 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimeScore: A Preference-Based Dataset and Framework for Evaluating Anime-Like Speech Style
Mar 12, 2026Evaluating 'anime-like' voices currently relies on costly subjective judgments, yet no standardized objective metric exists. A key challenge is that anime-likeness, unlike naturalness, lacks a shared absolute scale, making conventional Mean Opinion Score (MOS) protocols unreliable. To address this gap, we propose AnimeScore, a preference-based framework for automatic anime-likeness evaluation via pairwise ranking. We collect 15,000 pairwise judgments from 187 evaluators with free-form descriptions, and acoustic analysis reveals that perceived anime-likeness is driven by controlled resonance shaping, prosodic continuity, and deliberate articulation rather than simple heuristics such as high pitch. We show that handcrafted acoustic features reach a 69.3% AUC ceiling, while SSL-based ranking models achieve up to 90.8% AUC, providing a practical metric that can also serve as a reward signal for preference-based optimization of generative speech models.
Separating Oblivious and Adaptive Models of Variable Selection
Feb 18, 2026Sparse recovery is among the most well-studied problems in learning theory and high-dimensional statistics. In this work, we investigate the statistical and computational landscapes of sparse recovery with $\ell_\infty$ error guarantees. This variant of the problem is motivated by \emph{variable selection} tasks, where the goal is to estimate the support of a $k$-sparse signal in $\mathbb{R}^d$. Our main contribution is a provable separation between the \emph{oblivious} (``for each'') and \emph{adaptive} (``for all'') models of $\ell_\infty$ sparse recovery. We show that under an oblivious model, the optimal $\ell_\infty$ error is attainable in near-linear time with $\approx k\log d$ samples, whereas in an adaptive model, $\gtrsim k^2$ samples are necessary for any algorithm to achieve this bound. This establishes a surprising contrast with the standard $\ell_2$ setting, where $\approx k \log d$ samples suffice even for adaptive sparse recovery. We conclude with a preliminary examination of a \emph{partially-adaptive} model, where we show nontrivial variable selection guarantees are possible with $\approx k\log d$ measurements.
Aliasing-Free Neural Audio Synthesis
Dec 23, 2025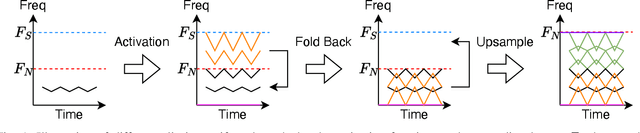
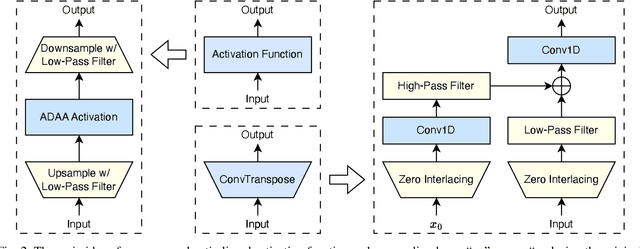
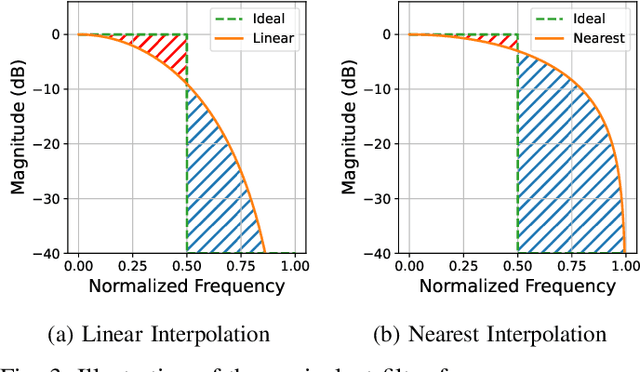
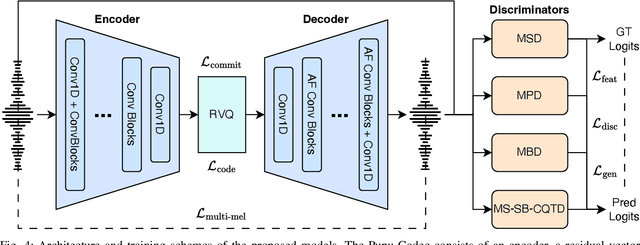
Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
Optimal Inference Schedules for Masked Diffusion Models
Nov 06, 2025A major bottleneck of standard auto-regressive large language models is that their inference process is inherently sequential, resulting in very long and costly inference times. To circumvent this, practitioners proposed a class of language models called diffusion language models, of which the masked diffusion model (MDM) is the most successful. The MDM is able to sample tokens out-of-order and, ostensibly, many tokens at once and in parallel. However, there is very limited rigorous understanding of how much parallel sampling these models can perform without noticeable degradation in their sampling performance. Prior work of Li and Cai obtained some preliminary bounds, but these are not tight for many natural classes of distributions. In this work, we give a new, exact characterization of the expected divergence