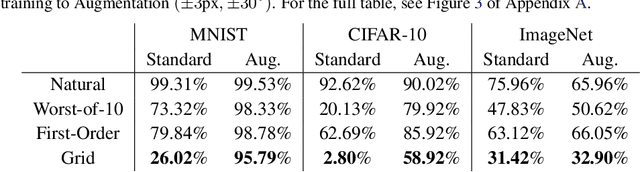
We show that simple transformations, namely translations and rotations alone, are sufficient to fool neural network-based vision models on a significant fraction of inputs. This is in sharp contrast to previous work that relied on more complicated optimization approaches that are unlikely to appear outside of a truly adversarial setting. Moreover, fooling rotations and translations are easy to find and require only a few black-box queries to the target model. Overall, our findings emphasize the need for designing robust classifiers even in natural, benign contexts.