between the true distribution and the sampled distribution, for any distribution and any unmasking schedule for the sampler, showing an elegant connection to the theory of univariate function approximation. By leveraging this connection, we then attain a number of novel lower and upper bounds for this problem. While the connection to function approximation in principle gives the optimal unmasking schedule for any distribution, we show that it is in general impossible to compete with it without strong a priori knowledge of the distribution, even in seemingly benign settings. However, we also demonstrate new upper bounds and new sampling schedules in terms of well-studied information-theoretic properties of the base distribution, namely, its total correlation and dual total correlation, which show that in some natural settings, one can sample in $O(log n)$ steps without any visible loss in performance, where $n$ is the total sequence length.
Robust Estimation Under Heterogeneous Corruption Rates
Aug 20, 2025We study the problem of robust estimation under heterogeneous corruption rates, where each sample may be independently corrupted with a known but non-identical probability. This setting arises naturally in distributed and federated learning, crowdsourcing, and sensor networks, yet existing robust estimators typically assume uniform or worst-case corruption, ignoring structural heterogeneity. For mean estimation for multivariate bounded distributions and univariate gaussian distributions, we give tight minimax rates for all heterogeneous corruption patterns. For multivariate gaussian mean estimation and linear regression, we establish the minimax rate for squared error up to a factor of $\sqrt{d}$, where $d$ is the dimension. Roughly, our findings suggest that samples beyond a certain corruption threshold may be discarded by the optimal estimators -- this threshold is determined by the empirical distribution of the corruption rates given.
The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains
Jul 08, 2025Improvements in language models are often driven by improving the quality of the data we train them on, which can be limiting when strong supervision is scarce. In this work, we show that paired preference data consisting of individually weak data points can enable gains beyond the strength of each individual data point. We formulate the delta learning hypothesis to explain this phenomenon, positing that the relative quality delta between points suffices to drive learning via preference tuning--even when supervised finetuning on the weak data hurts. We validate our hypothesis in controlled experiments and at scale, where we post-train 8B models on preference data generated by pairing a small 3B model's responses with outputs from an even smaller 1.5B model to create a meaningful delta. Strikingly, on a standard 11-benchmark evaluation suite (MATH, MMLU, etc.), our simple recipe matches the performance of Tulu 3, a state-of-the-art open model tuned from the same base model while relying on much stronger supervisors (e.g., GPT-4o). Thus, delta learning enables simpler and cheaper open recipes for state-of-the-art post-training. To better understand delta learning, we prove in logistic regression that the performance gap between two weak teacher models provides useful signal for improving a stronger student. Overall, our work shows that models can learn surprisingly well from paired data that might typically be considered weak.
S4S: Solving for a Diffusion Model Solver
Feb 24, 2025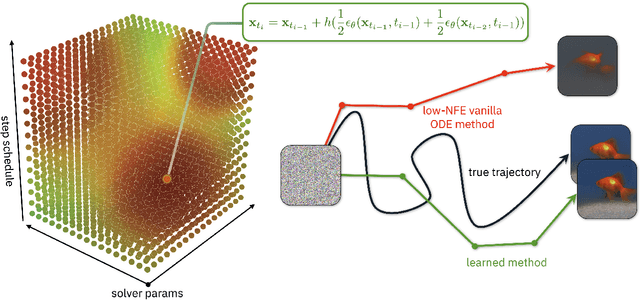


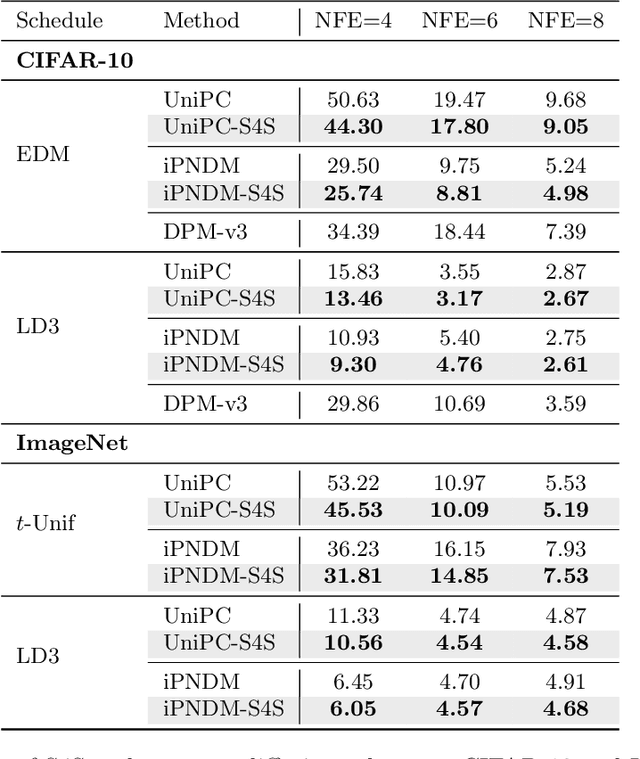
Diffusion models (DMs) create samples from a data distribution by starting from random noise and iteratively solving a reverse-time ordinary differential equation (ODE). Because each step in the iterative solution requires an expensive neural function evaluation (NFE), there has been significant interest in approximately solving these diffusion ODEs with only a few NFEs without modifying the underlying model. However, in the few NFE regime, we observe that tracking the true ODE evolution is fundamentally impossible using traditional ODE solvers. In this work, we propose a new method that learns a good solver for the DM, which we call Solving for the Solver (S4S). S4S directly optimizes a solver to obtain good generation quality by learning to match the output of a strong teacher solver. We evaluate S4S on six different pre-trained DMs, including pixel-space and latent-space DMs for both conditional and unconditional sampling. In all settings, S4S uniformly improves the sample quality relative to traditional ODE solvers. Moreover, our method is lightweight, data-free, and can be plugged in black-box on top of any discretization schedule or architecture to improve performance. Building on top of this, we also propose S4S-Alt, which optimizes both the solver and the discretization schedule. By exploiting the full design space of DM solvers, with 5 NFEs, we achieve an FID of 3.73 on CIFAR10 and 13.26 on MS-COCO, representing a $1.5\times$ improvement over previous training-free ODE methods.
Predicting quantum channels over general product distributions
Sep 05, 2024We investigate the problem of predicting the output behavior of unknown quantum channels. Given query access to an $n$-qubit channel $E$ and an observable $O$, we aim to learn the mapping \begin{equation*} \rho \mapsto \mathrm{Tr}(O E[\rho]) \end{equation*} to within a small error for most $\rho$ sampled from a distribution $D$. Previously, Huang, Chen, and Preskill proved a surprising result that even if $E$ is arbitrary, this task can be solved in time roughly $n^{O(\log(1/\epsilon))}$, where $\epsilon$ is the target prediction error. However, their guarantee applied only to input distributions $D$ invariant under all single-qubit Clifford gates, and their algorithm fails for important cases such as general product distributions over product states $\rho$. In this work, we propose a new approach that achieves accurate prediction over essentially any product distribution $D$, provided it is not "classical" in which case there is a trivial exponential lower bound. Our method employs a "biased Pauli analysis," analogous to classical biased Fourier analysis. Implementing this approach requires overcoming several challenges unique to the quantum setting, including the lack of a basis with appropriate orthogonality properties. The techniques we develop to address these issues may have broader applications in quantum information.
Optimal high-precision shadow estimation
Jul 18, 2024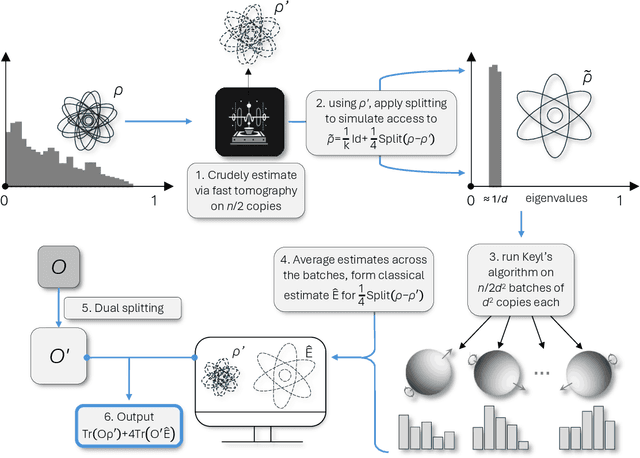
We give the first tight sample complexity bounds for shadow tomography and classical shadows in the regime where the target error is below some sufficiently small inverse polynomial in the dimension of the Hilbert space. Formally we give a protocol that, given any $m\in\mathbb{N}$ and $\epsilon \le O(d^{-12})$, measures $O(\log(m)/\epsilon^2)$ copies of an unknown mixed state $\rho\in\mathbb{C}^{d\times d}$ and outputs a classical description of $\rho$ which can then be used to estimate any collection of $m$ observables to within additive accuracy $\epsilon$. Previously, even for the simpler task of shadow tomography -- where the $m$ observables are known in advance -- the best known rates either scaled benignly but suboptimally in all of $m, d, \epsilon$, or scaled optimally in $\epsilon, m$ but had additional polynomial factors in $d$ for general observables. Intriguingly, we also show via dimensionality reduction, that we can rescale $\epsilon$ and $d$ to reduce to the regime where $\epsilon \le O(d^{-1/2})$. Our algorithm draws upon representation-theoretic tools recently developed in the context of full state tomography.
Black-Box $k$-to-$1$-PCA Reductions: Theory and Applications
Mar 07, 2024The $k$-principal component analysis ($k$-PCA) problem is a fundamental algorithmic primitive that is widely-used in data analysis and dimensionality reduction applications. In statistical settings, the goal of $k$-PCA is to identify a top eigenspace of the covariance matrix of a distribution, which we only have implicit access to via samples. Motivated by these implicit settings, we analyze black-box deflation methods as a framework for designing $k$-PCA algorithms, where we model access to the unknown target matrix via a black-box $1$-PCA oracle which returns an approximate top eigenvector, under two popular notions of approximation. Despite being arguably the most natural reduction-based approach to $k$-PCA algorithm design, such black-box methods, which recursively call a $1$-PCA oracle $k$ times, were previously poorly-understood. Our main contribution is significantly sharper bounds on the approximation parameter degradation of deflation methods for $k$-PCA. For a quadratic form notion of approximation we term ePCA (energy PCA), we show deflation methods suffer no parameter loss. For an alternative well-studied approximation notion we term cPCA (correlation PCA), we tightly characterize the parameter regimes where deflation methods are feasible. Moreover, we show that in all feasible regimes, $k$-cPCA deflation algorithms suffer no asymptotic parameter loss for any constant $k$. We apply our framework to obtain state-of-the-art $k$-PCA algorithms robust to dataset contamination, improving prior work both in sample complexity and approximation quality.